Analyzing the Mechanism of Attention Collapse in VGGT from a Dynamics Perspective
Abstract: Visual Geometry Grounded Transformer (VGGT) delivers state-of-the-art feed-forward 3D reconstruction, yet its global self-attention layer suffers from a drastic collapse phenomenon when the input sequence exceeds a few hundred frames: attention matrices rapidly become near rank-one, token geometry degenerates to an almost one-dimensional subspace, and reconstruction error accumulates super-linearly.In this report,we establish a rigorous mathematical explanation of the collapse by viewing the global-attention iteration as a degenerate diffusion process.We prove that,in VGGT, the token-feature flow converges toward a Dirac-type measure at a $O(1/L)$ rate, where $L$ is the layer index, yielding a closed-form mean-field partial differential equation that precisely predicts the empirically observed rank profile.The theory quantitatively matches the attention-heat-map evolution and a series of experiments outcomes reported in relevant works and explains why its token-merging remedy -- which periodically removes redundant tokens -- slows the effective diffusion coefficient and thereby delays collapse without additional training.We believe the analysis provides a principled lens for interpreting future scalable 3D-vision transformers,and we highlight its potential for multi-modal generalization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper studies why a powerful AI model for 3D reconstruction, called VGGT, starts to “lose focus” when you feed it very long video sequences or many photos. The authors discover and explain a problem they call attention collapse: as the model goes deeper, its attention starts treating many different image pieces as if they were the same, which hurts 3D accuracy. They also explain why a simple trick called token merging (combining similar pieces) helps both speed and stability—and they back it up with math and experiments.
The main questions the paper asks
- Why does VGGT’s global attention “collapse” (treat many tokens the same) when sequences get long or the network gets deep?
- Can we describe this collapse with a simple, accurate theory?
- Why does token merging, a practical speed-up trick, also delay this collapse and improve results without retraining?
How they studied it (methods made friendly)
First, some plain-language translations:
- Token: a small chunk of information (like a patch from an image). A sequence of tokens describes many frames.
- Attention: a way the model decides which tokens should “look at” or “listen to” which other tokens.
- Global attention: every token can talk to every other token. Powerful, but expensive.
- Attention collapse: the attention maps become almost the same everywhere—like a classroom where eventually everyone listens to the same one person, no matter the topic.
What they did:
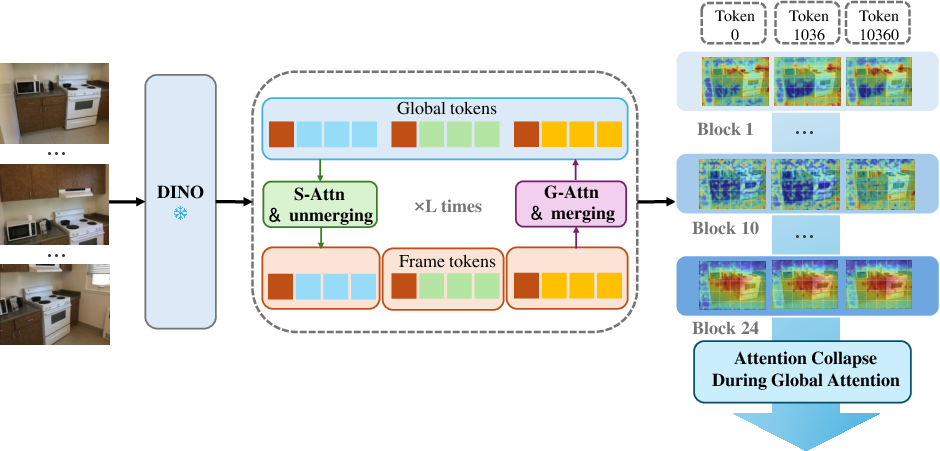
- They look at VGGT’s global attention blocks layer by layer and notice that, as depth increases, the attention heatmaps become more uniform. In other words, many different tokens end up focusing on the same places.
