- The paper presents a novel system that enables deadline-aware preemption and elastic resource allocation for text-to-image and text-to-video workloads.
- It introduces a dynamic programming scheduler that optimizes step-level diffusion iterations, resulting in high SLO compliance even under mixed load conditions.
- Experimental results demonstrate a 44% increase in SLO attainment and significant latency reductions through intelligent preemption and dynamic SP reconfiguration.
GENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads
Introduction and Motivation
GENSERVE addresses the fundamental challenge of serving heterogeneous diffusion workloads—specifically, text-to-image (T2I) and text-to-video (T2V) generation—on shared GPU clusters while optimizing service-level objective (SLO) attainment. The stark disparities in compute demands, parallelism profiles, and SLO stringency between T2I and T2V tasks create contention and deadline violations under conventional serving policies such as FIFO, SJF, or static resource partitioning. The key insight exploited by this work is the highly predictable and stepwise-iterative nature of modern diffusion models, particularly DiT architectures, which allow for fine-grained, low-cost, step-level preemption and online adaptation, facilitating proactive coordination of resource allocation.
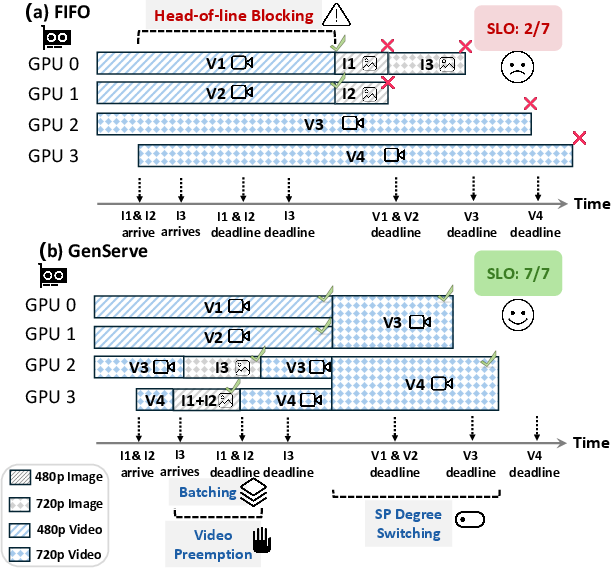
Figure 1: Serving 4 videos (V1--V4) and 3 images (I1--I3) on 4 GPUs. (a) FIFO leads to head-of-line blocking and deadline misses for images; (b) GENSERVE leverages preemption and dynamic SP/batching to satisfy all deadlines.
System Design
GENSERVE integrates three synergistic resource management and scheduling primitives:
- Intelligent Video Preemption: Video requests, typically long-running, are paused at denoising step boundaries when SLO-critical image requests arrive and no GPU is immediately available. The system computes deadline slack for each video and selectively preempts the highest-slack candidates, guaranteeing that preemption will not result in subsequent deadline violations. Upon resource availability, paused videos are resumed, with possible SP upgrades to accelerate their completion if slack becomes tight or the image queue is depleted.
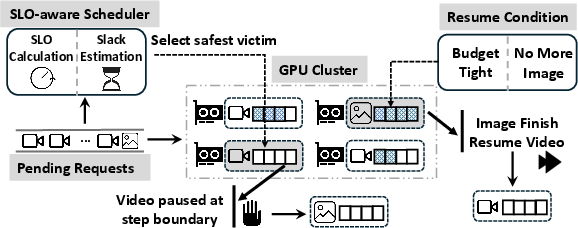
Figure 3: GENSERVE’s scheduler leverages step-level predictability to preempt videos, prioritizing SLO compliance for urgent image requests by pausing and resuming video workloads adaptively.
- Elastic Resource Allocation: T2I and T2V workloads possess divergent parallelism and batching optima. GENSERVE dynamically assigns SP degrees to video jobs based on resolution and load, and employs SLO-aware batching for image jobs, balancing GPU utilization with per-request latency constraints. Joint adaptation ensures that GPU resources are continually rebalanced as the workload mix and SLO pressure evolve.
