- The paper introduces the Budgeted Stackelberg Equilibrium (BSE), showing that an optimizer can improve utility by time-multiplexing over up to k+1 distinct strategies.
- It proves that PID pacing controllers are non-manipulable, as the optimizer’s total excess gains remain bounded by O(T^(2/3)) under realistic conditions.
- Experimental results match theoretical predictions, demonstrating that optimizer gains are controlled in standard settings but can become nearly linear with heavy low-value distributions.
Learning vs. Optimizing Bidders in Budgeted Auctions: Technical Summary
Introduction and Motivation
This paper addresses strategic interactions in budget-constrained repeated auctions between a learning agent (learner) and a utility-maximizing strategic agent (optimizer), both operating under strict budget caps. Prior research in online learning has thoroughly investigated the optimizer-learner dynamic without budgets, showing that sophisticated learners can block strategic manipulation except up to the Stackelberg value in the stage game. However, these treatments have generally neglected the realistic, cross-round coupling induced by budget limits, which is prevalent in real-world advertising auctions. This work fills that gap by providing a systematic study of Stackelberg-style equilibria where both sides possess budget constraints, leading to altered strategic incentives and equilibrium structures.
Budgeted Stackelberg Equilibrium: Definition and Structural Results
The authors introduce the Budgeted Stackelberg Equilibrium (BSE), generalizing the classic Stackelberg equilibrium to settings with k-dimensional budget constraints. While in the unconstrained Stackelberg setting, repeated play of a single optimal mixed strategy suffices, a constrained optimizer can often do strictly better by time-multiplexing their strategy—cyclically switching among up to k+1 distinct mixed strategies in temporally distinct phases.
Carathéodory's theorem underpins this structural claim: in any BSE with k constraints, it suffices for the optimizer's equilibrium plan to randomize over at most k+1 action-distribution pairs (learner/optimizer strategy pairs). This temporal decomposition expands the optimizer's achievable utility set to the convex hull of the per-round utilities, which can be strictly greater than that achievable by static (single-phase) policies.
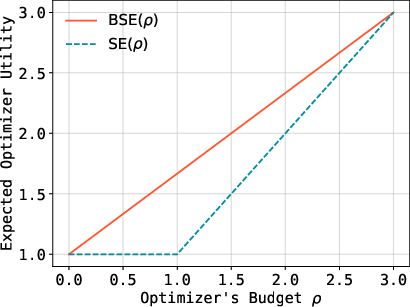
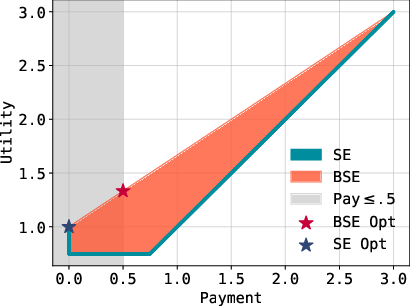
Figure 1: Optimal optimizer value by a single strategy obeying the budget (SE) and two strategies (BSE).
The convexity inherent in the BSE construction is visualized by contrasting the feasible region in Stackelberg equilibrium with the convex-hull extension for budgeted play.
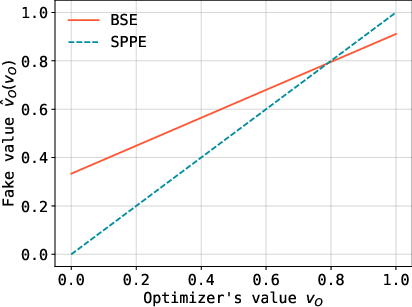
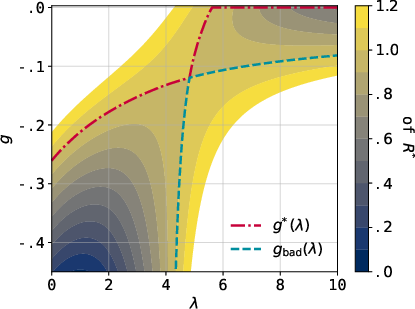
Figure 2: Optimal "fake" value v(⋅) for the SPPE (0.33 optimizer value) and BSE (0.36 optimizer value) in uniform settings. The BSE achieves higher utility.
Non-manipulability of PID-Based Learners
A central question for practical learning algorithms is whether well-known bidding protocols, specifically proportional pacing controllers (the "P" in PID), are robust to optimizer manipulation even under these cross-round budget linkages. The paper rigorously demonstrates that a practical pacing algorithm—where the bid multiplier λ is updated each round by the learner in response to over- or under-spending—prevents the optimizer from extracting more than the BSE value, up to O(T2/3) additive error.
This non-trivial result hinges on analyzing the value the optimizer can extract as the learner's pacing multiplier transitions, showing that any attempt by the optimizer to exploit this adaptation window yields only sublinear excess utility.
Technical Approach and Analysis
The analysis proceeds in two main stages:
- Convex Analysis of BSE: Through geometry and convex programming duality, the optimizer's achievable value is expressed as the supremum over mixtures of best-response points, subject to budget feasibility.
