MegaStyle: Constructing Diverse and Scalable Style Dataset via Consistent Text-to-Image Style Mapping
Abstract: In this paper, we introduce MegaStyle, a novel and scalable data curation pipeline that constructs an intra-style consistent, inter-style diverse and high-quality style dataset. We achieve this by leveraging the consistent text-to-image style mapping capability of current large generative models, which can generate images in the same style from a given style description. Building on this foundation, we curate a diverse and balanced prompt gallery with 170K style prompts and 400K content prompts, and generate a large-scale style dataset MegaStyle-1.4M via content-style prompt combinations. With MegaStyle-1.4M, we propose style-supervised contrastive learning to fine-tune a style encoder MegaStyle-Encoder for extracting expressive, style-specific representations, and we also train a FLUX-based style transfer model MegaStyle-FLUX. Extensive experiments demonstrate the importance of maintaining intra-style consistency, inter-style diversity and high-quality for style dataset, as well as the effectiveness of the proposed MegaStyle-1.4M. Moreover, when trained on MegaStyle-1.4M, MegaStyle-Encoder and MegaStyle-FLUX provide reliable style similarity measurement and generalizable style transfer, making a significant contribution to the style transfer community. More results are available at our project website https://jeoyal.github.io/MegaStyle/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MegaStyle: A simple explanation
What is this paper about?
This paper is about making computers better at “style transfer.” That’s when you take the content of one image (say, a photo of a cat) and make it look like it was created in a particular artistic style (like watercolor or 3D clay). The authors build a huge, high‑quality style dataset and two tools that use it:
- a style “detector” that can tell how similar two images are in style, and
- a style transfer model that can apply a chosen style to any content more accurately.
What questions did the researchers want to answer?
The team focused on three simple questions:
- How can we build a large, clean, and varied dataset of image styles that’s actually useful for training?
- Can we train a model to measure how similar two images are in style, not just in subject or meaning?
- Can we train a style transfer model that works reliably across many different styles and contents, without copying content from the reference image?
How did they do it?
Think of style as the “look and feel” (colors, textures, brushstrokes, lighting) and content as the “what” (a dog, a city, a mountain).
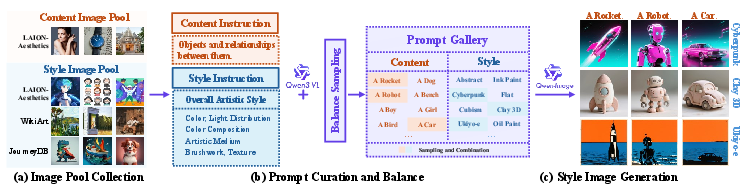
The authors noticed that modern text‑to‑image generators (like Qwen‑Image) are very good at following style descriptions (“ink wash painting,” “flat comic shading,” “neon cyberpunk lighting”). If you keep the style description the same but change the content description, the generator can produce many images that share the same style but show different things. This is exactly what’s needed to teach models what “style” is, independently from “content.”
Here’s their approach, in everyday terms:
- They built two big “word banks” (prompt galleries):
- Style prompts: short descriptions of how an image should look (e.g., color palette, texture, medium, brushwork).
- Content prompts: short descriptions of what’s in the image (e.g., “a lighthouse on a cliff,” “a cat sleeping on a sofa”).
- They started from millions of real images collected from public sources and used a vision‑LLM (a smart captioner) to write clear style and content descriptions for them, carefully removing duplicates and balancing topics so there isn’t too much of any one style or subject.
- They mixed many style prompts with many different content prompts and used a text‑to‑image model to generate pairs of images that share the same style but have different content. This gave them a large dataset called MegaStyle‑1.4M (about 1.4 million images).
Two key ideas explained simply:
- Intra‑style consistency: Within one style (say, “pastel chalk”), all images should really look like that style, even if one shows a car and another shows a tree.