- They build a mathematical model that treats the change of token features across layers like a special kind of “flow.” An easy way to picture it: imagine marbles on a curved surface slowly rolling into the same pit until they all bunch together. In the math, this bunching means the features become nearly identical.
- They use two simple measurements to track collapse:
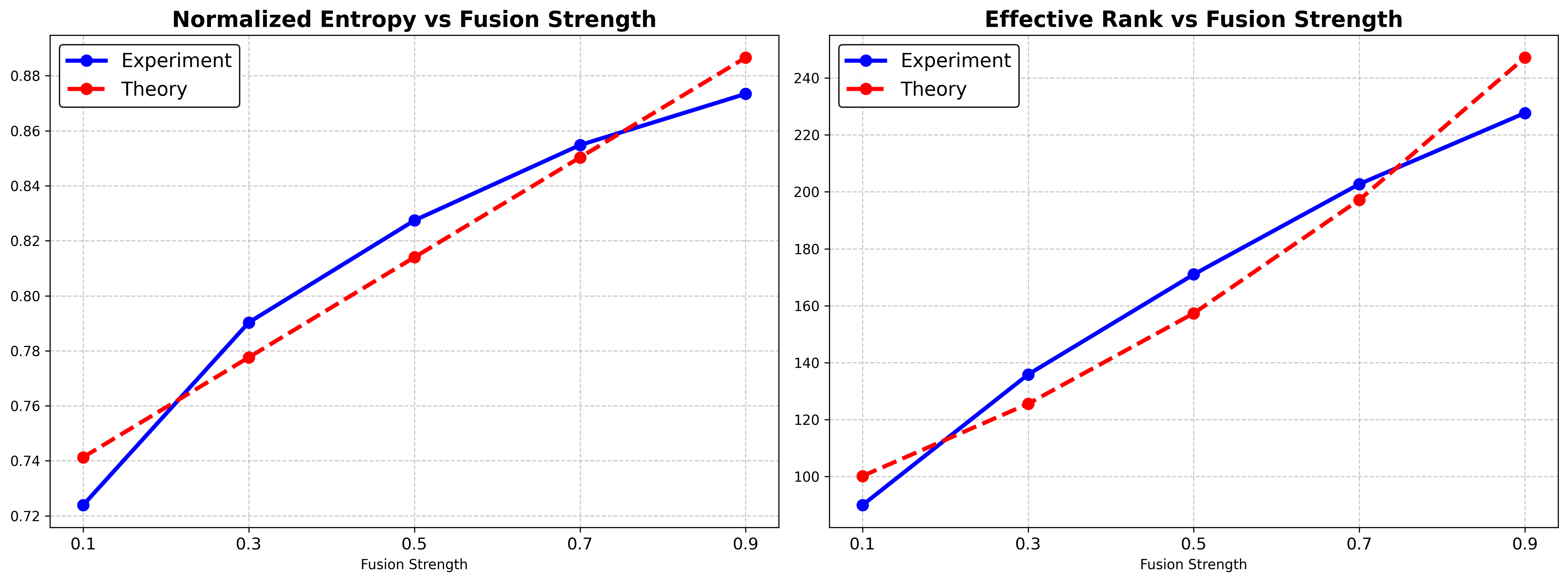
- Entropy (variety): high entropy means diverse attention; low entropy means attention has become uniform.
- Effective rank (how many distinct patterns remain): higher rank means more variety; rank near 1 means almost everything is the same.
- They study token merging (combining very similar tokens into one). Intuitively, this reduces how many total tokens there are, which changes how quickly the “everyone copies everyone” effect spreads. In the marble picture, merging lowers how fast the marbles roll into the same pit.
- They test their predictions on a standard 3D dataset (ScanNet-50), comparing the theory to actual measurements from the model.
