A Style is Worth One Code: Unlocking Code-to-Style Image Generation with Discrete Style Space
Abstract: Innovative visual stylization is a cornerstone of artistic creation, yet generating novel and consistent visual styles remains a significant challenge. Existing generative approaches typically rely on lengthy textual prompts, reference images, or parameter-efficient fine-tuning to guide style-aware image generation, but often struggle with style consistency, limited creativity, and complex style representations. In this paper, we affirm that a style is worth one numerical code by introducing the novel task, code-to-style image generation, which produces images with novel, consistent visual styles conditioned solely on a numerical style code. To date, this field has only been primarily explored by the industry (e.g., Midjourney), with no open-source research from the academic community. To fill this gap, we propose CoTyle, the first open-source method for this task. Specifically, we first train a discrete style codebook from a collection of images to extract style embeddings. These embeddings serve as conditions for a text-to-image diffusion model (T2I-DM) to generate stylistic images. Subsequently, we train an autoregressive style generator on the discrete style embeddings to model their distribution, allowing the synthesis of novel style embeddings. During inference, a numerical style code is mapped to a unique style embedding by the style generator, and this embedding guides the T2I-DM to generate images in the corresponding style. Unlike existing methods, our method offers unparalleled simplicity and diversity, unlocking a vast space of reproducible styles from minimal input. Extensive experiments validate that CoTyle effectively turns a numerical code into a style controller, demonstrating a style is worth one code.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make images in a specific visual style using just a simple number called a “style code.” The authors built an open-source system called CoTyle that turns a code into a consistent, reusable style, so you can generate many pictures that all look like they belong to the same “art style” without needing long prompts, reference images, or special add-on files.
What questions were the researchers asking?
They set out to answer three main questions:
- Can a single number reliably control an image’s style so that multiple pictures look consistently “the same style”?
- Can we create brand-new styles that don’t already exist, instead of only copying styles from reference images?
- Can we share or reuse styles easily, using a short, simple representation like a code, instead of big image files or complicated model add-ons?
How did they do it? (Methods explained simply)
Think of CoTyle like a three-part system:
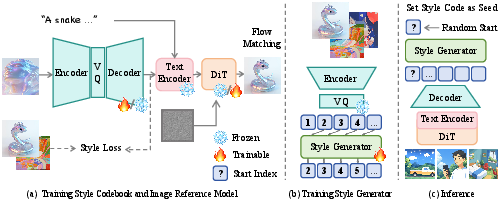
1) Building a “style dictionary” (the style codebook)
- Imagine a dictionary that doesn’t store words, but “style pieces.”
- The team trained this dictionary using pairs of images that share the same style (for example, both look like watercolor). The training nudges the dictionary to put similar styles close together and different styles far apart.
- This dictionary stores styles as discrete “tokens” (like LEGO pieces). Using tokens makes it easier to assemble styles step-by-step later.
Key idea: “Contrastive training” is like telling the system, “These two images belong together; those two don’t,” so it learns what style similarities look like.
2) Teaching the image generator to use those styles
- They connect the style dictionary to a powerful text-to-image model (a diffusion model), which is like a robot artist that draws pictures from a text prompt.
- Instead of feeding an actual reference image into this robot, they feed a “style embedding” from the dictionary—basically a compact description of the style.
- They pass this style description through the model’s text-like input path so the robot treats style as meaningful, high-level information (not just color or texture).
Plain terms:
- A “diffusion model” starts from noise and gradually turns it into a detailed image that fits your prompt and style.
- A “vision-LLM” helps the generator understand style as if it were part of the prompt, not just a picture to copy.
3) Turning a number into a brand-new style (the style generator)
- To make styles from scratch (without a reference image), they trained an “autoregressive” model. Autoregressive means it predicts the next token one at a time, like writing a sentence letter by letter.
- This model learns how style tokens usually go together.
- During generation, a user types a numeric style code. That code sets the random seed, which picks the first token, and then the model predicts the rest of the tokens to build a full style.
- Those tokens are turned into a style embedding, and the diffusion model uses it to draw images in that style.
Analogy:
- The style code is like a “seed” for a recipe. The autoregressive model writes the recipe steps (style tokens). The diffusion model cooks the dish (the final image) using your text prompt and the style recipe.