- Inter‑style diversity: The dataset should include lots of different styles overall (not just “oil painting” over and over).
Then they trained two models:
- MegaStyle‑Encoder: a “style detector” that learns to place images with the same style close together and different styles far apart. They used a technique called contrastive learning—think of it like organizing a closet: pull matching outfits together and push different outfits apart, so you can quickly find what matches.
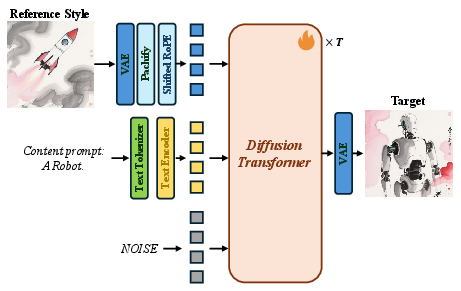
- MegaStyle‑FLUX: a style transfer model built on a powerful image generator. During training, they show it two images with the same style but different content. One acts as the “reference style,” the other is the “target look,” and the model learns to recreate that look on a new content description. They also use a careful trick to prevent the model from copying the actual objects from the style image (avoiding “content leakage”) and instead copy only the style.
What did they find, and why is it important?
- Better dataset quality matters a lot: Because their dataset keeps style consistent within each pair and includes many different styles overall, models trained on it learn style more cleanly and generalize better.
- Stronger style detector: Their MegaStyle‑Encoder was much better at finding images with the same style than popular baselines (like CLIP‑based methods). In tests, it focused on style rather than content, which is exactly what you want for style similarity.
- More reliable style transfer: Their MegaStyle‑FLUX model produced images that matched both the desired style and the text description of the content more faithfully than several leading methods. It didn’t just mimic colors; it captured deeper things like texture, brushwork, lighting, and medium.
- Human preferences agreed: In user studies, people preferred the outputs from their system more often, both for matching the style and matching the described content.
Why does this work matter?
- Better creative tools: Apps that add “filters” or stylize photos could become more accurate and diverse, making it easier for creators to get the exact look they want.
- Faster searching by style: The style detector can help you find images that match a certain look, even when the subjects are different.
- Stronger research foundation: A clean, scalable style dataset lets researchers build and test new ideas about style, making future tools more reliable. The authors’ pipeline can also grow to much larger scales.
Final takeaway
By using consistent style descriptions and smart pairing of style and content, the authors built a huge, balanced dataset and trained models that understand “style” much better. This leads to more faithful style transfer and better style similarity measurement—useful for art, design, and any tool that changes how images look without changing what they show. The team plans to refine style descriptions further and scale the dataset even more, aiming for tens of millions of examples.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Reliance on a single T2I model (Qwen-Image) for dataset generation and key assumptions (consistent style mapping) is untested across other generators (e.g., SDXL, Imagen, MJ, DALL·E); cross-model reproducibility and sensitivity are not evaluated.
- No quantitative verification of “intra-style consistency” across seeds, contents, and prompt perturbations; variance/dispersion metrics within styles are absent.
- The prompt curation balance is done with text embeddings (mpnet), not validated to correlate with visual style diversity; effectiveness of the clustering strategy for visual style coverage remains unmeasured.
- The style taxonomy is implicit and noisy (VLM-generated), with no formal ontology or multi-attribute labeling (e.g., color, light, texture, brushwork) to support interpretable, disentangled style representation learning.
- VLM style prompts can be vague/underspecified (acknowledged by authors), but the extent of label noise and its impact on encoder/model performance is not quantified; no human audit of prompt quality is reported.
- Dataset composition and per-style sampling are under-specified (e.g., number of images per style, tail distribution); residual class imbalance after “balanced sampling” is not characterized.
- The dataset is almost entirely synthetic; generalization to real artworks and challenging, subtle styles is only lightly tested (small StyleBench subset) and not systematically analyzed.