What they found and why it matters
Here are the key findings, explained simply:
- Attention naturally collapses in deep global-attention stacks: as you add layers or more frames, attention maps become uniform and token features become too similar. That makes the model forget fine details like edges, surface changes, and exact camera motion, which are crucial for accurate 3D.
- Their theory predicts the speed of collapse: it shows that, layer by layer, tokens drift toward “all looking the same,” and it quantifies how fast this happens. The predicted curves for entropy and rank match what they measure in the real model.
- Token merging slows the collapse and speeds up the model:
- Slower collapse: merging reduces the “everyone influences everyone” effect, keeping attention more diverse for longer. That preserves fine geometric details.
- Faster inference: global attention compares every token with every other token, which costs about “number of tokens squared.” If you cut tokens by 10×, those pairwise comparisons drop by about 100×. In practice, they report big speedups (up to around 8×) for long sequences, even after accounting for overhead.
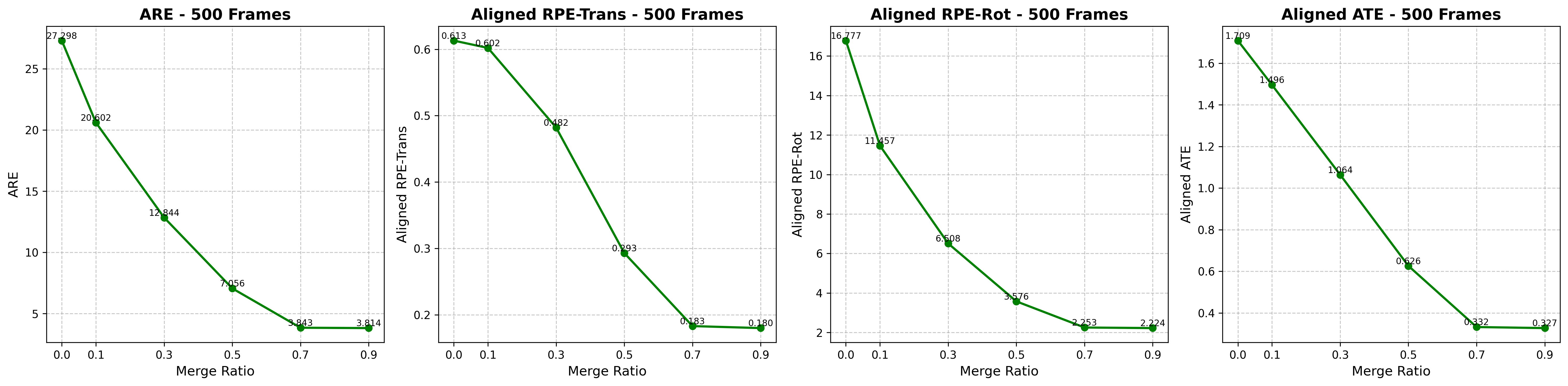
- Better 3D results on long sequences: with merging, camera pose errors and trajectory drift go down, and reconstructions look sharper and more stable. This matches the theory: keeping attention diverse helps the model keep precise geometry.
Why this work matters (impact and takeaways)
- A clear explanation for a common failure mode: The paper gives a simple, principled reason for why big attention models in 3D vision can “collapse” on long inputs. This helps engineers know what to watch for and how to fix it.
- Practical guidance for speed and stability: Token merging isn’t just a speed trick—it also delays collapse. This means you can process longer videos faster and still keep good 3D accuracy, without retraining the model.
- A roadmap for future transformers: The same ideas could help design stable, scalable models for other long-input vision or multi‑modal tasks. For example, you could adapt how much you merge based on a live “collapse meter” (like monitoring entropy), keeping the model fast and focused at the same time.
