- The paper demonstrates that Sinkhorn normalization preserves matrix rank significantly better than Softmax-based attention in deep Transformers.
- It introduces a rigorous theoretical framework using path decomposition to derive norm bounds that reveal a doubly exponential decay of residual components.
- Empirical evaluations on text and vision tasks confirm that doubly stochastic attention delays rank collapse, fostering stable and diverse representations.
Introduction and Motivation
This work addresses the structural limitations of self-attention mechanisms in Transformers, specifically the problem of rank collapse and entropy collapse in signal propagation across deep architectures. Empirical and theoretical studies have demonstrated that standard row-stochastic self-attention (i.e., Softmax-normalized attention mechanisms) exhibit rapid loss of information, with attention matrices converging towards low rank, eventually reducing sequence representations to near-uniformity as depth increases. Furthermore, the tendency for attention distributions to become highly concentrated (i.e., entropy collapse) impairs both learning stability and expressivity.
Building upon recent advances which highlight that constraining attention to be doubly stochastic (using the Sinkhorn algorithm) acts as effective entropy regularization, this paper provides the first direct and quantitative comparison of the rate and structural properties of rank decay for doubly stochastic versus row-stochastic attention mechanisms, both theoretically and empirically. The key claim is that Sinkhorn-normalized attention preserves rank significantly better than Softmax-based counterparts, though both ultimately suffer rank collapse doubly exponentially with depth in pure self-attention stacks.
Theoretical Analysis of Rank Decay
The authors develop a rigorous analytical framework to examine the progression of rank collapse. Let X∈Rn×d denote the token representations and P the attention matrix; under Sinkhorn normalization, P is doubly stochastic (P1=1, 1⊤P=1⊤). Using path decomposition, the output of an L-layer multi-head self-attention network can be represented as a sum over products of attention matrices across “paths” (i.e., sequences of selected heads per layer). Theoretical results from the stochastic matrix literature guarantee that repeated products of such (doubly) stochastic matrices converge toward a rank-one matrix at an exponential rate under mixing/ergodicity conditions.
The authors refine this with new norm bounds for the spectral decay of the “residual” component—the difference between the current representation and its best rank-one approximation. For pure self-attention (i.e., omitting feed-forward networks and skip connections), they prove that for a multi-layer, multi-head SAN with Sinkhorn normalization, the spectral norm of the residual decays as:
∥res(SAN(X))∥2≤C3L−1/2∥res(X)∥23L
where C<1 is a constant depending inversely on the sequence length n, dimension dqk, number of heads P0, and operator norms of the projection weights. This doubly exponential rate matches prior results for the Softmax case, but the crucial empirical question is how quickly the decay manifests in practical settings.
Empirical Evaluation: Softmax vs. Sinkhorn Normalization
The analysis is complemented with extensive experiments on both text (AG's News) and vision data (MNIST, Cats & Dogs) in diverse Transformer architectures, with Softmax and Sinkhorn normalization directly compared. Key metrics include the normalized spectral norm of the residual for products of sampled attention matrices across randomly chosen “paths” of varying depths, and the layerwise decay of the SAN output's rank.
Notably, attention maps of the first ViT layer reveal that Softmax attention is highly focused, attending primarily to a few key tokens, whereas Sinkhorn attention distributes weights much more evenly across tokens—as illustrated below.