- The use of MegaStyle-Encoder both as a trained component and as the primary style metric introduces evaluation circularity; outcomes may be inflated for methods aligned with this feature space.
- Source-model bias persists in evaluation: StyleRetrieval is generated by the same model (Qwen-Image) used for training; while additional benchmarks are included, a standardized, human-annotated, model-agnostic style-similarity benchmark is still lacking.
- Human study details (sample size, protocol, annotator expertise, inter-rater reliability) are missing, limiting interpretability and reproducibility of human preference results.
- Robustness of MegaStyle-FLUX to mixed/multi-reference styles, style interpolation, and style-strength control is not explored.
- Ablations on the style-conditioning design (e.g., shifted RoPE, token concatenation strategy, conditioning location/weight) are not reported; it remains unclear which components reduce content leakage and why.
- Generalization across content domains (e.g., highly photorealistic vs. abstract scenes; dense scenes vs. simple objects) and failure cases for style transfer are not systematically studied.
- Sampling strategy for scaling from the 68B theoretical content–style combinations to the 1.4M generated subset is not specified; selection criteria and coverage guarantees are unclear.
- Quality control for generated images (artifact detection, NSFW filtering, failure shot curation) is not described; downstream effects of artifacts on training/evaluation are unknown.
- Ethical and legal considerations of style reproduction (artist rights, potential mimicry harms) and of training on LAION/JourneyDB assets are not addressed; dataset licensing and redistribution permissions are unspecified.
- Compute budget, training time, and hardware details for MegaStyle-Encoder and MegaStyle-FLUX are not provided, hindering reproducibility and resource planning.
- Cross-metric validation is limited to CLIP text scores and MegaStyle-Encoder style similarity; alternative, semantically disentangled or perceptual metrics (e.g., human-anchored pairwise judgments, psychophysical tests) are not used.
- Impact of design choices in SSCL (batch size 8,192, temperature τ, negative sampling strategy) on learned style specificity and robustness is not ablated.
- The approach does not disentangle or regress independent style factors; learning interpretable axes (color palette, illumination, medium, texture, stroke) for controllable editing remains an open direction.
- The pipeline assumes English prompts; multilingual prompt robustness and cross-lingual style mapping consistency are not evaluated.
- Extension to video (temporal style consistency), 3D assets, or cross-modal style transfer is not discussed despite citing video-related works.
Practical Applications
Immediate Applications
Below are actionable ways to deploy MegaStyle’s dataset (MegaStyle-1.4M), style encoder (MegaStyle-Encoder), and style transfer model (MegaStyle-FLUX) today across sectors, with suggested tools/workflows and feasibility notes.
- Creative software (design, photo/video tools)
- Use case: Style-aware search, tagging, and deduplication of assets.
- Sector: Software, media/entertainment.
- Tools/workflows: Integrate MegaStyle-Encoder into a vector database (e.g., FAISS/Milvus) for “find visually similar styles”; cluster catalogs by style; add “style dedupe” to asset ingestion.
- Assumptions/dependencies: Access to MegaStyle-Encoder weights; sufficient GPU/CPU for batch embeddings; catalog rights and privacy compliance.
- Brand and marketing asset QA
- Use case: Automated brand-style linting for campaigns (flag off-brand colors/brushwork/medium).
- Sector: Advertising/marketing, enterprise software.
- Tools/workflows: Compute style embeddings of brand guidelines (canonical reference images); compare to campaign deliverables via MegaStyle-Encoder; set thresholds for pass/fail; integrate into CMS/build pipelines.
- Assumptions/dependencies: Clear reference style sets; careful threshold calibration to avoid false positives; legal review for automated enforcement.
- Batch style transfer at scale for campaigns
- Use case: Generate consistent campaign visuals across product shots and locales.
- Sector: E‑commerce, advertising.
- Tools/workflows: Curate content prompts; select or retrieve brand style via MegaStyle-Encoder; run MegaStyle-FLUX on content–style combinations; A/B test variants; ship approved variants.