Extra tricks they used
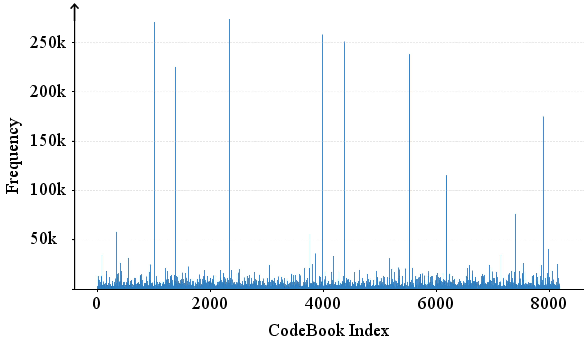
- High-frequency suppression: If some tokens appear too often, they might just be “boring defaults.” The team down-weights those to make styles more distinct and diverse.
- Style interpolation: Because a style is a sequence of tokens, you can mix tokens from two styles to blend them smoothly—like mixing two paint colors to get a gradient of looks.
What did they find?
Here are the main results in everyday terms:
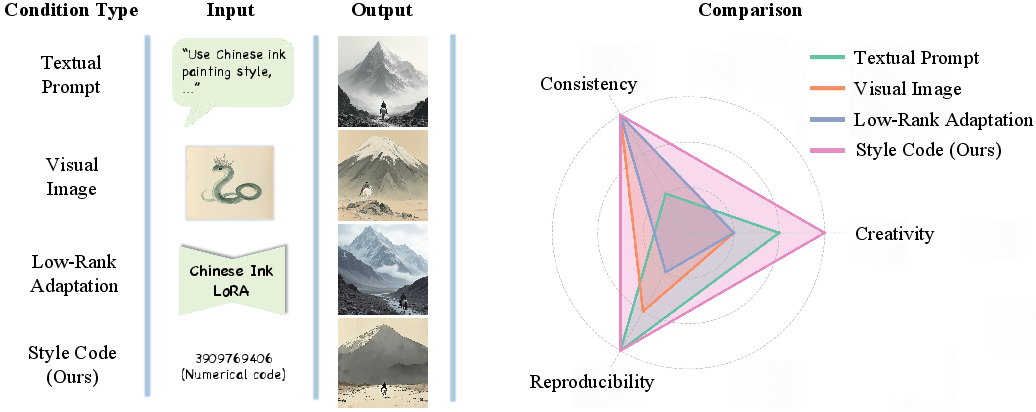
- Strong style consistency: CoTyle makes multiple images from the same code look very similar in style. Compared with Midjourney’s style codes, CoTyle was more consistent across images.
- Good text following: Images match the text prompts well while keeping the style.
- Creativity and diversity: CoTyle can invent new styles without needing a reference image. Its diversity was good, although slightly behind Midjourney in some tests; the authors say this can be improved by better training of the style generator.
- Works with references too: Even though CoTyle focuses on code-to-style, it also works great when you do want to use a style image, often matching or beating popular reference-based methods.
- Style blending: You can combine styles by mixing tokens, giving smooth, controllable style transitions.
Why that’s important:
- It proves “a style is worth one code.” A simple number can be a powerful, portable style controller.
Why does this matter?
- Easier sharing and reuse: Instead of sending images or model files, you can share a short code and get the same style anywhere CoTyle runs.
- New creative workflows: Artists, designers, and students can invent new looks from scratch and keep them consistent across projects, all with minimal setup.
- Faster experimentation: Changing style is as simple as changing a number, so trying new ideas becomes rapid and fun.
- Open-source and research-ready: Unlike some industry-only features, CoTyle is open, which helps the academic and maker communities explore, improve, and build on the idea.
In short, CoTyle shows that you don’t need long prompts or reference images to control style. A single code can define a unique, repeatable visual look—and that opens up a lot of creative and practical possibilities.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- Data and labeling for style pairs
- How are “same-style” positive pairs and negative pairs obtained at scale without manual curation? Describe the dataset(s), labeling protocol, inter-annotator agreement, and potential biases in “style” grouping.
- What is the coverage of the training style distribution (cultural/temporal/genre diversity)? Quantify representational bias and its effect on style diversity and consistency.
- Style codebook design and scaling
- Systematically study the impact of codebook size, embedding dimension, token count , and patching scheme on style granularity, content leakage, and diversity/consistency trade-offs.