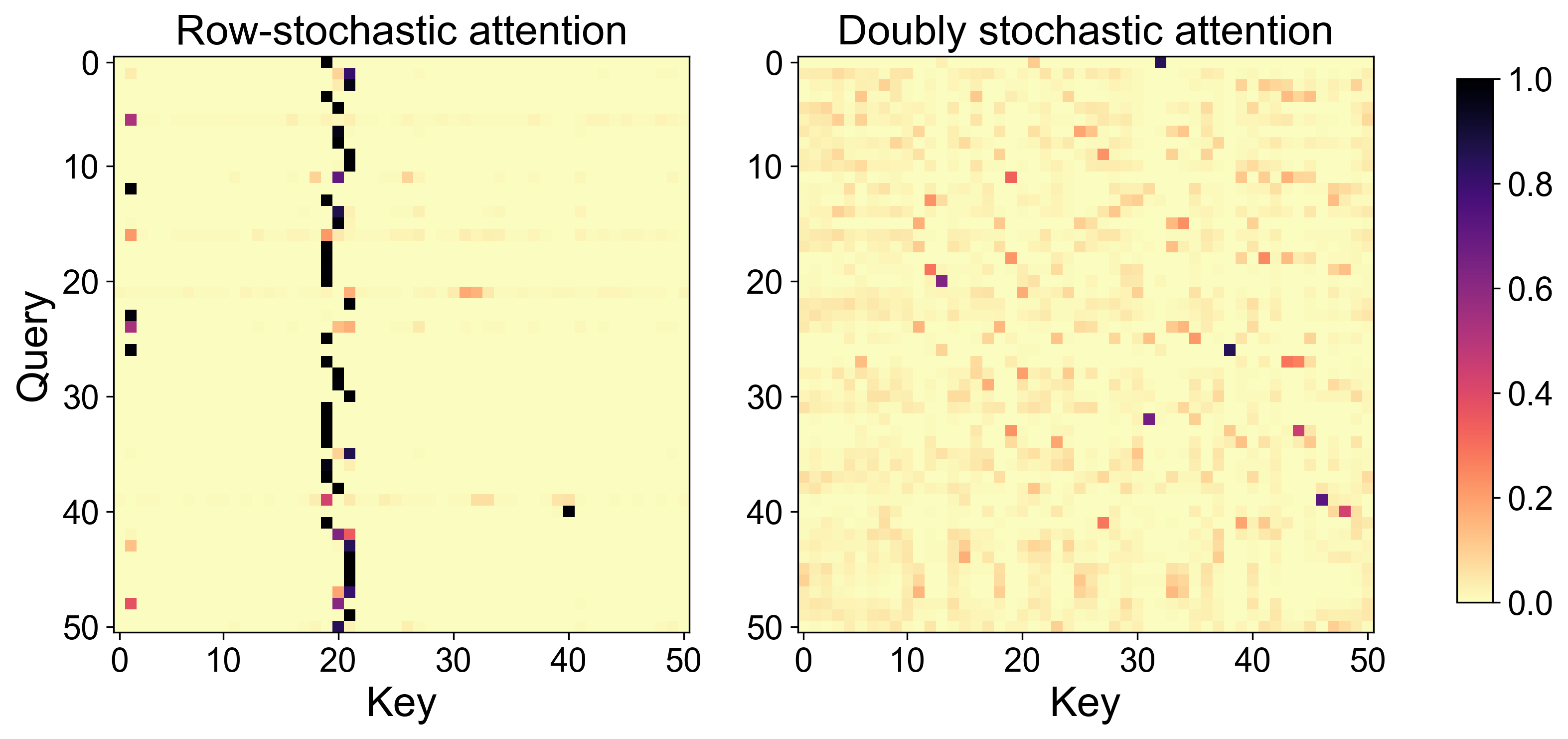
Figure 1: Attention matrices from the first layer and a single attention head of a Vision Transformer. Row-stochastic (Softmax) attention is sparse, while Sinkhorn (doubly stochastic) distributes attention more uniformly.
Quantitative results for rank collapse along sampled attention paths in a trained Transformer on AG’s News show a clear, measurable difference between the two normalizations.
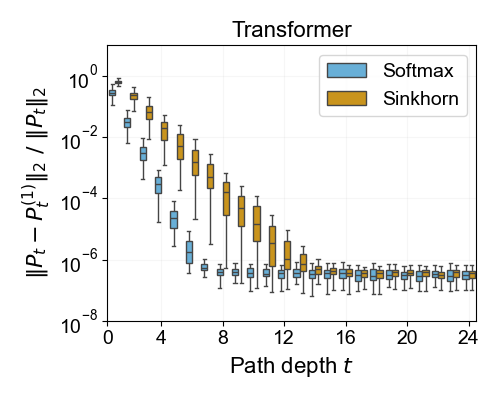
Figure 2: Rank collapse for the product of attention matrices in a sampled path; Sinkhorn normalization sustains higher rank across depth compared to Softmax normalization.