- Assumptions/dependencies: Rights to apply stylization to inputs; content safety controls; GPU capacity for inference.
- Stock media and marketplace curation
- Use case: Style-centric browsing and discovery for stock images, illustrations, and icons.
- Sector: Media marketplaces.
- Tools/workflows: Index catalog with MegaStyle-Encoder embeddings; expose “style facets” and style recommendations; cluster collections by fine-grained styles.
- Assumptions/dependencies: Marketplace license compatibility; scalable indexing storage.
- Creative pipelines in games and animation
- Use case: Harmonize disparate concept art styles; re-style assets to a target look.
- Sector: Gaming, animation/VFX.
- Tools/workflows: Internal “style registry” with embeddings; automated checks for style continuity across assets; apply MegaStyle-FLUX to re-render placeholders into production style.
- Assumptions/dependencies: FLUX-compatible asset preparation (image-based workflows); integration with DCC tools (Blender, Photoshop).
- Product photography and catalog standardization
- Use case: Style-consistent product imagery across categories and seasons.
- Sector: Retail/e‑commerce.
- Tools/workflows: Encode seasonal look (e.g., “matte pastel watercolor”); stylize all catalog shots via MegaStyle-FLUX; monitor consistency via MegaStyle-Encoder.
- Assumptions/dependencies: Legal clarity on modifications; robust color management for print/on-screen consistency.
- Social media and mobile filters
- Use case: On-device or cloud-backed style filters that capture nuanced texture/brushwork, not just color.
- Sector: Consumer apps.
- Tools/workflows: Prune MegaStyle-FLUX for mobile (distillation/quantization); provide user-selectable styles encoded via prompts or reference images.
- Assumptions/dependencies: Device constraints; latency budgets; safety/NSFW gating.
- Academic benchmarking and evaluation
- Use case: Standardized style retrieval and transfer benchmarks.
- Sector: Academia.
- Tools/workflows: Adopt MegaStyle-1.4M subsets for supervised/contrastive evaluation; use MegaStyle-Encoder as a style metric; publish reproducible protocols and leaderboards.
- Assumptions/dependencies: Clear licenses for academic use; community agreement on metric validity.
- Museum/education style exploration
- Use case: Interactive exploration of art movements and fine-grained stylistic features.
- Sector: Education, cultural heritage.
- Tools/workflows: Build “style explorer” that retrieves related works by brushwork/texture/light from digitized collections; generate didactic visuals by re-stylizing neutral content via MegaStyle-FLUX.
- Assumptions/dependencies: Institutional permissions; cultural sensitivity regarding stylistic appropriation.
- Regression testing for style features in production
- Use case: CI/CD tests for style transfer products to detect regressions in style fidelity.
- Sector: Software quality engineering.
- Tools/workflows: Maintain a test suite of reference style/content pairs; compute style cosine similarity in MegaStyle-Encoder space; set release-gate thresholds.
- Assumptions/dependencies: Stable hardware/software environment; maintaining representative test sets.
Long-Term Applications
The following opportunities require additional research, scaling, or engineering—e.g., extending to video/3D, building industry standards, or integrating with enterprise systems.
- Video and sequence-level style transfer
- Use case: Temporally consistent stylization of videos, animation frames, or game cutscenes.
- Sector: Media/entertainment, social video platforms.
- Tools/workflows: Extend MegaStyle-FLUX with temporal modules; curate a “MegaStyle-Video” dataset (content–style prompts for sequences); add temporal consistency losses and evaluation.
- Assumptions/dependencies: Large-scale video curation; motion-aware architectures; compute for training/inference.
- Cross-modal “style token” for design systems
- Use case: A unified style embedding that spans images, video, 3D assets, and UI themes.
- Sector: Design systems, software tooling.
- Tools/workflows: Train multi-modal encoders aligned to MegaStyle-Encoder; expose “style tokens” similarly to color/typography tokens; integrate into Figma/DesignOps.