- Analyze codebook collapse and failure modes beyond the reconstruction term; propose alternative regularizers and diagnostics to detect and prevent collapse early.
- Investigate whether continuous or hybrid (semi-discrete) style spaces yield better interpolation, control, and novelty than purely discrete indices.
- Autoregressive style generator limitations
- The style generator is trained from scratch on 0.5B params; quantify underfitting/overfitting, scaling laws, and benefits of pretraining or alternative priors (masked modeling, diffusion over indices, VAEs, flow priors).
- Explore richer training objectives (e.g., mutual information maximization between AR tokens and human-perceived style attributes) to improve diversity without sacrificing consistency.
- Go beyond “first-token via seed” initialization: evaluate alternative code-to-sequence mappings (learned hash, conditional prefix, promptable style attributes) to reduce collisions and improve determinism.
- Mapping from numerical code to style
- Provide a formal analysis of code collisions: what fraction of distinct codes lead to indistinguishable styles? Quantify collision rate vs. code length and RNG specifics.
- Ensure cross-version stability: how are codes preserved across model/codebook updates? Propose versioning, backward compatibility, or migration tools.
- Standardize the RNG and token sampling to guarantee determinism across hardware/frameworks for reproducible “same code, same style.”
- Style interpretability and controllability
- Decompose styles into interpretable factors (e.g., palette, stroke, texture, composition) and allow targeted control; link indices/tokens to attribute sliders or textual descriptors.
- Learn an invertible mapping between human-readable style descriptors and codes/indices to enable retrieval, editing, and explainability.
- Validate whether style interpolation corresponds to perceptually linear changes; quantify smoothness and attribute disentanglement.
- Content–style disentanglement and leakage
- Quantify the degree to which content information leaks into style embeddings (e.g., via content classifiers on style tokens); measure disentanglement explicitly.
- Evaluate robustness of style consistency across widely varying prompts, subjects, and scene compositions, not just within narrow prompt families.
- Conditioning and injection pathway
- The paper injects style via the VLM’s textual branch; systematically compare against alternative fusion strategies (cross-attention conditioning, FiLM, adapter-based, visual-branch concatenation) on alignment, controllability, and compute.
- Clarify the mismatch between the ViT used for codebook training and the VLM image encoder used later; evaluate alignment losses that explicitly bridge the two feature spaces.
- Frequency suppression strategy
- The high-frequency index suppression is heuristic; analyze why these indices become “placeholders,” measure its impact across datasets, and explore principled alternatives (e.g., entropy regularization, frequency-aware priors, reweighting during training rather than sampling).
- Evaluation gaps
- Novelty is not measured: add metrics that estimate distance from training styles (e.g., nearest-neighbor style retrieval, memorization tests, train–test leakage analysis) to validate “new styles.”
- Relying solely on CSD for style similarity may be limiting; triangulate with human studies, multi-metric evaluations (e.g., TIFA-like tests for content adherence under strong stylization), and perceptual experiments on consistency and diversity.
- The Midjourney comparison uses scraped images; ensure prompt parity and matched conditions or define a standardized public benchmark for code-to-style evaluation.
- Provide stress tests across resolutions/aspect ratios, CFG scales, sampler types, and diffusion steps to assess robustness of style preservation.
- Portability and ecosystem integration
- Assess whether style codes learned with one T2I backbone transfer to others (SDXL, FLUX, DiT variants) without retraining; propose a cross-model style standard or calibration protocol.
- Examine cross-domain generalization (photorealistic, scientific, medical, diagrams) and whether codes degrade or bias outputs in specialty domains.
- Efficiency and latency
- Quantify latency and memory overhead of AR generation of 196 tokens plus diffusion sampling; explore compression (shorter sequences, product quantization, hierarchical tokens) for real-time use.
- Investigate minimal code lengths that preserve style identity; characterize bits-per-style and the trade-off between compactness and fidelity.
- Safety, ethics, and legal considerations
- Evaluate memorization risks: do certain codes reproduce training artworks or specific artists’ styles? Add content provenance checks, deduplication, and memorization audits.
- Assess and mitigate harmful or NSFW style emergence from arbitrary codes; define safety filters at the style-token and AR-sampling levels.
- Address potential cultural appropriation or stereotyping via “style codes”; include fairness audits across cultural styles.
