- The paper presents a novel DD-MM-PAS framework that integrates demand detection, hierarchical long-term memory, and proactive execution to continuously infer latent user needs.
- The methodology leverages a dual-model streaming architecture (IntentFlow) with SFT and RL alignment, achieving an average intent prediction accuracy of 84.2% across diverse domains.
- Empirical results and user studies demonstrate robust multi-turn performance, low latency, and strong generalization in real-world scenarios requiring proactive intervention.
Proactive Intent-Aware Agents with Long-Term Memory: A Technical Analysis of "PASK: Toward Intent-Aware Proactive Agents with Long-Term Memory"
PASK addresses a core unsolved problem in agentic AI: real-world agents that can proactively reason about latent user needs, respond in real time, and adapt over long horizons using persistent memory. Existing LLM-driven assistants remain predominantly passive—reliant on explicit user interaction and limited prompt-based state without person-level history. This paradigm fails in scenarios requiring timely, context-sensitive intervention, or deep user modeling. PASK operationalizes proactivity as continuous demand inference, precise memory-based adaptation, and robust always-on deployment. The interaction objective is formalized as maximizing the expected utility of interventions, balancing helpfulness against intrusiveness under evolving uncertainty and latency constraints.
The DD-MM-PAS Paradigm: Unifying Proactivity, Memory, and Execution
The core architectural contribution is the DD-MM-PAS framework, which integrates three essential modules:
- Demand Detection (DD): Acts as a streaming engine continuously predicting latent user needs from multimodal context, enabling preemptive system-initiated assistance.
- Memory Module (MM): Introduces a three-tier hierarchical memory system (user/workspace/global) supporting persistent, person-level user model accumulation and retrieval at variable temporal scales.
- Proactive Agent System (PAS): Orchestrates end-to-end closed-loop operation—fusing real-time perception, concurrent task execution, and memory management.
This design is instantiated in PASK, which shifts the agent paradigm from isolated, reactive dialogue processors to "active initiators" capable of multi-domain proactive personalization—spanning professional, academic, and daily scenarios.
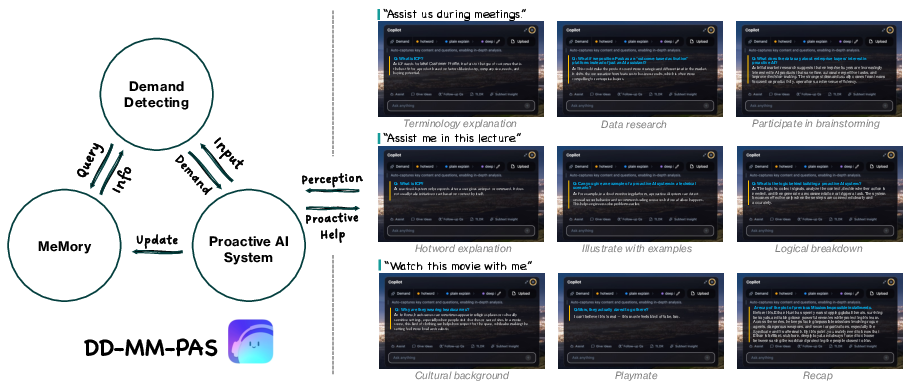
Figure 1: The DD-MM-PAS paradigm, showing its integrated demand detection, long-term memory, and always-on proactive agent execution loop.
IntentFlow: Streaming Demand Detection at Scale
IntentFlow, the specialized DD backbone, uses a dual-model streaming architecture—composed of a high-capacity Demand Detector (Qwen3-30B-A3B-Instruct for primary intent inference) and an auxiliary MemLoader (Qwen3-4B-Instruct for memory curation). At each interaction step, IntentFlow predicts one of three control signals: <silent>, <fast_intervention>, or <full_assistance>, thereby flexibly balancing non-intrusive silence, low-latency clarification, and context/memory-dependent deep intervention.
