- The paper introduces a dual-gradient bidding policy that rigorously analyzes regret in non-stationary, budget-constrained first-price auctions.
- It formulates the auction as an online learning problem using Wasserstein distance to quantify distributional drift and guide bid adjustments.
- Empirical results validate sublinear regret scaling and robustness under both uninformative and plan-informed settings, bridging theory and practice.
Adaptive Bidding in Non-stationary First-Price Auctions under Budget Constraints
Introduction and Motivation
The structure of programmatic advertising markets has undergone a significant paradigm shift from second-price auctions towards first-price auctions (FPAs). This fundamental transition eliminates the dominant-strategy property of truthful bidding and complicates the optimization landscape for budget-constrained bidders. In contrast with the static, Bayesian Nash equilibrium analysis prevalent in classical mechanism design, repeated FPAs with budget limits in non-stationary environments demand online policies that adapt to evolving private value distributions and unpredictable market conditions.
The paper "Adaptive Bidding Policies for First-Price Auctions with Budget Constraints under Non-stationarity" (2604.03103) addresses this gap by formulating the budget-constrained repeated FPA as an online learning problem. A dual-gradient-based bidding policy is proposed, with rigorous regret analysis framed against a dynamic benchmark that incorporates both non-stationarity of bidder valuations and per-round budget allocations. The study extends prior work restricted to second-price mechanisms, stationary environments, or static allocation plans, and introduces optimality guarantees in this high-variance, incomplete-information context.
The focal point is a sequential auction model where a bidder with total budget B engages in T FPA rounds. In round t, the bidder draws a private value vt, observes or predicts the budget allocation for the current round, and then selects a bid xt, facing competition from other bidders whose maximum bid is drawn i.i.d. from an unknown G(⋅). The instantaneous payoff is (vt−xt)1[xt≥mt] with expenditure xt1[xt≥mt], consuming the budget accordingly.
Two scenarios are considered:
- Uninformative Setting: No distributional information about private values over time.
- Informative Setting: The bidder has forecasts or learned predictions about per-period budget allocations (often derived from historical data or planned spend schedules).
The primary performance metric is expected cumulative reward relative to an oracle benchmark with foreknowledge of all stochastic primitives. Regret is defined as the difference between the cumulative reward of the online policy and this dynamic, information-rich benchmark.
Dual-Gradient Descent Algorithm
A Lagrangian dual reformulation is employed to relax the global budget constraint, introducing a non-negative dual variable μ which is adapted online. For every time period, the algorithm estimates μt and T0 based on prior history, then bids
T1
given current private value T2. If the remaining budget suffices, T3 is used; otherwise, the bid is zero. At the end of each round, the realized highest competitor bid T4 is revealed (due to full-information feedback), allowing for stochastic subgradient updates to the dual variable (via T5) and empirical update of T6.
This approach, based on concurrent primal-dual and distributional learning, enables adaptation both to the competitive landscape and to the trajectory of the bidder's own private values.
In the uninformative setting, the performance loss of the algorithm is shown to be bounded by T7 plus a non-stationarity measure:
T8
where T9 captures the cumulative Wasserstein distance between the per-round private value distributions t0 and their average t1. Leveraging Wasserstein distance instead of total variation or KL divergence provides a tighter and more operationally meaningful description of distributional drift, especially in the presence of support shifts (e.g., small value translation incurs small t2 but maximal TV or infinite KL).