- Lagrangian Relaxation and Adversarial Bounds: The optimizer's problem is recast with Lagrangian relaxation of the budget; the value recursion for the optimizer's maximum total Lagrange reward is developed and upper bounded by Aτ+(1/η)G(λ), where G incorporates a smoothed dual variable over the pacing multiplier. With careful smoothing (to address potential non-Lipschitz points in dual variables) and induction, it's shown that exploitability is controlled and sublinear.
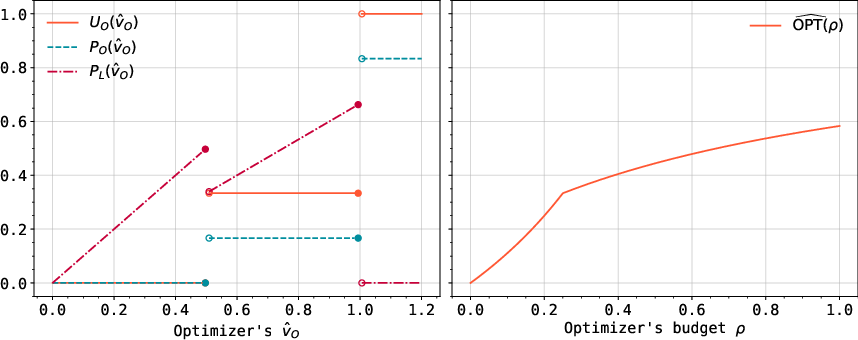
Figure 3: Expected utility/payment functions and learner's payment function for representative value distributions, showing the optimizer's possible moves across strategies.
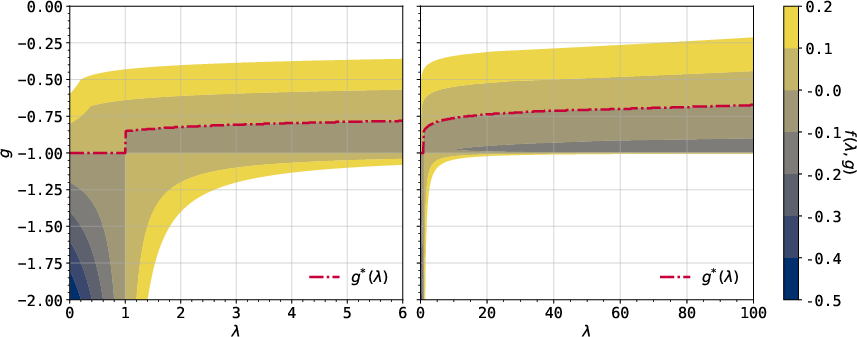
Figure 4: The dual function f(λ,g) of the example illustrating the geometric properties of the optimization landscape.
Main Theoretical Guarantee
For repeated first-price or second-price auctions with bounded value support (away from zero), the PID pacing learner is essentially non-manipulable. That is, the optimizer's total attainable value satisfies:
k+10
Further, the error term can be made explicit in terms of the pacing update parameter k+11.
Impossibility and Lower Bound Examples
The authors construct pathological distributions with heavy mass near zero, showing that without the lower-support bound, the optimizer can gain nearly linear in k+12 excess utility; thus, the distributional assumptions are tight for their main result.
Experimental Illustration
Empirical evaluation matches theoretical predictions: in the well-behaved regime, optimizer excess is sublinear in k+13; but when learners' value distributions place large mass near zero, the optimizer's gain approaches linear with k+14 when switching strategies adaptively.
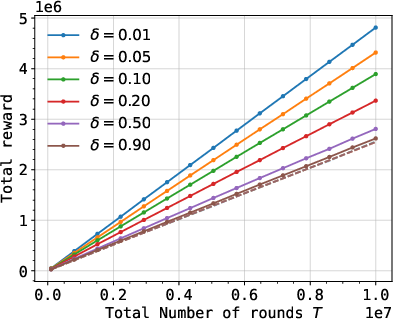
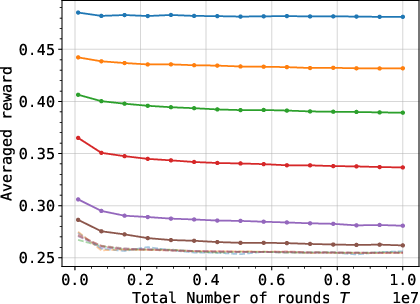
Figure 5: Experimental results demonstrating optimizer's utility growth under different manipulation strategies and value distributions.
Implications and Future Directions
This work establishes that simple, practical pacing controllers, widely used in industry for budget-limited bidding, are provably resistant to sophisticated optimizer manipulation under realistic value distributions, extending strategic robustness guarantees to settings previously believed manipulable. The BSE framework and proof techniques (notably, Lagrangian methods and smoothing of non-regular duals) introduce a toolkit for studying general budgeted learning–strategic agent interactions beyond auctions, including multi-resource and continuous-budget domains.
Further research directions include generalizing non-manipulability guarantees to multidimensional constraints (beyond budgets), nonlinear auction domains, richer information structures, and extending to adversarial non-i.i.d. environments where BSE structure may require new solution concepts.
Conclusion
This paper formalizes and solves the BSE in budgeted repeated auctions, delineates the structure of optimizer strategies in the presence of budgets, and establishes rigorous non-manipulability guarantees for PID-based learning agents under broad conditions. The results provide both theoretical foundations and practical assurance for the deployment of learning algorithms in strategically robust, budget-sensitive auction markets.