In one sentence
The paper shows that VGGT’s global attention tends to make all tokens act alike as depth grows, hurting 3D quality; a simple math model explains this, and token merging both slows the problem and massively speeds up the model—leading to better, faster 3D reconstruction on long sequences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, framed as concrete directions future researchers can act on:
- Missing architectural fidelity in the theory: the update analysis omits residual connections, layer normalization, MLP blocks, positional encodings, and multi-head specifics. Provide a fully rigorous derivation that includes these components and quantify their stabilizing or destabilizing effects on collapse.
- Rate inconsistency to resolve: the paper states an convergence in the abstract/entropy section but uses exponential rank decay in Section 3.1. Derive and reconcile a unified, parameterized rate law for rank/entropy collapse under VGGT-like architectures.
- Query–key initialization assumption: the assumption that under DINOv2 initialization is untested and architecture-dependent. Empirically verify this across layers/heads and generalize the theory to non-isotropic or non-DINO initializations and different backbones.
- Finite-token corrections: the mean-field PDE assumes . Derive finite- corrections and bounds for realistic token counts, and quantify how finite-size effects alter collapse time and steady-state behavior.
- Alternating global/local attention and un/merging dynamics: the model analyzes global attention in isolation. Develop a composite dynamical model that includes local attention, periodic merging/unmerging, and their interaction, and test whether alternation introduces nontrivial steady states that avoid full collapse.
- Anisotropic/adaptive diffusion: extend the PDE to anisotropic diffusion induced by layer norm, per-head temperatures, attention masks, and head specialization. Identify conditions under which anisotropy arrests or reverses collapse.
- Training-time dynamics: incorporate training-time gradients, geometry losses, and optimizer noise into the framework to explain how training reshapes diffusion coefficients or introduces non-Dirac steady states.
- Formal relation between fusion strength and downsampling: the mapping is asserted but not derived or validated across merging algorithms. Precisely characterize how different merging heuristics (e.g., ToMe, FastVGGT rules) alter the effective diffusion mobility and token distribution.
- Quantitative accuracy–efficiency trade-off: provide an explicit optimization framework to choose given a compute budget and target metrics (ARE, RPE, ATE), including theoretical error bounds introduced by merging and empirical validation across diverse scenarios.
- Reconstruction error linkage: rigorously model the causal relationship between attention entropy/rank and downstream geometric errors (ARE/RPE/ATE), including confidence intervals, thresholds, and cross-dataset generalization (beyond the reported entropy ≥ 0.8 → ATE ≤ 0.2 correlation).
- Dataset and scene diversity: evaluate the theory on outdoor scenes, dynamic/non-rigid objects, low-texture regions, motion blur, and occlusions to assess robustness of the diffusion-collapse explanation and merging strategy.
- Multi-modal generalization: extend the PDE to include cross-modal tokens (e.g., RGB-D, video+IMU, language) and characterize how inter-modal coupling terms affect diffusion, collapse rates, and steady states.
- Role of positional encodings and camera tokens: theoretically and empirically assess whether positional/camera tokens act as geometric anchors that slow or prevent collapse; quantify their impact on diffusion coefficients and rank profiles.
- Hyperparameter sensitivity: characterize collapse dependence on depth , number of heads, embedding dimension, softmax temperature, and attention masks. Derive critical thresholds (e.g., token count vs. depth) that predict onset of collapse.
- Alternative remedies in PDE terms: interpret entropy regularization, sparse/windowed attention, and FlashAttention-like kernels as modifications to the diffusion/drift terms; predict and compare their expected effects on collapse rate and computational complexity versus token merging.
- Adaptive/online control: design layer-wise controllers that adjust merging strength using real-time entropy/rank feedback; analyze stability guarantees and evaluate on long sequences in streaming/online settings.
- Information loss in periodic unmerging: quantify the irreversibility or error introduced by merge–unmerge cycles; provide bounds on geometric fidelity loss and propose improved reversible compression schemes.
- Parameter identification protocol: detail a reproducible method to estimate model parameters (e.g., , diffusion coefficients, ) from attention matrices; report variability across seeds, scenes, and datasets.