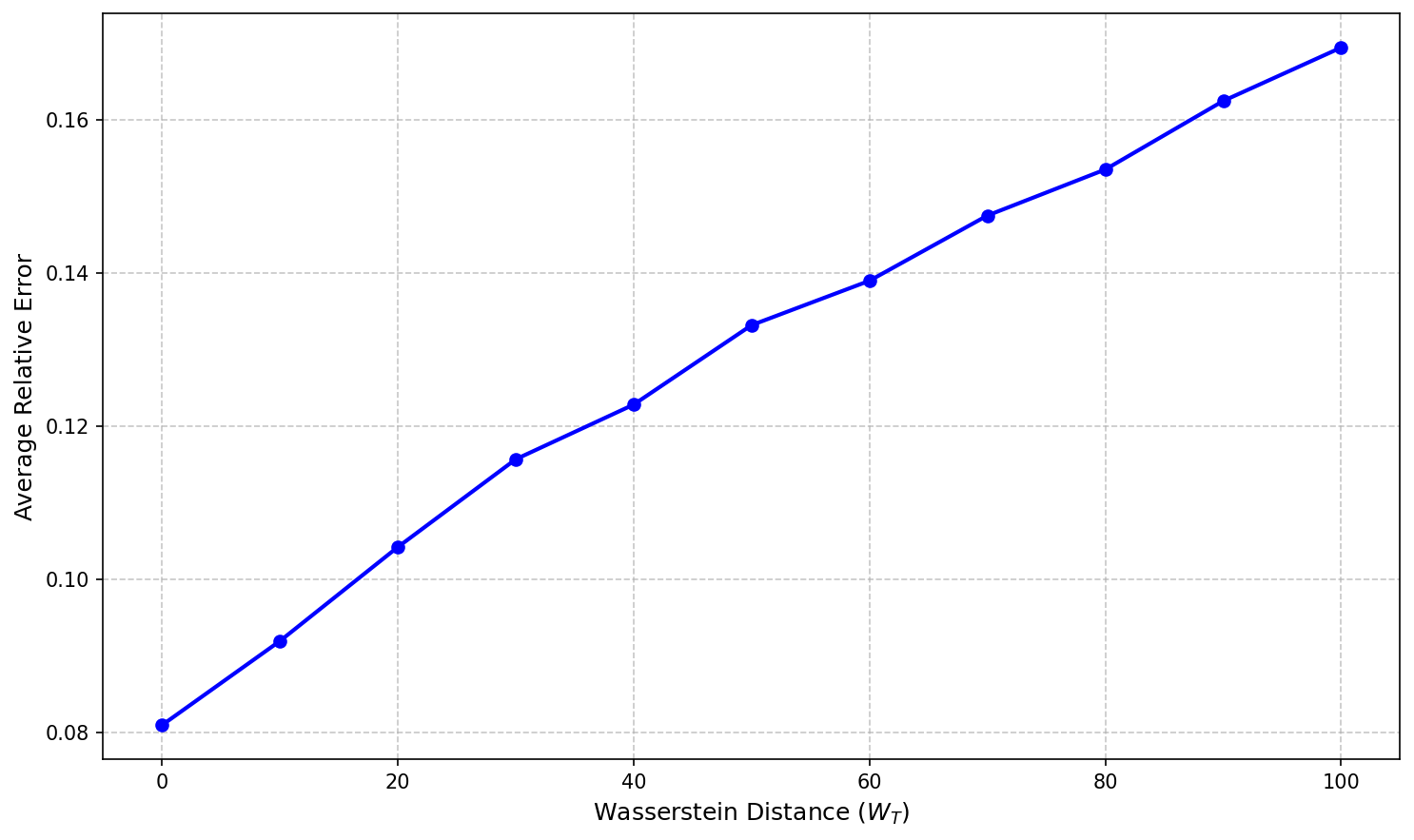
Figure 1: Average relative error as a function of the Wasserstein distance t3, demonstrating linear growth of regret with increasing non-stationarity.
Lower bounds in the paper establish that no online policy—regardless of foreknowledge of t4—can asymptotically improve on t5 regret.
In the informative setting (with access to a budget allocation plan or accurate predictions), the regret bound improves to:
t6
where t7 denotes cumulative deviation between the optimal (unknown) per-period budget t8 and the predicted allocation t9. The dynamic benchmark is thereby tailored to the budget schedule input, and the regret no longer accrues a penalty for distributional non-stationarity when the forecast is accurate.