- Assumptions/dependencies: Cross-modal datasets with consistent style labels; industry adoption of a style token spec.
- Domain generalization and robustness via style augmentation
- Use case: Improve computer vision robustness (detection/segmentation) by augmenting training data with diverse styles.
- Sector: Autonomous systems, retail vision, medical imaging (with caution).
- Tools/workflows: Use MegaStyle-FLUX to style-augment labeled datasets; evaluate cross-domain performance gains.
- Assumptions/dependencies: Careful validation to avoid distribution shift harms; regulatory constraints in safety-critical domains.
- Copyright/compliance support and provenance signals
- Use case: Risk scoring for stylization proximity to specific protected references; provenance tracking for stylized assets.
- Sector: Legal/compliance, public sector communications.
- Tools/workflows: Use MegaStyle-Encoder to measure proximity to curated high-risk reference sets; integrate C2PA provenance or watermarking for generated assets.
- Assumptions/dependencies: Legal nuance (style itself is typically not copyrightable); high false-positive risk; governance frameworks needed.
- Public standards for style metrics and benchmarks
- Use case: Establish a community-agreed metric for style similarity and public leaderboards.
- Sector: Standards bodies, research consortia.
- Tools/workflows: Formalize datasets (train/test splits), metrics (MegaStyle-Encoder or successors), and reporting protocols; periodic benchmark updates to avoid overfitting.
- Assumptions/dependencies: Broad stakeholder participation; transparent governance; open licensing.
- Brand “copilot” for dynamic creative optimization
- Use case: Real-time style adaptation to audience segments while enforcing brand constraints.
- Sector: MarTech/AdTech.
- Tools/workflows: Retrieve permissible brand styles via embeddings; dynamically generate stylized variants with MegaStyle-FLUX; run multi-armed bandits for performance optimization.
- Assumptions/dependencies: Privacy-compliant feedback loops; latency-aware deployment; brand policy acceptance.
- Interior/fashion/material design simulation
- Use case: Cross-material style transfers (e.g., textile patterns to furniture or 3D assets) and photorealistic mockups.
- Sector: Manufacturing, retail, AR/VR.
- Tools/workflows: Extend dataset and model to material and 3D domains; integrate PBR/material descriptors into prompts; couple with 3D renderers.
- Assumptions/dependencies: Multi-modal data acquisition; physics-aware rendering constraints.
- Training data engines for style-constrained content creation
- Use case: Large-scale synthetic data generation for brand or platform-specific styles to bootstrap downstream models (captioning, ranking).
- Sector: Platforms, recommendation engines.
- Tools/workflows: Programmatic prompt generation; feedback loops that score style alignment with MegaStyle-Encoder; distill “house style” foundation models.
- Assumptions/dependencies: Guardrails for bias/representation balance; compute budgets and storage.
- Ethics and cultural stewardship in style datasets
- Use case: Operationalize consent, attribution, and cultural sensitivity in style data curation.
- Sector: Policy, cultural institutions.
- Tools/workflows: Dataset governance checklists; opt-out/opt-in registries; style descriptors co-designed with communities.
- Assumptions/dependencies: Institutional coordination; evolving legal frameworks; multilingual descriptors.
- Robotics and digital fabrication for stylized outputs
- Use case: Translate style embeddings to control policies for robotic painting/printing.
- Sector: Robotics, fabrication.
- Tools/workflows: Map MegaStyle-Encoder features to control primitives (stroke density, pressure, color mixing); closed-loop optimization with vision feedback.
- Assumptions/dependencies: High-fidelity sensing/actuation; dedicated datasets linking style to actuation parameters.
Cross-cutting assumptions and dependencies
- Reliance on upstream models: The pipeline depends on consistent text-to-image mapping (e.g., Qwen-Image), strong VLM captioning (e.g., Qwen3‑VL), and a FLUX backbone; changes to these models may affect reproducibility and quality.
