- The paper presents a discriminative diffusion paradigm that enhances non-autoregressive video captioning by mitigating slow inference and error propagation.
- It employs a three-stage process combining video and text encoding, noise-based discriminative denoising with cross-modal attention, and transformer-driven parallel decoding.
- Experimental results demonstrate improvements up to +9.9 CIDEr and +2.6 BLEU@4 on benchmarks like MSR-VTT, highlighting its practical efficiency and quality.
DiffVC: A Diffusion-Based Non-Autoregressive Framework for Video Captioning
Motivation and Background
Video captioning operations traditionally employ autoregressive paradigms, characterized by sequential word generation conditioned on previous tokens and visual representations. While autoregression yields semantically coherent captions, it is hampered by slow generation speeds—particularly for longer sequences—and accumulative error propagation. Existing non-autoregressive captioners offer faster inference by generating all words in parallel, but suffer from semantic incompleteness and diminished generation quality, largely due to insufficient modeling of inter-modal interactions between vision and language.
Diffusion models have demonstrated efficacy in generative tasks involving continuous data modalities (e.g., images, audio), outperforming GANs and VAEs in stability and output diversity. However, their application to discrete sequence data has remained limited. DiffVC addresses this gap by introducing a discriminative conditional diffusion paradigm for non-autoregressive video captioning, optimizing both inference speed and generation quality.
Methodological Overview
DiffVC consists of a three-stage pipeline:
- Video and Text Representation Encoding: The visual encoder, pre-trained on RSFD, transforms the input video into a spatiotemporal embedding. Simultaneously, the text encoder maps the ground-truth caption to a continuous textual representation.
- Diffusion and Discriminative Denoising: Gaussian noise is progressively added during training to textual embeddings, producing a temporal sequence of noisy representations. A discriminative denoiser, leveraging cross-attention between noisy textual queries and visual-key/value pairs, reconstructs noise-free textual representations while explicitly preserving conditional semantics.
(Figure 1)
Figure 1: DiffVC overall architecture including discriminative denoising and non-autoregressive decoding.
- Non-Autoregressive Language Modeling: The denoised textual representation is decoded via a transformer-based non-autoregressive LLM, generating all tokens in parallel, constrained by maximum sequence length.
Inference deviates from the training path: random noise sampled from a Gaussian distribution (in absence of ground-truth captions) is fed to the discriminative denoiser, which, conditioned on the visual embedding, generates an initial textual representation for the language decoder.
Architectural Innovations
The discriminative denoiser is central to DiffVC’s performance. Unlike classic concatenation-based cross-attention (e.g., [CLS]+text tokens), DiffVC employs distinct pathways for queries (text) and keys/values (visual), thus avoiding dilution of visual context and enhancing cross-modal alignment. Ablation studies reveal that the removal of the discriminative denoiser leads to a marked decrease in generation metrics.
Additionally, the non-autoregressive LLM is crucial. An ablation where denoiser outputs are projected directly to the vocabulary layer yields significantly inferior captions, validating the necessity of deep transformer refinement for parallel decoding.
Experimental Analysis
Quantitative Results
DiffVC achieves state-of-the-art results among non-autoregressive methods across MSVD, MSR-VTT, and VATEX benchmarks, with performance comparable to the best autoregressive architectures:
- On MSR-VTT, DiffVC surpasses several autoregressive methods with CIDEr up to 56.7 and BLEU@4 up to 44.5.
- Maximum improvement over existing non-autoregressive methods reaches +9.9 CIDEr and +2.6 BLEU@4.
- DiffVC substantially improves generation quality for long sequences while exhibiting notable speed advantages.
(Figure 2)
Figure 2: Generation speed comparison between non-autoregressive and autoregressive captioners.
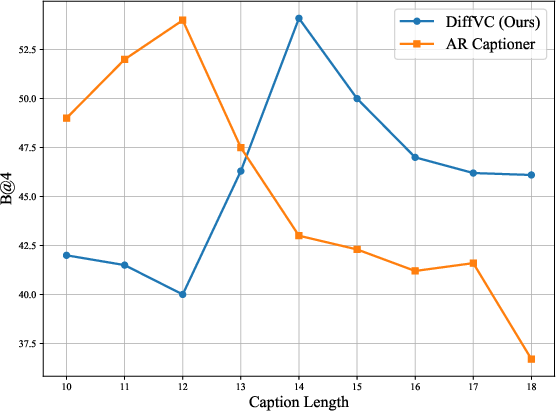
Figure 3: Comparison on generation quality between non-autoregressive and autoregressive video captioning.
Qualitative Results
Case studies demonstrate DiffVC's ability to generate semantically complete and precise descriptions, identifying low-frequency visual entities and maintaining fidelity across differentiable semantic concepts (e.g., distinguishing between "girl" and "woman", as shown in the qualitative samples).
(Figure 4)
Figure 4: Case study on MSR-VTT, highlighting DiffVC’s semantic completeness and accuracy.
Ablation Findings
- Discriminative Denoiser: Its removal degrades performance, confirming its necessity for robust inter-modal modeling.
- Denoiser Depth / LM Blocks: Optimal performance is achieved with 12 denoiser blocks and 6 LM blocks; exceeding these values causes diminishing returns.
- Inference Steps: Increasing timesteps improves output quality but at computational cost, with 20 steps set as optimal balance.
Practical and Theoretical Implications
Practically, DiffVC enables fast, high-quality caption generation suitable for real-time applications in video retrieval, recommendation, and automated content annotation. Theoretically, it establishes a robust pathway for diffusion models in discrete sequence generation, showcasing the benefit of discriminative cross-modal denoising in overcoming semantic deficiencies commonly associated with non-autoregressive methods. The paradigm provides a template for scaling diffusion-based language generation tasks beyond captioning.
Speculation on Future Directions
- Extension to Multilingual Captioning: Incorporating multilingual decoders may leverage DiffVC in cross-lingual settings.
- Hierarchical or Multi-stage Denoising: More granular modeling of temporal dependencies (e.g., hierarchical visual conditioning) could further boost semantic correctness.
- Integration with LLMs: Coupling DiffVC with large pre-trained transformers could enhance generalization, domain adaptation, and robustness.
- Application to Other Discrete Generation Tasks: Expansion to dialogue generation, text-to-video synthesis, and story generation can exploit DiffVC's denoising architecture.
Conclusion
DiffVC introduces a discriminative diffusion-based non-autoregressive video captioning system, resolving the speed and error accumulation challenges of autoregressive paradigms while preserving generation quality through explicit cross-modal modeling. Its architecture and empirical results validate the diffusion paradigm for discrete sequence tasks constrained by multimodal data, opening new avenues for efficient and semantically rich video-language generation in practical deployments.