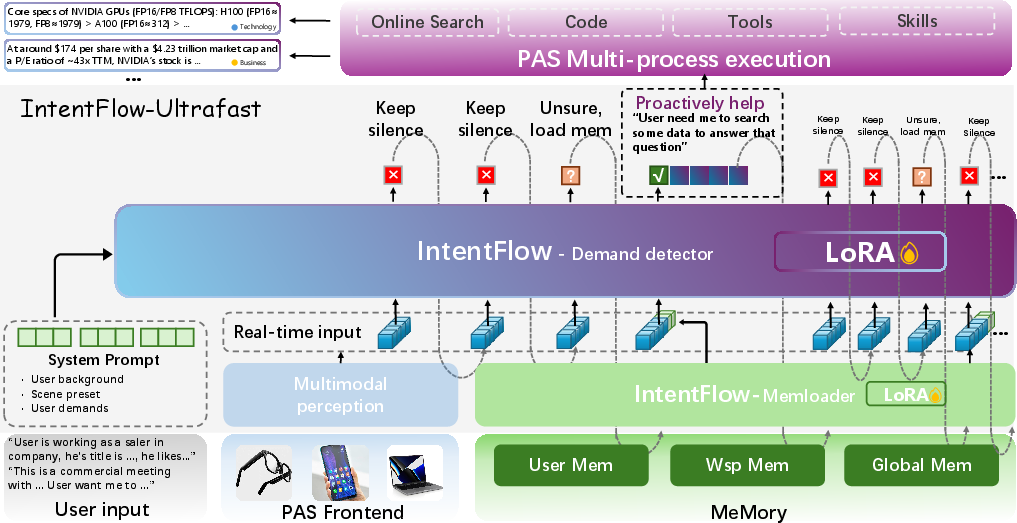
Figure 2: Architecture of IntentFlow, which processes streaming input fragments and decides per turn on whether and how to intervene, leveraging both workspace and external memory.
Control tokens determine the intervention path: <silent> suppresses unnecessary output; <fast_intervention> provides immediate local context assistance; <full_assistance> invokes the memory pipeline for deeper, multi-turn or contextually opaque inferences.
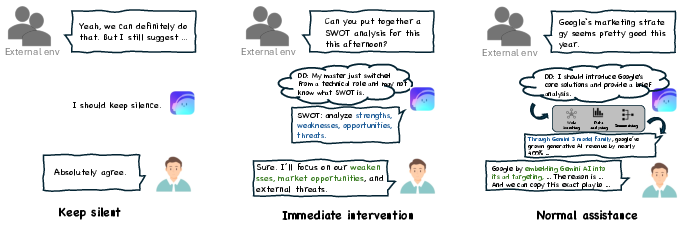
Figure 3: Intervention control by IntentFlow—examples of different system modes triggered by DD outcomes.
Data and Training Pipeline
IntentFlow is trained on LatentNeeds, a large-scale intent-annotated dataset (100k synthetic and curated, 2.1k real-world sessions). The training pipeline features SFT on LatentNeeds-100k and RL alignment on human-edited sessions, optimizing both immediate prediction and nuanced alignment with actual user demands. An LLM-as-a-judge protocol quantifies correctness along axes of reference congruence, contextual necessity, and plausibility.
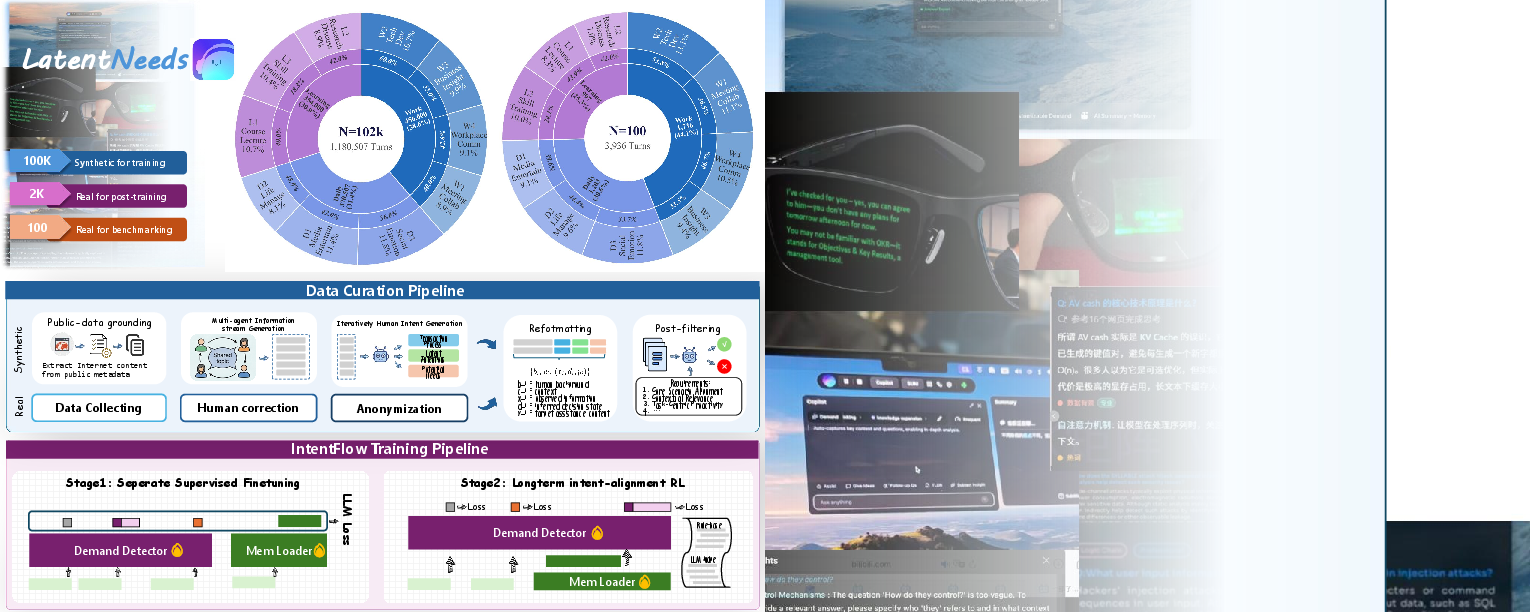
Figure 4: LatentNeeds dataset pipeline and training workflow—unifying synthetic and real-world session data for robust intent annotation and model alignment.
Hierarchical, Self-Evolving Memory: Pask-MM
Pask-MM models memory as a bounded, hierarchical structure with distinct user (cache), workspace (main memory), and global (external tree-structured storage) components:
- User Memory (Muser): Compact, high-priority background profile for prompt-level personalization.
- Workspace Memory (Mwsp): Low-latency, session-local state maintained throughout an active interaction.
- Global Memory (Mglobal): Persistent semantic tree supporting scalable retrieval and knowledge consolidation via localized RAG queries.
Updates are performed asynchronously post-session to ensure inference-time efficiency. New data are lazily merged; conflicts resolved and profiles decayed using Bayesian updates; and tree growth is bounded by depth and child thresholds, avoiding compute explosion typical of naive accumulation.
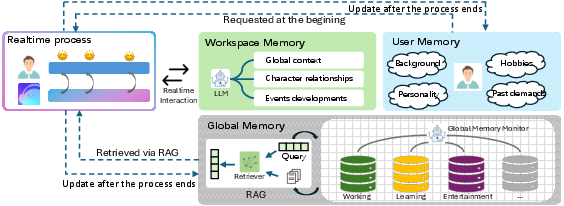
Figure 5: Internal architecture of Pask-MM, emphasizing memory partition, access/update protocol, and asynchronous scalable maintenance.
System Layer: Robust, Real-Time Proactive Infrastructure
Pask-PAS implements an end-to-end, always-on system. The frontend layer captures continuous multimodal signals (vision, audio, text) from user devices. The backend ensures persistent hot-state and object-store management, scalable scheduling, and agent isolation. The AI backend pools state-of-the-art foundation models across modalities for perception, understanding, and tool-augmented proactive action.
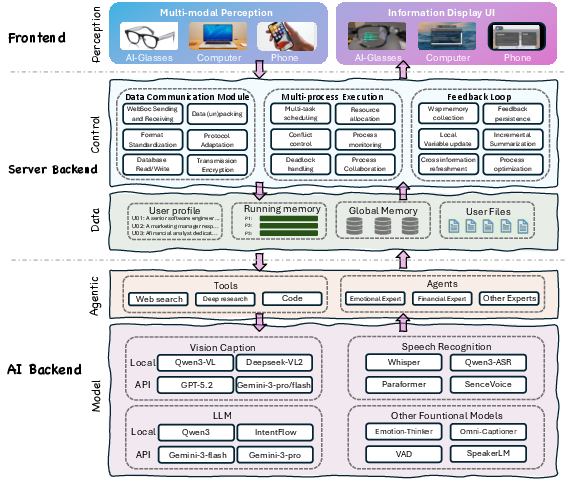
Figure 6: PAS system architecture: integrating frontend sensing, data/AI backends, and feedback-driven orchestration for real-world deployment.
