- The paper introduces a novel image-conditioned masked diffusion language model (MDC) that overcomes the asymmetry in autoregressive captioning by providing consistent visual supervision.
- The methodology combines a vision encoder with a Transformer decoder using a randomized masking ratio and unified noise schedule, achieving competitive performance on benchmarks like ImageNet and MSCOCO.
- Implications include simplified training and tuning, robust transferability to downstream tasks, and enhanced compositional reasoning in visual recognition and captioning.
Masked Diffusion Captioning for Visual Feature Learning
Introduction and Motivation
The paper introduces Masked Diffusion Captioning (MDC), a novel approach for visual feature learning via image-conditioned masked diffusion LLMs. The motivation stems from the limitations of autoregressive captioning objectives, which provide an asymmetric learning signal: as the sequence progresses, the model increasingly relies on previously generated tokens rather than the image, diminishing the utility of the visual input for later tokens. MDC addresses this by leveraging masked diffusion language modeling, where the masking ratio is randomly sampled per training instance, ensuring a position-independent and consistent visual supervision signal across all tokens.
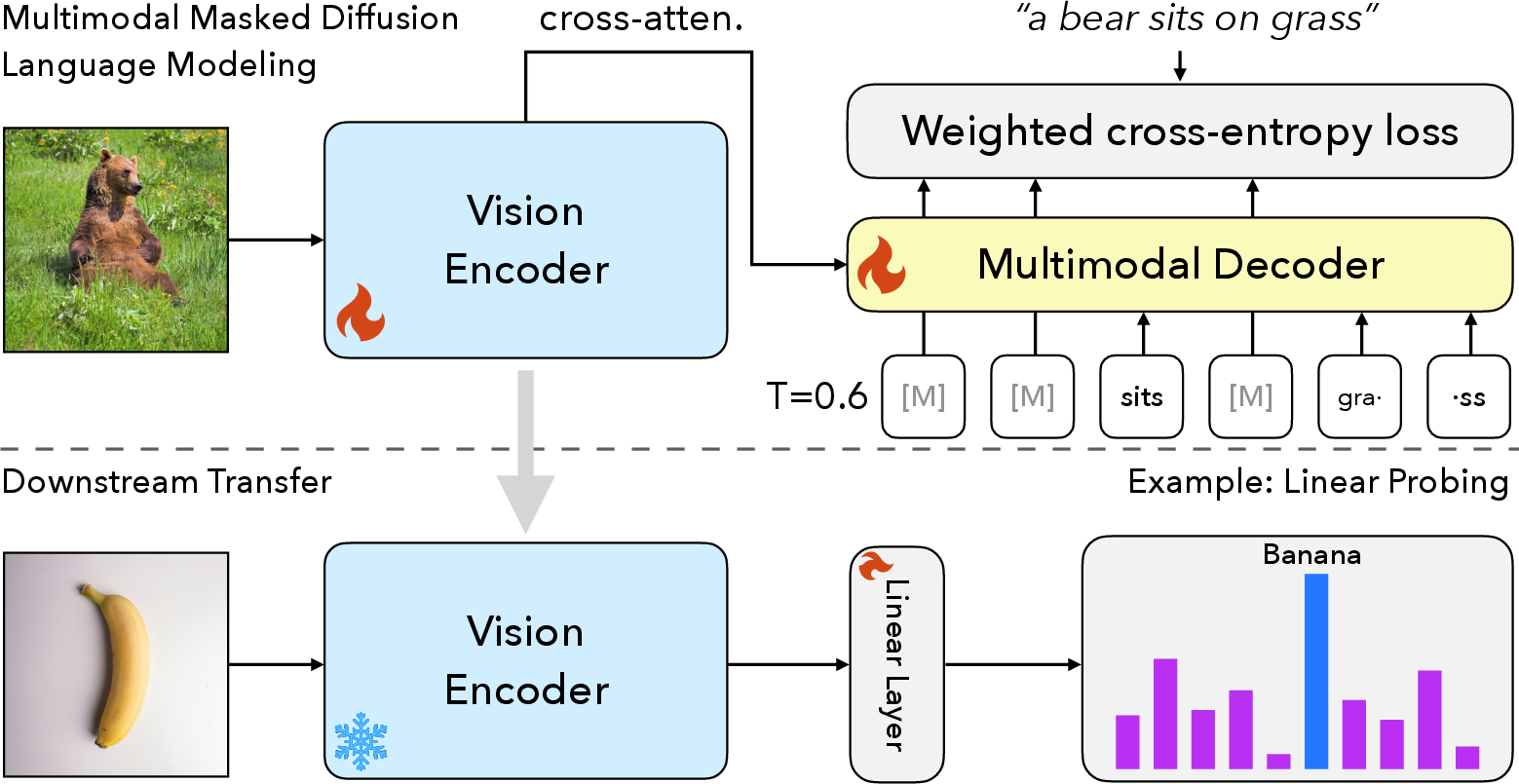
Figure 1: Learning visual features by masked diffusion language modeling. Visual features are learned by captioning images using an image-conditioned masked diffusion LLM, and the encoder's features are transferable to downstream computer vision tasks.