- Licensing and rights: Use of JourneyDB, WikiArt, and LAION-Aesthetics sources requires careful licensing review; commercial deployments may need alternative sources or rights clearance.
- Bias and coverage: Style distribution reflects internet/Midjourney/LAION biases; underrepresented cultural styles may need targeted curation.
- Compute and cost: Training and large-scale inference require GPU capacity; mobile use needs model distillation/quantization.
- Safety and moderation: Stylization workflows should include content filtering and sensitive-style handling (e.g., NSFW, cultural symbols).
- Metric validity: MegaStyle-Encoder improves style similarity measurement but is not a legal or ethical arbiter; thresholds must be tuned for each application.
Glossary
- Ablation studies: Systematic experiments that remove or alter components to assess their contribution to performance. "ablation studies confirm the effectiveness and advantages of our framework"
- ArtFID: A metric that measures distribution distance between sets of images for assessing artistic style similarity. "FID \cite{heusel2017gans} and ArtFID \cite{wright2022artfid} calculate the distribution distance to measure the global style similarity between two style image sets."
- Attention-Distillation (Attn-Distill): A method that transfers attention patterns from one model to another to guide generation or editing. "Attention-Distillation (Attn-Distill) \cite{zhou2025attention}"
- B-LoRA: A technique leveraging Low-Rank Adaptation (LoRA) combinations for style and content to synthesize images. "generates 210K stylized images via B-LoRA \cite{frenkel2024implicit}."
- Balance sampling algorithm: A procedure to select a subset that balances the distribution (e.g., of prompts) across clusters. "a balance sampling algorithm based on hierarchical k-means"
- Content leakage: The unintended transfer or copying of content details from a style reference into the generated image. "leading to content leakage and poor stylized results"
- Content–style prompt combinations: Pairings of content descriptions with style descriptions used to generate stylized images. "generate stylized images from these contentâstyle prompt combinations"
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "we compute the cosine similarity between the stylized images and the reference style images in the MegaStyle-Encoder feature space."
- CSD: A style encoder method that fine-tunes CLIP to better capture style for retrieval and measurement. "CSD \cite{somepalli2024measuring} fine-tunes the CLIP image encoder"
- Cross-attention modules: Mechanisms in diffusion models that condition generation by attending across modalities (e.g., image-text). "inject them into a pre-trained diffusion model via cross-attention modules"
- Cross-image attention bias: Undesired attention interactions between tokens from different images that can cause content mixing. "mitigate cross-image attention bias and content leakage"
- DINOv3: A self-supervised vision model whose data curation practices (e.g., balanced sampling) are followed here. "we follow DINOv3 \cite{simeoni2025dinov3}"
- DiT (Diffusion Transformer): A transformer architecture adapted to diffusion models for image generation. "a Diffusion Transformer (DiT) \cite{peebles2023scalable}-based model FLUX"
- Exact Deduplication: Removal of exact duplicates from a dataset during curation. "Exact Deduplication, Fuzzy Deduplication and Semantic Deduplication"
- FID: Fréchet Inception Distance, measuring distribution difference between real and generated images. "FID \cite{heusel2017gans} and ArtFID \cite{wright2022artfid} calculate the distribution distance to measure the global style similarity between two style image sets."
- FLUX: A diffusion-transformer-based text-to-image model used as the foundation for the proposed style transfer system. "We build our style transfer model MegaStyle-FLUX on the powerful text-to-image (T2I) model FLUX \cite{flux2024}"
- Fuzzy Deduplication: Removal of near-duplicate entries based on fuzzy similarity criteria. "Exact Deduplication, Fuzzy Deduplication and Semantic Deduplication"
- Gram loss: A style similarity loss computed using Gram matrices of CNN features. "Gram loss \cite{gatys2016image,huang2017arbitrary} measures the distance between Gram matrices computed from feature maps of a pre-trained CNN model (e.g., VGG \cite{simonyan2014very})."