Empirical Results
LatentNeeds-Bench and Main Findings
Evaluation on LatentNeeds-Bench (3,936 annotated multi-turn segments across work, learning, and daily domains) highlights the systemic limitations of most LM baselines. Even with large, prompt-optimized models, demand prediction accuracy on latent intent remains bottlenecked (e.g., Gemini-2.5-Flash-Lite: 18.8%). Only advanced closed models (Gemini-3-Flash: 83.3%; GPT-5-Mini: 66.5%; GPT-5-Nano: 71.2%) approach useful performance. IntentFlow, using targeted SFT+RL, achieves the best balanced average accuracy (84.2%), outperforming Gemini-3-Flash by 3.4 points, with highly competitive Demand (83.1%) and No-Demand (85.2%) splits.
Cross-Domain and Demand-Type Analysis
Closed models still dominate knowledge-centric and high-value domains (work, learning), but IntentFlow demonstrates superior generalization in open-ended daily tasks and maintains strong parity in both requirement and insight demand types, indicating robust calibration across proactive behavior spectra.
Multi-Turn and Latency Robustness
In extended (up to 60 turns, ~30 minutes) sessions, IntentFlow exhibits minimal performance drift (<5% degradation), contrasting with baseline models that show severe long-context regression (e.g., GPT-5-Mini: --19.0%; Gemini-3-Flash: --17.3%). Latency is consistently sub-1.5s per turn for IntentFlow—a critical advantage for real-time agentic deployment.
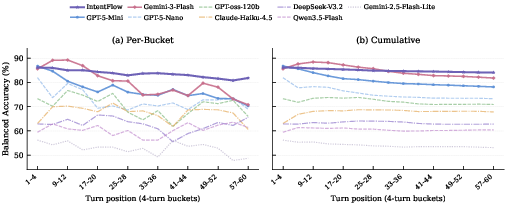
Figure 7: Multi-turn balanced accuracy: IntentFlow maintains >80% across all interaction depths, outperforming other baselines as session context accumulates.
Qualitative Case and User Study Analyses
Long-term memory impact is validated via user study and case-driven evaluation. Memory enables:
- Persistent user background modeling (roles, routines).
- Episodic fact recall for consistent assistance.
- Preference tracking for personalization.
Learning scenarios elicit highest user satisfaction; daily tasks prove inherently more open-ended and challenging—implicating required advances in context synthesis and character-level adaptation.
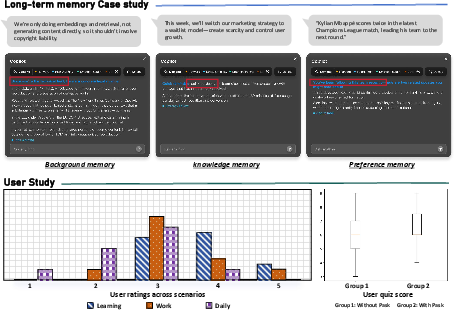
Figure 8: Three functional long-term memory case studies and user study outcomes, highlighting the benefits and current limitations of persistent agent-side memory.
Theoretical and Practical Implications
PASK demonstrates that robust proactivity emerges only from the tight coupling of intent-aware demand detection, structured long-term memory, and real-time system infrastructure—not from raw model scaling alone. The observed domain gap implies the need for domain-adaptive, memory-influenced agent tuning. Novel RL-based alignment with multi-criteria reward functions substantially narrows the closed-vs-open source model performance gap. The DD-MM-PAS architecture provides a minimally sufficient—and extensible—template for AGI systems aiming for genuine human-level adaptation over time.
Key outstanding directions include:
- Richer multimodal signal fusion for non-verbal/contextual inference.
- More granular memory abstraction for fine-tuned, latent need detection.
- Advanced conflict resolution and drift accommodation for lifelong deployment.
Conclusion
PASK constitutes a comprehensive, scalable recipe for deploying intent-aware, memory-augmented, proactive agentic AI under real-world latency and uncertainty constraints. By combining a unified framework, tailored streaming models, and long-term adaptive memory strategies, it pushes agent design beyond surface-level proactivity toward deep, contextually grounded, and persistent human-aligned assistance. While not closing the full gap to human predictive nuance, the framework, dataset, and empirical results set a new bar for research on agentic proactivity and long-horizon human–AI co-evolution.
(2604.08000)