- Failure cases and diagnostics
- Document systematic failure modes (e.g., codes yielding “style-less” outputs, prompt override of style, artifacts in dense scenes) and propose automatic fallback or re-sampling strategies.
- Provide confidence measures or quality predictors for a given code to warn users about unreliable styles.
- Extensions left unexplored
- Video and 3D: can discrete style codes ensure temporal/spatial consistency in video or transfer coherently to 3D/NeRF pipelines?
- Editing workflows: integrate codes into image editing/inpainting while preserving existing content; evaluate localized style control.
- Style taxonomy and discovery: cluster the learned style space, map emergent categories, and enable guided exploration of novel regions.
Practical Applications
Immediate Applications
Below are applications that can be deployed now or with low integration effort, derived from CoTyle’s discrete style codebook, autoregressive style generator, textual-branch conditioning of the DiT, high‑frequency suppression strategy, and style interpolation.
- Creative production and marketing (advertising, media, design)
- Use case: Campaign asset generation with guaranteed style consistency across images, using a single reusable style code attached to briefs and assets.
- Sector: Software, media/entertainment, marketing.
- Tools/products/workflows: “Style Code Manager” plugin for Adobe/Blender/Figma; “Code‑to‑Style API” for internal creative pipelines; “Style Interpolator” to blend codes for seasonal refreshes.
- Dependencies/assumptions: Access to a capable T2I diffusion model; style codebook trained on brand exemplars; governance to avoid imitating protected styles; prompt discipline for content adherence.
- Game development pipelines
- Use case: Rapid prototyping of consistent NPC portraits, environment concepts, tile sets, and item icons by anchoring each sub‑project to a style code; smooth transitions using style interpolation for level progression.
- Sector: Gaming, software.
- Tools/products/workflows: Build scripts linking Jira tasks to style codes; asset management with “style provenance” metadata; CoTyle integrated into DCC tools.
- Dependencies/assumptions: Stable code‑to‑style mapping across model/version updates; licensing of base models; QA to check text–image alignment (CLIP‑T).
- Publishing and comics/animation pre‑viz
- Use case: Storyboards and comic panels generated in a consistent aesthetic; “style bible” distributed as a single code for multi‑team reproducibility.
- Sector: Media/entertainment.
- Tools/products/workflows: Studio “Style Code Library”; automatic panel generation with controlled style drift checks via CSD.
- Dependencies/assumptions: Training data representative of target aesthetics; clear IP guidelines to manage similarity thresholds.
- Software/UI design
- Use case: Generate consistent UI themes, icon packs, and marketing visuals from a code; interpolate styles for A/B testing of visual systems.
- Sector: Software, SaaS.
- Tools/products/workflows: Figma plugin that maps a style code to UI mockups; design system “style snapshots” as codes in a component library.
- Dependencies/assumptions: Domain‑specific datasets (UI screens/icons) to fine‑tune codebooks; human review for accessibility and contrast standards.
- Education and EdTech content creation
- Use case: Teachers produce consistent visuals (diagrams, worksheets) by sharing a single style code with students or co‑creators; coding tasks linking content prompts to shared styles.
- Sector: Education.
- Tools/products/workflows: LMS integration with “style tags”; classroom “style code exchange” for reproducible assignments.
- Dependencies/assumptions: Simple UI for non‑technical users; compute quotas; prompt templates aligned to curricula.
- Academic research reproducibility in generative styling
- Use case: Standardized style specification in papers and benchmarks using codes; controlled experiments on style consistency/diversity; open datasets of “style‑coded” images.
- Sector: Academia.
- Tools/products/workflows: Public “Style Code Registry” and evaluation suites (CSD, CLIP‑T, QualityCLIP); style interpolation protocols for ablations.
- Dependencies/assumptions: Community adoption; high‑quality paired style training data; versioned codebooks and generators.
- Print‑on‑demand and e‑commerce personalization
- Use case: Customers choose a style code to produce consistent series (posters, apparel); sellers curate code libraries for product lines.
- Sector: Retail/e‑commerce.
- Tools/products/workflows: Web configurator exposing style codes as a catalog; batch generation pipeline with code metadata for reorders.
- Dependencies/assumptions: Content safety checks; IP risk management; image QC for print fidelity.