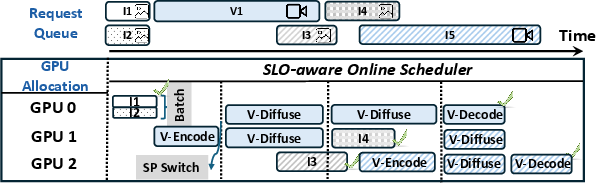
Figure 5: The SLO-aware scheduler adaptively batches image jobs, varies video SP degrees, and decouples pipeline stages for maximal utilization and SLO attainment.
- SLO-Aware Online Scheduling via Dynamic Programming: At each scheduling round (triggered at step boundaries or job events), GENSERVE constructs and scores a compact set of scheduling candidates (batch sizes for images, concrete placements and SP configurations for videos), and solves a knapsack-style DP to globally maximize the number of SLO-satisfying requests. The scheduler’s decisiveness is facilitated by the determinism of per-step diffusion inference costs.
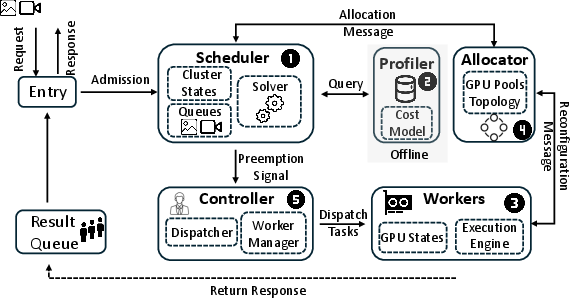
Figure 7: GENSERVE system overview: Scheduler, Profiler, Solver, Allocator, and Worker components form a closed optimization and execution loop.
Experimental Results
End-to-End SLO Attainment
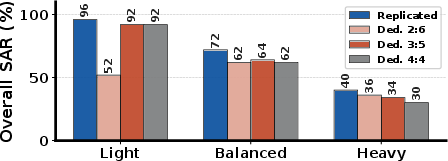
GENSERVE yields up to 44% higher SLO attainment rates (SAR) compared to competitive baselines (SRTF, FCFS, SJF, RASP) across a variety of hardware, workload mix, and system load regimes. Under balanced mixes (50:50 T2I:T2V), GENSERVE maintains high overall SAR, approaching 90% under relaxed SLOs and retaining superior image and video deadline satisfaction even as load intensifies or tasks become more video-heavy.
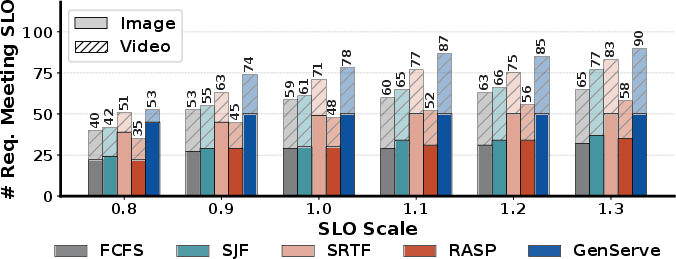
Figure 9: Number of SLO-satisfying requests versus SLO stringency; GENSERVE consistently leads, with maximal benefit at moderate/large SLOs.
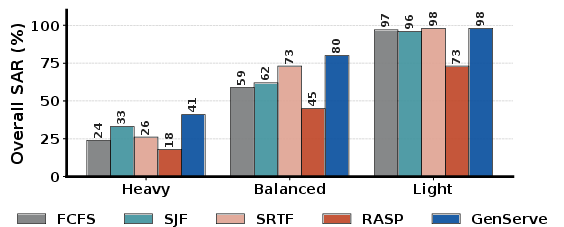
Figure 11: Overall SAR across workload mixes; GENSERVE maintains high SLO success as video proportion increases, outperforming all baselines.