Further evidence from training on AG's News data, measuring the normalized spectral norm of the residual for SAN outputs at each layer, demonstrates that skip connections are critical for mitigating rank decay; with skip connections enabled, Sinkhorn normalization confers a distinct advantage.
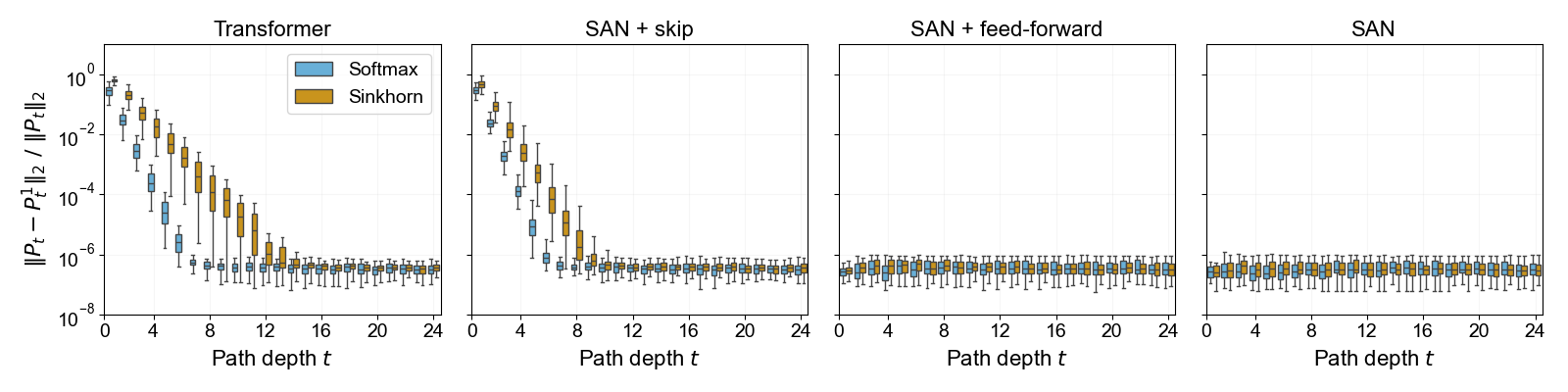
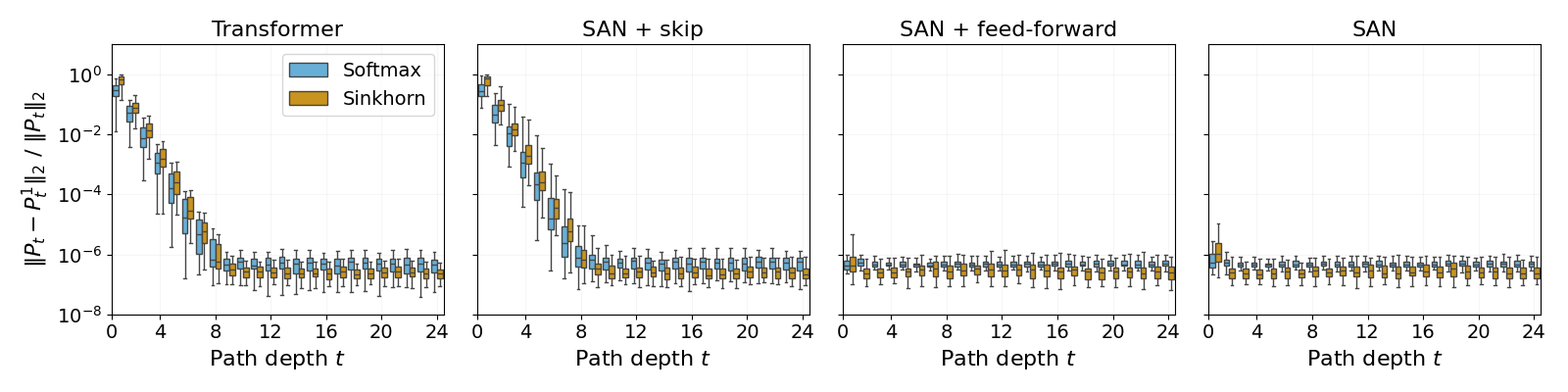
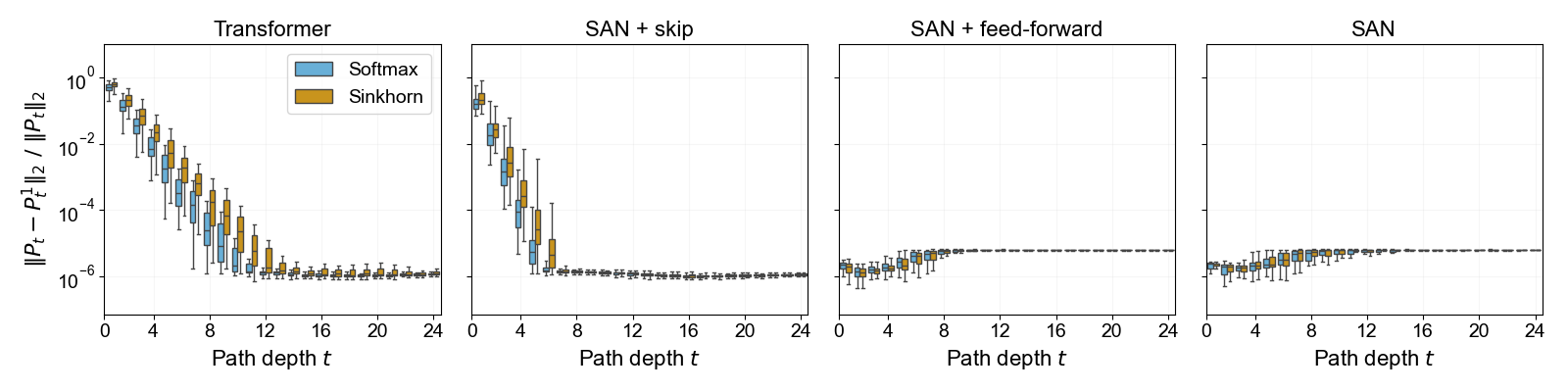
Figure 3: Layerwise rank decay of self-attention outputs in a Transformer on AG's News; doubly stochastic normalization with Sinkhorn sustains higher effective rank.
This effect is robust across vision tasks as well, as shown for MNIST and Cats & Dogs, though the magnitude and visibility of the advantage may vary depending on task and architecture, and becomes most pronounced in language modeling scenarios.
Practical Implications and Connections
The findings are significant for Transformer design. Doubly stochastic attention mitigates rank collapse, promoting better information propagation and richer representations particularly in very deep models. This supports prior reports that Sinkhorn-based (and similar optimal transport-inspired) attention mechanisms yield empirical performance benefits in NLP and vision tasks.
Moreover, analysis of random (uncorrelated) stochastic matrix products reveals no difference between Softmax and Sinkhorn in terms of rank decay, implicating the inter-layer correlation of attention in Transformers as pivotal. This suggests architectural or training factors that encourage correlation or structure in attention evolution may further influence expressivity and optimization dynamics.
On the theoretical side, the work refines quantitative understanding of signal propagation, showing that the faster collapse in Transformers (cubic in each layer) is a direct consequence of the compositional dependency of the attention matrix on its own input—distinct from the classical exponential convergence results for fixed, independent stochastic matrices.
Future Directions
The authors suggest promising directions for future research. One is the investigation of the Lipschitz properties of Sinkhorn-normalized attention (as has recently been rigorously established for Softmax), with potential implications for stability, adversarial robustness, and implicit regularization. Another is the development of computationally efficient and robust alternatives to iterative Sinkhorn normalization, and the systematic exploration of connections between doubly stochastic attention and quantum-inspired or optimal transport-based mechanisms—already being actively pursued in recent literature.
Conclusion
This work contributes both new theory and empirical evidence underscoring the importance of doubly stochastic normalization in deep Transformer architectures. While rank collapse in multilayer self-attention is ultimately inevitable in the absence of skip connections and feed-forward layers, Sinkhorn normalization demonstrably delays this process, fosters representation diversity, and promotes more stable and expressive learning, especially in deep and data-rich regimes. The results justify the increasing popularity of doubly stochastic attention and should inform both architecture design and foundational analysis in future neural sequence models.