Methodology
Masked Diffusion Language Modeling
MDC builds upon the framework of masked diffusion LLMs (MDLMs), which generalize BERT-style masked language modeling into a generative process. In MDLMs, a forward process gradually corrupts the input sequence by masking tokens according to a noise schedule parameterized by t. The reverse process reconstructs the original sequence, and the model is trained to maximize the likelihood of the clean sequence given the corrupted input.
Image-Conditioned Captioning Architecture
The MDC architecture consists of a vision encoder fϕ and a Transformer-based text decoder gψ. The encoder extracts visual features from the input image, which are fused into the decoder via cross-attention. During training, a random masking ratio t is sampled, and the corresponding tokens in the caption are masked. The decoder is then tasked with reconstructing the original caption, conditioned on both the unmasked tokens and the visual features.
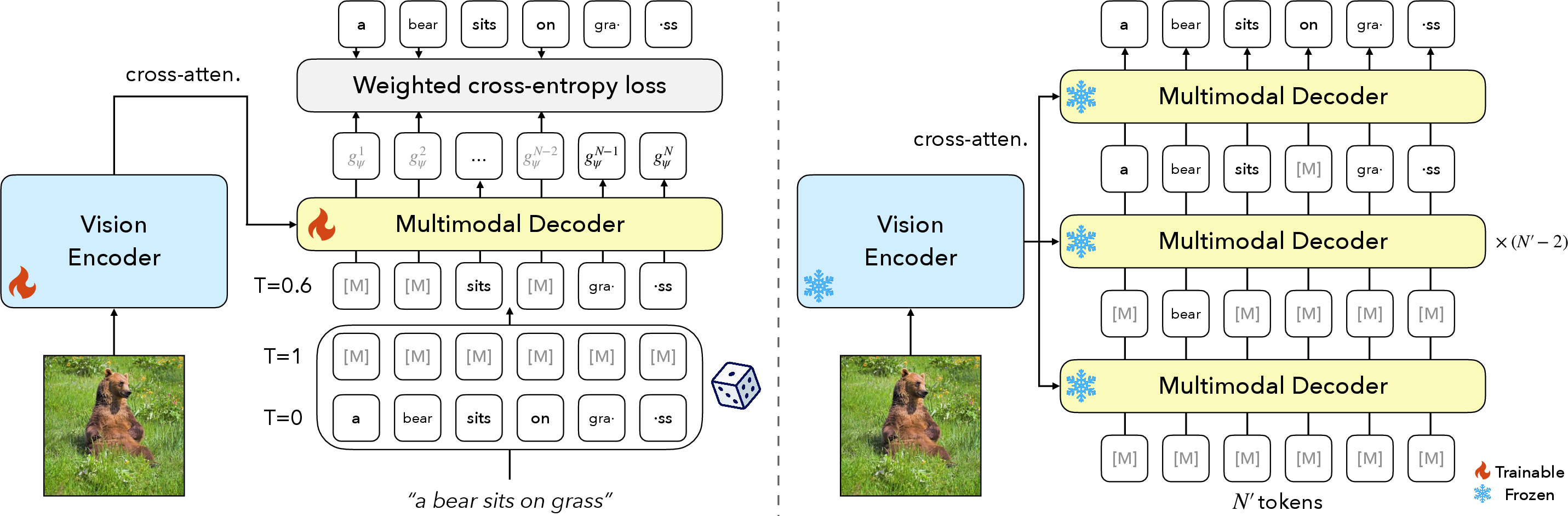
Figure 2: Learning visual features using masked diffusion captioning. (a) Training involves random masking of caption tokens and reconstruction via a visual feature-conditioned decoder. (b) Sampling starts from a fully masked sequence and iteratively denoises to produce a full caption.
The loss function incorporates a scaling factor dependent on t, which weights the cross-entropy loss for each masked token. This design ensures that the model learns to reconstruct captions from varying degrees of corruption, promoting robust feature learning.
Sampling and Decoding
At inference, MDC employs a greedy denoising strategy: starting from a fully masked sequence, the model iteratively reveals the token with the highest confidence at each step, until all tokens are unmasked. This approach avoids the numerical instability associated with Gumbel-based categorical sampling and ensures efficient caption generation.
Experimental Evaluation
Datasets and Pretraining
MDC is pretrained on several large-scale vision-language datasets, including CC3M, CC12M, and Recap-DataComp. Caption length distributions are visualized to highlight the diversity and richness of the textual descriptions.