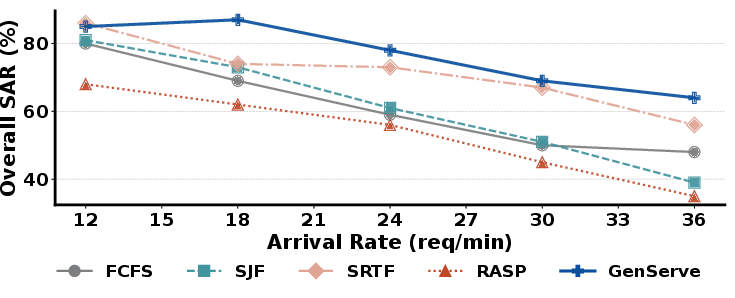
Figure 13: SAR versus arrival rate. GENSERVE’s advantage persists across a spectrum of system loads, particularly notable at 18 to 36 req/min.
Latency and Queueing
GENSERVE eliminates high-percentile queuing for image jobs caused by head-of-line blocking under FIFO-style policies, reducing median and tail image latencies by factors of 3x or more in many settings. Among videos, the system reduces median completion latency via dynamic SP, with larger tails as a deliberate, SLO-aware trade-off.
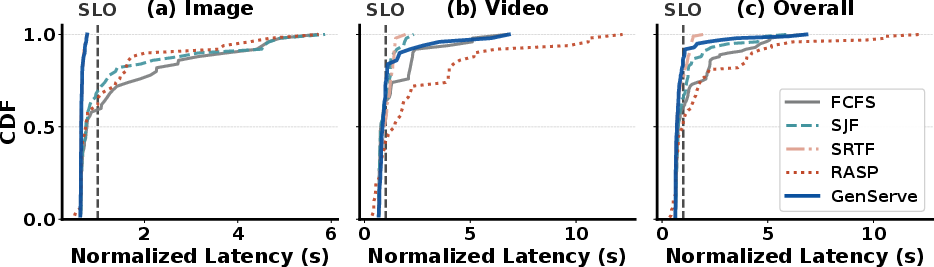
Figure 6: CDF of request turnaround latency; GENSERVE sharply reduces image tails and accelerates video median latency.
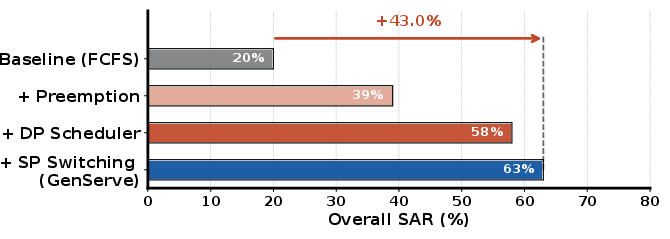
Ablation Study
GENSERVE’s layered architecture was ablated stepwise, revealing:
Architecture Sensitivity
Theoretical and Practical Implications
GENSERVE fundamentally advances the state-of-the-art in large-scale generative model serving by leveraging the architectural properties of diffusion models: predictable per-step cost and state-saving at boundaries. By unifying step-aware preemption, elastic parallelism, and SLO-driven scheduling with precise workload-aware cost models, GENSERVE navigates the joint resource allocation space much more efficiently than existing static or greedy policies. The approach is robust to stochastic workload mixes, request size distributions, and bursty arrivals, and is not bottlenecked by solver overhead even at nontrivial cluster or request scale.
Pragmatically, this enables serving stacks to support latency-critical multi-modal (image/video) generation at high utilization, without over-provisioning or deleterious SLO trade-offs. The methods are compatible and potentially synergistic with orthogonal advances in patch-level caching, approximate computation, and multi-model routing. Future work may extend these insights to cross-modal systems and other iterative generative models.
Conclusion
GENSERVE demonstrates that step-level preemptibility and precise cost modeling in diffusion models unlock new opportunities for SLO-driven co-serving of heterogeneous generative workloads. The coordinated use of deadline-aware preemption, elastic SP allocation, and dynamic batching, optimized through a lightweight DP scheduler, produces substantial improvements in SLO attainment and latency, with minimal runtime overhead or architectural complexity. These findings have immediate applicability for large-scale deployment of text-to-image and text-to-video services and broader implications for efficient management of future multi-modal, iterative generative model workloads.