- The paper introduces a micro-serving paradigm that decomposes complex diffusion workflows into independently schedulable nodes for better resource control.
- It leverages diffusion-specific optimizations, including approximate caching and asynchronous LoRA loading, to enhance throughput and reduce latency.
- Evaluation shows up to 3× higher request throughput, 3× fewer GPUs usage, and a latency reduction of up to 40% compared to monolithic serving systems.
Micro-Serving Diffusion Workflows with LegoDiffusion
Motivation and Background
Diffusion-based text-to-image (T2I) generation workflows, comprising base diffusion models and multiple adapters (e.g., ControlNet, LoRA), form complex pipelines for synthesizing high-fidelity images from textual inputs. Despite the inherent modularity of these workflows, prevalent inference systems utilize a monolithic serving architecture that treats the entire workflow as an opaque unit, resulting in inefficiencies for resource scaling, model sharing, runtime optimization, and fault isolation. These inefficiencies are particularly pronounced given that production traces indicate significant reuse of popular diffusion backbones and adapter models, and that bottlenecks are often localized to specific components.
Micro-Serving: System Architecture and Design
LegoDiffusion introduces a micro-serving paradigm that decomposes diffusion workflows into independently managed, schedulable model-execution nodes, providing fine-grained control over resource allocation, per-model scaling, model sharing, and adaptive parallelization.
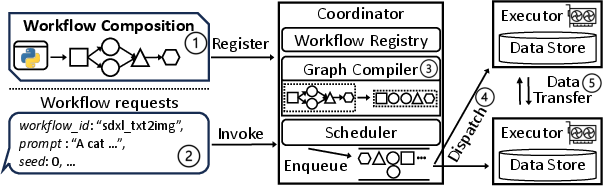
Figure 1: An overview of LegoDiffusion’s micro-serving architecture, decomposing diffusion workflows into schedulable nodes for cluster-level optimization.
Programming Model
LegoDiffusion provides a Python-embedded DSL for workflow composition, enabling model developers to integrate models and adapters without concern for their orchestration, while workflow developers declaratively compose models into complete pipelines. Model integration is standardized via a base class supporting typed I/O interfaces and patching semantics for adapters, facilitating extensibility and robust error checking. The implicit workflow DAG and data dependencies are automatically inferred and optimized via the system's compiler.
Graph Compiler and Diffusion-Specific Optimizations
The graph compiler constructs a DAG of workflow nodes and applies optimization passes. These include:
- Approximate caching, reducing denoising computation by initializing from similar cached latent representations.
- Asynchronous LoRA loading, overlapping adapter retrieval with diffusion inference to minimize latency.
These optimizations are realized transparently, with automatic insertion of supporting operations based on workflow structure.
GPU-Native Runtime and Distributed Data Engine
At runtime, LegoDiffusion employs a lazy execution model, instantiating the workflow DAG per request. Each node is independently scheduled, and execution is orchestrated at the granularity of model-level operators. A distributed data engine, built atop NVSHMEM, supports GPU-direct, zero-copy tensor movement, with both eager and deferred fetch modes to enable high-bandwidth, latency-sensitive communications required by parallelization strategies like latent parallelism and ControlNet parallelism.
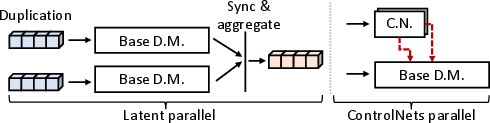
Figure 2: Latent parallelism and ControlNet parallelism, illustrating the complex, fine-grained data dependencies and synchronizations in diffusion workflows.
Cluster-Scale Scheduling and Resource Optimization
The LegoDiffusion scheduler exploits micro-serving decomposition by:
- Per-model scaling: Scaling only bottleneck models instead of replicating the full workflow.
- Cross-workflow model sharing: Multi-tenant batching and routing of nodes referencing identical models, mitigating redundant memory footprints and balancing load.
- Adaptive parallelism: Dynamically selecting parallelism degree based on instantaneous cluster availability, maximizing throughput without introducing queueing delays.
- SLO-aware admission control: Early-abort admission prevents cascading violations by estimating remaining critical path latency per request.
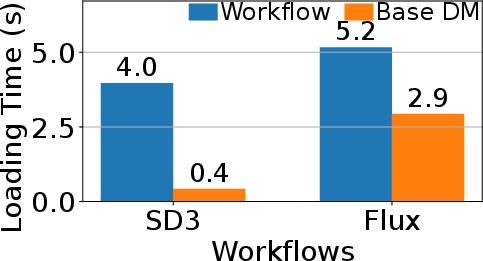
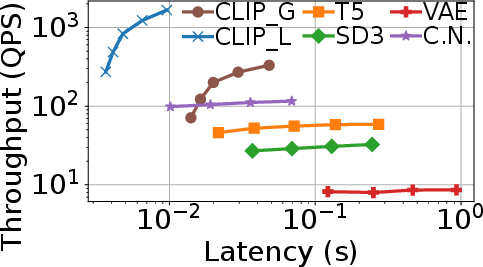
Figure 3: Left: Model loading time comparison for full workflow scaling vs. base diffusion model scaling. Right: Latency-throughput tradeoff for SD3 workflows, highlighting heterogeneous resource demands.
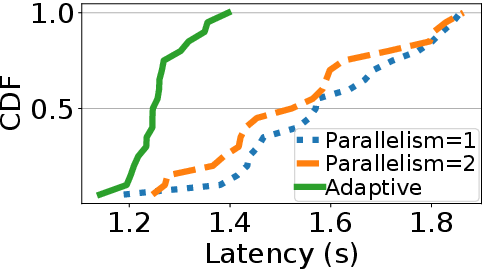
Figure 4: Left: Model sharing reduces request latency by multiplexing across workflows. Right: Adaptive parallelization improves request latency through dynamic resource allocation.