- Social platforms and creator tooling
- Use case: Shareable “style tags” (codes) for consistent feeds and channel branding; creators publish their signature style as a single code for followers to remix.
- Sector: Social media, creator economy.
- Tools/products/workflows: “Style Code Share” and remix UI; moderation using CSD to detect style imitation of protected works.
- Dependencies/assumptions: Terms of use defining acceptable style similarity; scalable code validity across platform updates.
- Brand compliance and governance
- Use case: Style compliance audits using CSD to detect drift across assets; attach codes and “style provenance logs” to creative deliverables.
- Sector: Policy/compliance within enterprises.
- Tools/products/workflows: “Style Governance Dashboard” with thresholds for style similarity; alerts for near‑copy flags.
- Dependencies/assumptions: Agreed style similarity thresholds; legal frameworks for style resemblance; internal dataset of approved brand exemplars.
- Workflow integration and asset handoff
- Use case: Handoff documents carry a style code instead of heavy LoRA weights or reference images; reproducible generations across teams and vendors.
- Sector: Cross‑industry.
- Tools/products/workflows: Code versioning and changelogs; seed management policies.
- Dependencies/assumptions: Stable numerics (code→seed mapping); backward compatibility across model updates; documented interpolation ratios.
Long‑Term Applications
The following applications will benefit from further research, scaling, and standardization—particularly in diversity of novel styles, cross‑modal generalization, safety, and interoperability.
- Cross‑modal style codes (video, 3D, AR/XR)
- Use case: A single code controls consistent style across images, video sequences, 3D assets, and AR filters.
- Sector: Media/entertainment, software, robotics (human‑friendly visual semantics).
- Tools/products/workflows: Multi‑modal “Style Codebook” training and shared tokenizer across T2I/T2V/3D; real‑time AR style renderer.
- Dependencies/assumptions: Robust multi‑modal models; temporal consistency; efficient on‑device inference.
- Interoperable style standards (“Pantone for AI styles”)
- Use case: A standardized, portable style identifier usable across different models/vendors, with agreed metrics for similarity.
- Sector: Policy, software, media.
- Tools/products/workflows: Open “AI Style Identifier” standard, conformance tests (CSD variants), registries and certification labels.
- Dependencies/assumptions: Consortium governance; backward‑compatible updates; public test suites.
- Style marketplace and licensing
- Use case: Creators mint style codes; license them to studios/brands; royalties tracked by usage; remix rights via style interpolation weights.
- Sector: Finance (royalty flows), media/creator economy.
- Tools/products/workflows: Market listing, license terms encoded in metadata; similarity resolution and takedown processes; optional blockchain audit trail.
- Dependencies/assumptions: Legal recognition of style IP; reliable similarity detection; dispute resolution mechanisms.
- Real‑time personalization in consumer devices
- Use case: Cameras and mobile apps apply personal style codes to photos and UIs; dynamic streaming with style control.
- Sector: Consumer software, hardware.
- Tools/products/workflows: On‑device CoTyle variants; low‑latency sampling; battery‑aware suppression strategies.
- Dependencies/assumptions: Efficient models; privacy‑preserving inference; hardware acceleration.
- Brand governance at scale
- Use case: Automated monitoring of global asset repositories to detect style drift and unauthorized style borrowing; continuous compliance scoring.
- Sector: Enterprise software, policy/compliance.
- Tools/products/workflows: DAM integration; dashboards combining CSD/QualityCLIP; approval workflows tied to codes.
- Dependencies/assumptions: Enterprise data access; calibrated thresholds; explainable audits.
- Safety and copyright compliance filters
- Use case: Prevent generation that is too similar to known, protected styles; proactive “anti‑imitative” filtering during sampling.
- Sector: Policy, platform trust & safety.
- Tools/products/workflows: Pre‑sampling checks; index frequency suppression configured by policy; “distance to protected styles” reports.
- Dependencies/assumptions: High‑precision style similarity metrics; curated protected‑style datasets; clear legal definitions.
- Education and therapeutic applications
- Use case: Personalized, consistent educational materials and art therapy environments tuned via codes; controlled exposure to calming or attention‑supporting styles.
- Sector: Education, healthcare (behavioral health).
- Tools/products/workflows: EdTech modules with style presets; clinician‑led trials assessing outcomes.