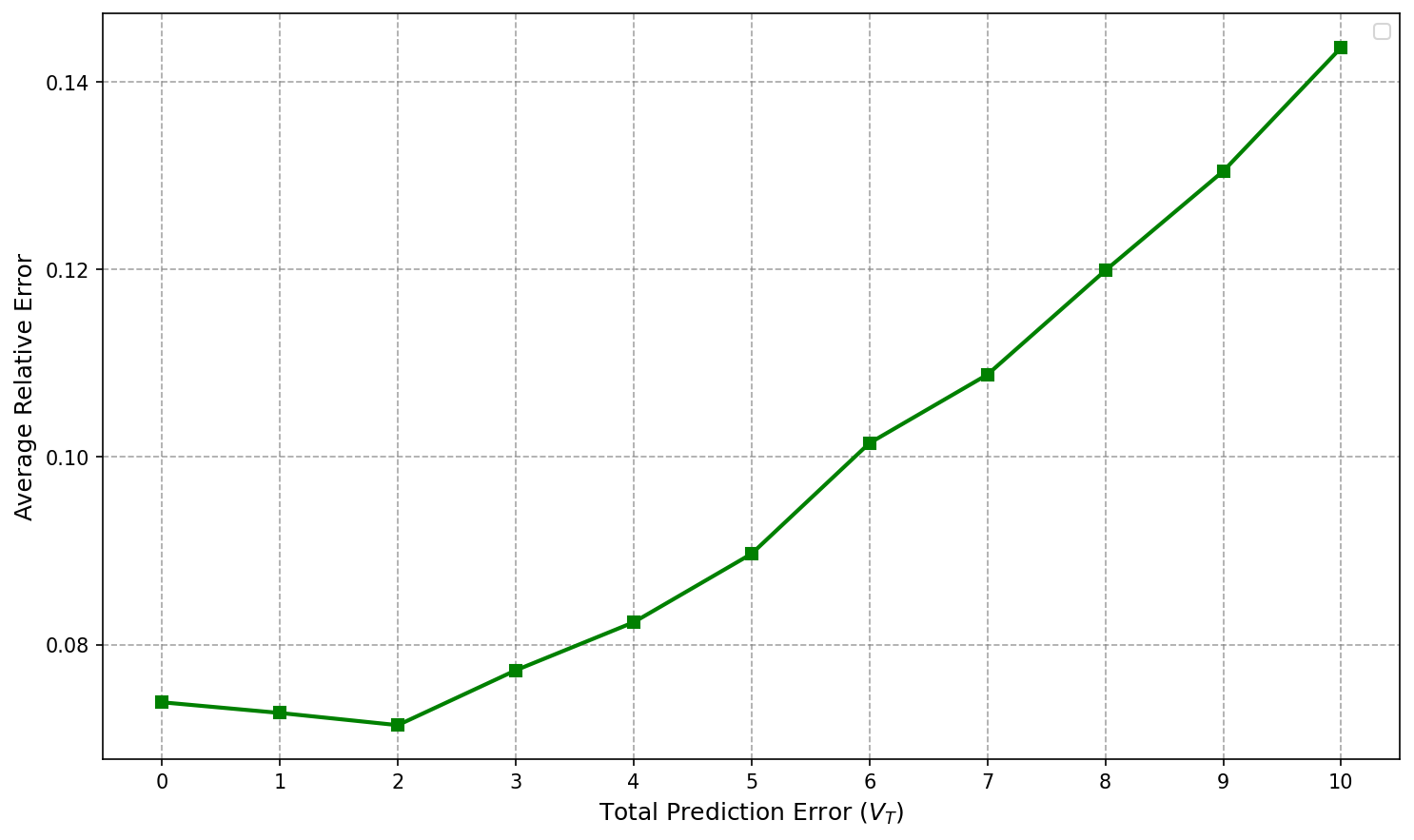
Figure 2: Average relative error increases linearly with prediction error vt0 in the informative setting.
A matching lower bound of vt1 is established, confirming the tightness of these results.
Beyond Global Constraints: Per-Period Budget Allocation
The canonical regret analysis benchmarks only global cumulative budget usage, failing to enforce practical requirements of advertisers to adhere to per-period spend patterns. The paper innovatively introduces a stronger, plan-based benchmark imposing per-time expected expenditure constraints, reflecting operational realities in campaign execution and platform contracts.