- Hierarchical clustering: A multi-level clustering procedure organizing data into nested clusters. "four-level hierarchical clustering with 50K, 10K, 5K, and 1K clusters from the lowest to the highest level."
- Hierarchical k-means: A clustering approach that applies k-means across multiple hierarchy levels for balance. "based on hierarchical k-means \cite{vo2024automatic}"
- Image–text contrastive objectives: Training objectives aligning image and text embeddings by pulling matched pairs together and pushing mismatches apart. "trained with imageâtext contrastive objectives"
- Inter-style diversity: The variety of distinct styles represented across a dataset. "maintaining intra-style consistency, inter-style diversity and high-quality for style dataset"
- Intra-style consistency: The uniformity of style across different images that share the same style label. "achieves high intra-style consistency while offering a large number of overall artistic styles"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique often used to learn styles. "trains 15k style and content LoRAs \cite{hu2021lora}"
- mAP@k: Mean Average Precision at rank k, a retrieval metric measuring ranking quality. "reporting mAP@k and Recall@k, where "
- MegaStyle-1.4M: The proposed large-scale dataset of style-consistent image pairs across diverse styles. "MegaStyle-1.4M contains style pairs that share the same style but have different content"
- MM-DiT: A multi-modal Diffusion Transformer backbone variant used within FLUX. "input them into FLUXâs MM-DiT backbone."
- mpnet: A transformer-based sentence embedding model used for text embeddings in clustering and sampling. "We utilize mpnet \cite{NEURIPS2020_c3a690be} for text embeddings"
- Paired supervision: A training paradigm using pairs that share a target attribute (style) but differ in others (content) to supervise learning. "employ paired supervisionâa data-driven training paradigm that has been widely validated in other generative tasks such as editing"
- Patchified: The process of converting images into sequences of patches (tokens) for transformer-based models. "The reference style image is encoded and patchified into visual tokens using FLUXâs VAE."
- Positional collision: Overlap in positional encodings that can cause interference between tokens. "to prevent positional collision with the target tokens and mitigate cross-image attention bias"
- Recall@k: The fraction of queries for which the correct item appears in the top-k retrieved results. "reporting mAP@k and Recall@k, where "
- RoPE (shifted RoPE): Rotary Positional Embeddings, here shifted to separate token positions and reduce interference. "We also apply an additional shifted RoPE \cite{zhangalignedgen} to the reference style tokens"
- SigLIP: A CLIP-like model using a sigmoid contrastive loss; used here as an image encoder backbone. "in our implementation, we use the SigLIP image encoder."
- SSCL (style-supervised contrastive learning): A contrastive learning objective supervised by style labels to learn style-specific embeddings. "we propose style-supervised contrastive learning (SSCL) to fine-tune a style encoder"
- Style encoder: A model component that extracts style-specific representations from images. "fine-tune a style encoder MegaStyle-Encoder for extracting expressive, style-specific representations"
- Style similarity measurement: The evaluation of how closely two images match in artistic style. "provide reliable style similarity measurement"
- StyleBench: A benchmark of real-world artworks and prompts for evaluating style transfer and encoders. "the StyleBench benchmark (as used in StyleShot \cite{11165480})"
- StyleRetrieval: A curated benchmark for assessing style retrieval performance with high intra-style consistency. "construct an intra-style consistent benchmark StyleRetrieval"
- Text-to-image (T2I): Generative modeling that synthesizes images conditioned on textual prompts. "SOTA text-to-image (T2I) generative models"
- VAE: Variational Autoencoder used to encode/decode images into latent tokens for diffusion transformers. "using FLUXâs VAE."
- VLMs (Vision–LLMs): Models trained jointly on images and text to understand and generate multimodal content. "we use visionâLLMs (VLMs) to caption images from content/style image pools"
Collections
Sign up for free to add this paper to one or more collections.