- Dependencies/assumptions: Clinical validation; accessibility standards; ethical guidelines.
- Style analytics for business impact
- Use case: Quantify how style codes affect conversion, engagement, and retention; optimize style choices via A/B tests.
- Sector: Finance/marketing analytics.
- Tools/products/workflows: “Style Analytics Engine” linking codes to KPIs; automated exploration via interpolation; report generation.
- Dependencies/assumptions: Data pipelines; privacy compliance; statistical rigor.
- Cultural preservation and museums
- Use case: Encode historical styles as reproducible codes; interactive exhibits where visitors explore style blends.
- Sector: Culture/heritage, education.
- Tools/products/workflows: Curatorial codebooks; public kiosks with safe prompt sets; provenance metadata.
- Dependencies/assumptions: Rights to digitize styles; cultural sensitivity; expert review.
- International policy and standards
- Use case: Cross‑border guidelines for style cloning, transparency, and watermarking; interoperable code provenance standards.
- Sector: Policy/regulation.
- Tools/products/workflows: Standards bodies defining code provenance logs; compliance certifications; audit APIs.
- Dependencies/assumptions: Multi‑stakeholder agreement; enforceable norms; open measurement tools.
Cross‑cutting assumptions and technical dependencies
- Model and data: Requires a robust T2I diffusion backbone (e.g., DiT/SDXL), high‑quality paired style datasets, and a well‑trained discrete codebook (size, token length) with contrastive + reconstruction losses to avoid collapse.
- Stability and reproducibility: Style code→seed mappings must remain stable across updates; document codebook versioning and sampling parameters (including high‑frequency suppression).
- Diversity and novelty: Current style generator diversity may need improvement to maximize novel style space; ongoing training and evaluation with Diversity (1−CSD) are recommended.
- Safety/IP: Adopt CSD‑based thresholds and policies to avoid generating work overly similar to protected styles; maintain provenance logs and disclosures.
- Usability: Provide simple UIs and plugins for non‑technical users; prompt templates; clear documentation on interpolation ratios and expected outputs.
- Compute and latency: GPU resources for training/inference; consider on‑device or serverless variants for real‑time applications.
Glossary
- Adapter modules: Lightweight conditioning components inserted into a generative model to incorporate external signals. "Common conditioning mechanisms include noise inversion~\cite{cao2025causalctrl, song2020ddim}, adapter modules~\cite{guo2024pulid,ye2023ipadapter,betterfit}, parameter-efficient fine-tuning~\cite{frenkel2024blora,shah2024ziplora,liu2025separate, duan2024tuning}, and token concatenation~\cite{tan2025ominicontrol,tan2025ominicontrol2,liu2025omnidish,boow,zhang2025grouprelativeattentionguidance}."
- Autoregressive style generator: A generator that models style as sequences of discrete tokens, predicting each next token conditioned on previous ones. "Subsequently, we train an autoregressive style generator on the discrete style embeddings to model their distribution, allowing the synthesis of novel style embeddings."
- Code-to-style image generation: A generation paradigm where a numerical code uniquely specifies and reproduces a visual style. "To address these limitations, we propose code-to-style generation, a novel paradigm that uses a numerical style code to create novel styles."
- Codebook collapse: A failure mode where many inputs map to the same code(s), reducing representational capacity. "Further, we find that adding a reconstruction loss is essential to avoid codebook collapse during training (Sec.~\ref{sec:exp})."
- Commit loss: A VQ objective term that encourages encoder outputs to stay close to the selected codebook vectors. "Similar to traditional vector-quantized methods~\cite{van2017vqvae, esser2021vqgan, ma2025unitok}, we employ a commit loss and a codebook loss."
- Contrastive loss: An objective that pulls embeddings of similar styles together and pushes dissimilar styles apart. "Thus, we employ a contrastive loss to train the model."
- CSD: A metric for measuring style similarity, used to evaluate consistency and diversity of generated styles. "To evaluate our method, we employ the CSD~\cite{somepalli2024csd} to assess both style consistency and diversity."
- Diffusion Transformer (DiT): A transformer-based diffusion architecture for image generation. "Thus, we treat style embeddings as a form of textual input and injecting them into the Diffusion Transformer (DiT~\cite{peebles2023dit}) through textual branch."