The new regret bound with respect to this per-period benchmark becomes:
vt2
removing dependency on both vt3 and vt4. Additional analysis covers robustness: if the plan benchmark itself is allowed an additive violation vt5 in each period, regret degrades only additively in vt6, ensuring graceful degradation under misspecification or exception handling.
This benchmarking framework allows authors to clearly disentangle sources of regret: those attributable to inability to track optimal spending and those from model misspecification or operational plan deviations.
Empirical Validation
Simulations confirm the theoretical findings:
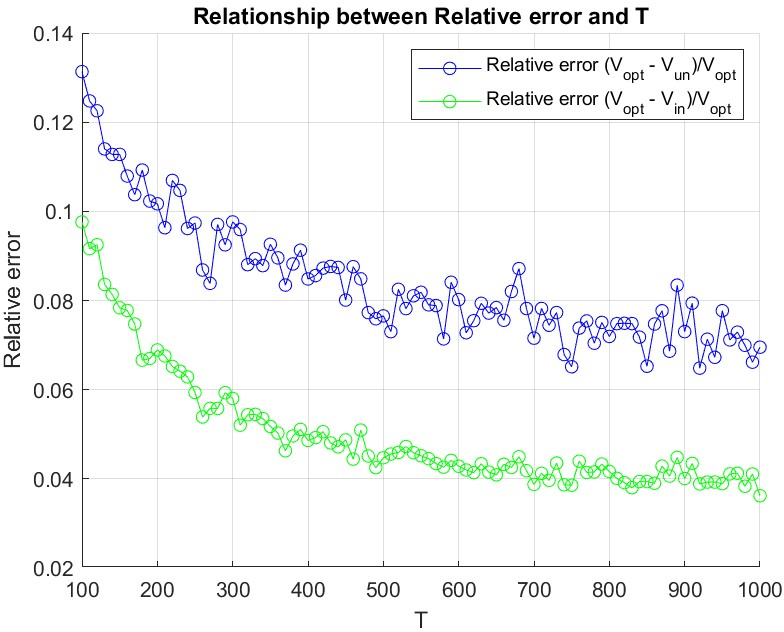
Figure 3: The average relative error decays toward zero as the time horizon vt7 increases, evidencing the sublinear regret rate.
- Under increased non-stationarity (vt8), relative regret grows linearly in the uninformative case (see Figure 1).
- With increasing prediction error in budget allocation (vt9), regret likewise grows linearly in the informative setting (see Figure 2).
- Both algorithms' relative error vanishes as xt0 grows, validating sublinear regret scaling and practical efficacy for large campaigns.
Implications and Future Directions
The dual-gradient-based adaptive algorithm in this work achieves order-optimal regret in the most adverse (non-stationary, minimally informative) settings and exhibits tangible improvement when informed predictions or plan-based discipline are available. The usage of Wasserstein distance as a non-stationarity metric is a notable methodological contribution, bringing sharper controls to non-i.i.d. stochastic environments.
From a practical perspective, this framework provides a robust, efficient policy foundation for real-world DSPs managing campaigns over unpredictable auction environments, with minimal tuning or statistical assumptions. The plan-based regret analysis bridges theoretical guarantees and operational spending requirements.
Potential extensions involve generalizing feedback models beyond full information (e.g., censored outcomes), incorporating multiple strategic agents with equilibrial learning, and integrating historical data-driven budget allocation prediction with online learning guarantees. Realizing these may require new methods spanning adversarial online learning, contextual bandits with knapsacks, and stochastic mirror descent under resource constraints.
Conclusion
This paper establishes a comprehensive theory and practical methodology for adaptive bidding in repeated, budget-constrained FPAs under non-stationary and informationally incomplete settings (2604.03103). The dual-gradient approach achieves minimax-optimal regret rates in both uninformed and plan-informed regimes, with rigorous robustness to distributional shifts and allocation forecast errors. The results substantiate the applicability of these algorithms to contemporary advertising systems and open multiple avenues for further research in online decision-making under resource and non-stationarity constraints.