Comprehensive evaluation of LegoDiffusion demonstrates substantial improvements over monolithic baselines (e.g., Diffusers, Diffusers-C, Diffusers-S) across multiple dimensions:
- Request throughput: Sustains up to 3× higher request rates at comparable SLO attainment.
- Resource efficiency: Meets SLO requirements with up to 3× fewer GPUs.
- Burst tolerance: Handles up to 8× higher traffic burstiness while maintaining >90% SLO attainment.
- SLO stringency: Satisfies 6× more stringent SLOs than monolithic counterparts.
- Latency reduction: Model sharing and adaptive parallelism decrease latency by up to 40%.
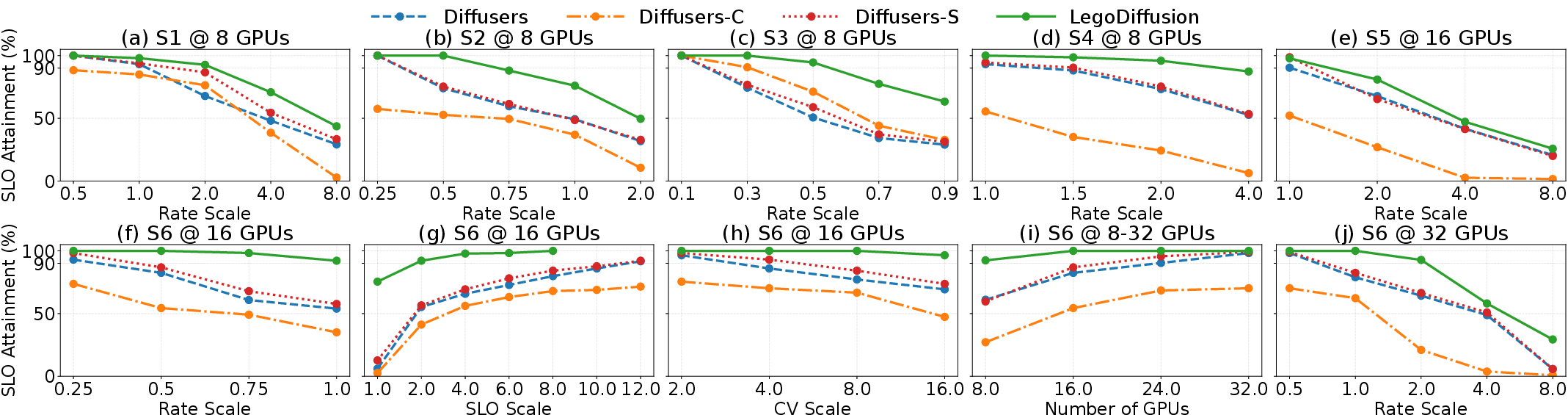
Figure 5: End-to-end performance across six deployment settings, showcasing SLO attainment versus traffic rate, SLO scale, burstiness, and cluster size.
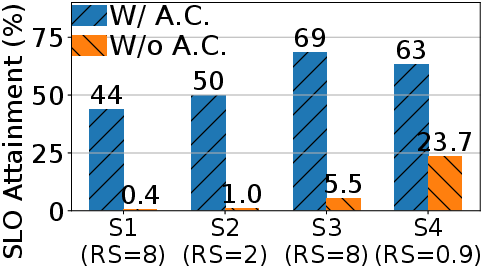
Figure 6: Left: Normalized latency of LegoDiffusion for increasing GPU counts, evidencing scalable intra-/inter-node parallelism. Right: Impact of admission control on request SLO attainment under varying loads.
System overhead induced by micro-serving, including inter-node communication and control-plane coordination, remains negligible (<150ms overhead vs. 2–20s inference); control-plane scalability persists up to 256-GPU clusters with minimal coordinator load. Data transmission latency for large tensors is <1ms, confirming that LegoDiffusion’s architecture is not bottlenecked by inter-GPU communication.
Case Study and Compatibility with Diffusion Optimizations
LegoDiffusion supports diffusion-specific optimizations such as approximate caching and async LoRA loading, achieving speedups commensurate with their original implementations (e.g., up to 1.43× via approximate caching, LoRA loading latency reduced from 0.5s to 0.05s).
Implications and Future Directions
The micro-serving architecture fundamentally improves cluster-level resource utilization and operational robustness for diffusion workflows, directly addressing major inefficiencies of monolithic serving systems. By exposing workflow internals to the runtime scheduler, LegoDiffusion enables high-throughput, adaptive, and multi-tenant deployments. These advances are fully compatible with model-specific acceleration techniques and enable sustainable scaling as diffusion model complexity and production workloads increase.
Future developments may include:
- Dynamic scaling across heterogeneous clusters with multi-model and multi-adapter workloads.
- Integration of fine-grained SLO tuning for diverse real-time applications.
- Automated extension of graph compiler passes to capture emerging diffusion optimizations.
- Robustness enhancements and fully distributed control-plane architectures.
Conclusion
LegoDiffusion establishes a micro-serving paradigm for diffusion workflows, decomposing pipelines into schedulable, sharable nodes, and employing a specialized GPU-native runtime and cluster-level scheduling for efficient resource management. The system delivers significant improvements in throughput, latency, resource efficiency, and burst tolerance compared to monolithic designs, while supporting state-of-the-art diffusion optimizations and maintaining negligible system overhead. Its architectural innovations lay the foundation for future scalable, adaptive deployment of complex generative workflows in distributed environments.
Reference: "LegoDiffusion: Micro-Serving Text-to-Image Diffusion Workflows" (2604.08123).