- Discrete style codebook: A learned dictionary of quantized style embeddings represented by discrete indices. "Specifically, we first train a discrete style codebook from a collection of images to extract style embeddings."
- DreamBooth: A fine-tuning technique enabling subject-specific generation from few-shot examples. "DreamBooth~\cite{ruiz2023dreambooth} with Textual Inversion~\cite{gal2022textualinversion} enable identity-specific generation from few-shot examples."
- High-frequency suppression: A sampling strategy that down-weights overly frequent code indices to avoid style-less outputs. "Therefore, we propose high-frequency suppression strategy."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into large models. "(e.g. Low-Rank Adaptation, LoRA~\cite{hu2022lora})"
- Next-token prediction: An autoregressive training objective where the model predicts the next token in a sequence. "These indices are then used to train an autoregressive model via next token prediction~\cite{shannon1949ntp}, effectively learning the distribution of style features."
- Noise inversion: A technique to recover or control the noise used by a diffusion model for conditioning or editing. "Common conditioning mechanisms include noise inversion~\cite{cao2025causalctrl, song2020ddim}, adapter modules~\cite{guo2024pulid,ye2023ipadapter,betterfit}, parameter-efficient fine-tuning~\cite{frenkel2024blora,shah2024ziplora,liu2025separate, duan2024tuning}, and token concatenation~\cite{tan2025ominicontrol,tan2025ominicontrol2,liu2025omnidish,boow,zhang2025grouprelativeattentionguidance}."
- Parameter-efficient fine-tuning: Methods that adapt large models using a small number of additional parameters. "Common conditioning mechanisms include noise inversion~\cite{cao2025causalctrl, song2020ddim}, adapter modules~\cite{guo2024pulid,ye2023ipadapter,betterfit}, parameter-efficient fine-tuning~\cite{frenkel2024blora,shah2024ziplora,liu2025separate, duan2024tuning}, and token concatenation~\cite{tan2025ominicontrol,tan2025ominicontrol2,liu2025omnidish,boow,zhang2025grouprelativeattentionguidance}."
- QualityCLIP: A CLIP-based metric used to estimate the aesthetic quality of generated images. "and assess the aesthetic quality of generated images via the recently popular QualityCLIP \cite{agnolucci2024quality}."
- Rectified flow matching: A training approach for generative modeling that matches flows between distributions, used here with diffusion. "to generate the target image by rectified flow matching~\cite{lipman2022flowmatching}."
- Style interpolation: Blending multiple styles by mixing subsets of their discrete style indices. "Further, we extend CoTyle to support image-driven stylized image generation and style interpolation."
- T2I-DM: Abbreviation for text-to-image diffusion model that generates images from text prompts. "These embeddings serve as conditions for a text-to-image diffusion model (T2I-DM) to generate stylistic images."
- Textual Inversion: A technique that learns a new token to represent a concept in a text-to-image model. "DreamBooth~\cite{ruiz2023dreambooth} with Textual Inversion~\cite{gal2022textualinversion} enable identity-specific generation from few-shot examples."
- Token concatenation: A conditioning mechanism that concatenates control tokens with model tokens to inject guidance. "Common conditioning mechanisms include noise inversion~\cite{cao2025causalctrl, song2020ddim}, adapter modules~\cite{guo2024pulid,ye2023ipadapter,betterfit}, parameter-efficient fine-tuning~\cite{frenkel2024blora,shah2024ziplora,liu2025separate, duan2024tuning}, and token concatenation~\cite{tan2025ominicontrol,tan2025ominicontrol2,liu2025omnidish,boow,zhang2025grouprelativeattentionguidance}."
- Vector-quantized methods: Approaches that map continuous features to discrete codes via a learned codebook (e.g., VQ-VAE/GAN). "Similar to traditional vector-quantized methods~\cite{van2017vqvae, esser2021vqgan, ma2025unitok}, we employ a commit loss and a codebook loss."
- ViT (Vision Transformer): A transformer architecture applied to image feature extraction. "The codebook is trained using features extracted from a vision transformer (ViT)~\cite{dosovitskiy2020vit}..."
- Vision-LLM (VLM): A model that jointly encodes and aligns visual and textual information. "Specifically, we employ a vision LLM (VLM)~\cite{qwen2.5-VL} as our text encoder, while the style embedding replaces the original image features."
Collections
Sign up for free to add this paper to one or more collections.