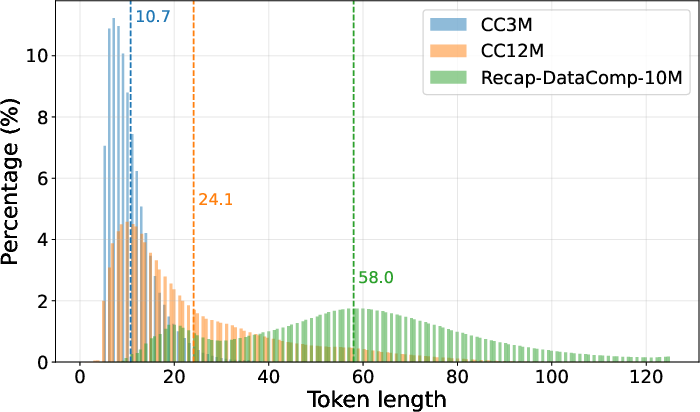
Figure 3: Dataset caption length distribution for CC3M, CC12M, and Recap-DataComp, illustrating the variability in caption lengths across datasets.
Linear Probing for Visual Feature Quality
Visual features learned by MDC are evaluated via linear probing on standard recognition benchmarks (ImageNet-1k, Food101, CIFAR-10/100, Pets). MDC consistently achieves accuracy competitive with autoregressive captioning and contrastive methods (e.g., CLIP), especially when trained on datasets with rich textual descriptions. Notably, MDC demonstrates strong performance even as the number of image-text pairs increases, indicating favorable scaling properties.
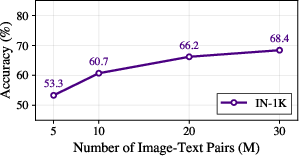
Figure 4: Linear probing performance with varying numbers of image–text pairs, showing improved accuracy on IN-1K as dataset size increases.
Comparison with Masked LLM Variants
MDC is compared against image-conditioned BERT models with fixed masking ratios. While BERT with high masking ratios can approach MDC's performance, MDC's unified time-based schedule obviates the need for dataset-specific tuning and consistently yields robust results.
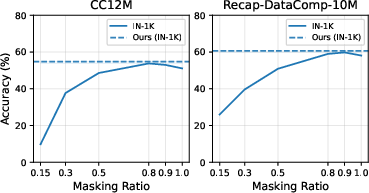
Figure 5: Comparison to image-conditioned BERT with different masking ratios. MDC avoids the need for masking ratio tuning and achieves superior or comparable performance.
Vision-Language Compositionality
MDC's ability to match images to captions is evaluated on compositionality benchmarks (ARO, SugarCrepe). Using the model's likelihood estimates or a heuristic denoising-based score, MDC outperforms both CLIP and autoregressive captioning in compositionality tasks, indicating that the learned representations capture complex image-text relationships beyond simple bag-of-words matching.
Image Captioning Quality
MDC is finetuned for image captioning on MSCOCO and Flickr30k. Despite the constraint of fixed output sequence length, MDC generates coherent and descriptive captions, as confirmed by both automatic metrics and LLM-based human preference evaluations.



Figure 6: Examples of captioning results from MSCOCO Karpathy-test split, illustrating MDC's ability to generate captions of varying lengths.
Analysis of Design Choices
Ablation studies confirm the necessity of the t-dependent loss scaling factor for effective feature learning. The choice of noise schedule (masking ratio interval) is critical, with higher lower bounds (e.g., [0.5,1.0]) yielding more stable training and better performance, especially for datasets with short captions.
Implications and Future Directions
MDC demonstrates that masked diffusion language modeling is a viable and competitive alternative to autoregressive and contrastive approaches for visual representation learning. The position-independent supervision signal and unified noise schedule simplify training and tuning, while enabling robust feature extraction and compositionality. The method scales favorably with dataset size and is adaptable to various encoder architectures.
Practically, MDC can be integrated into multimodal systems for tasks requiring strong visual representations, such as zero-shot recognition, compositional reasoning, and image captioning. Theoretically, the work suggests that generative masked modeling objectives can match or surpass discriminative and autoregressive paradigms in vision-language learning, especially when equipped with flexible noise schedules and efficient sampling strategies.
Future research may explore scaling MDC to larger model and dataset sizes, extending the approach to joint vision-language modeling (e.g., early fusion), and investigating its applicability to other modalities and generative tasks. Further analysis of the trade-offs between caption length, masking schedule, and downstream performance will be valuable for optimizing MDC in practical deployments.
Conclusion
Masked Diffusion Captioning provides a principled and effective framework for learning visual features from image-caption pairs. By leveraging masked diffusion language modeling with a unified noise schedule, MDC achieves competitive performance in visual recognition, compositionality, and caption generation, while simplifying training and hyperparameter tuning. The approach offers a promising direction for future multimodal representation learning research and applications.