- Theoretical guarantees under full VGGT: prove uniqueness/stability of steady states (Dirac or otherwise) for the full architecture with residuals/MLPs; identify regimes where non-collapsed equilibria exist and conditions that guarantee avoidance of rank-one attention.
- Softmax temperature and normalization effects: analyze how temperature scaling and feature norm growth alter diffusion mobility; test whether temperature annealing or norm constraints can systematically prevent collapse.
- Attention masks and structured sparsity: incorporate causal/windowed masks into the theory; derive how sparsity patterns affect collapse rates and complexity, and validate with controlled experiments.
- Extremely long sequences: empirically test sequences well beyond 1000 frames to verify whether the predicted scaling persists; characterize failure modes and memory/runtime behavior at extreme lengths.
- Memory footprint and I/O: quantify memory savings and bandwidth/I/O overhead as a function of ; model deviations from the ideal runtime due to implementation and system-level effects.
- Reproducibility and reporting: release code/data and specify merging heuristics, constants, and measurement pipelines (e.g., entropy/rank definitions) to enable independent verification and sensitivity analysis.
Practical Applications
Immediate Applications
The following applications can be deployed with existing VGGT/FastVGGT models and standard ML tooling, leveraging the paper’s diffusion-based understanding of attention collapse and training-free token merging.
- Software/ML Infrastructure — Production inference acceleration for 3D reconstruction
- Use case: Speed up VGGT-style global attention on long sequences (hundreds to thousands of frames) in cloud or on-prem deployments by applying training-free token merging with reference-frame protection and salient-token preservation.
- Workflow: Select a merge ratio or down-sampling factor ; instrument attention-entropy and effective-rank monitors; apply merging in global attention blocks; optionally combine with FlashAttention/windowed attention.
- Impact: Near-quadratic cost reduction in attention from to ; reduced memory footprint and improved stability on long inputs.
- Assumptions/dependencies: VGGT-like global attention; DINOv2-style initialization; correct preservation of geometric anchor tokens; moderate to avoid over-merging.
- Robotics, Drones, Autonomous Systems — Real-time online multi-view reconstruction and SLAM
- Use case: Stabilize long-sequence inference (e.g., warehouse robots, aerial inspection, autonomous mapping) by delaying collapse via merging; maintain high feature diversity to reduce pose drift (ATE/RPE improvements).
- Workflow: Adaptive merge schedules based on sequence length and entropy thresholds; alternating merge/unmerge to compress redundancy while preserving local detail.
- Assumptions/dependencies: Accurate camera intrinsics/extrinsics; robust salient-token shielding; sufficient compute for feed-forward reconstruction on-device or edge servers.
- AEC, Surveying, Digital Twins — Large-scale indoor scanning and rapid scene digitization
- Use case: Enable fast, robust creation of building-scale digital twins from long RGB sequences; reduce cloud cost and turn-around time.
- Workflow: Pre-inference calibration to choose by sequence length (e.g., for <200 frames; for >500 frames); monitor entropy/rank to keep above accuracy thresholds (e.g., normalized entropy > 0.8).
- Assumptions/dependencies: Consistent scene coverage; proper reference-frame protection; acceptance of minor loss in very fine details at higher .
- AR/VR, E-commerce, VFX — Consumer-scale 3D scanning and content creation
- Use case: Run VGGT-like models on mobile/edge devices for longer scans without collapse; accelerate asset creation for virtual staging, product models, and effects.
- Workflow: On-device merging (with unmerging for local refinement), entropy-aware capture guidance (alerts when collapse risk rises), and energy-aware inference.
- Assumptions/dependencies: Mobile-compatible models and kernels (e.g., quantized attention, FlashAttention variants); battery and thermal constraints.
- Healthcare Imaging (pilot use) — Stabilized 3D reconstruction from long video (e.g., endoscopy, ultrasound probes)
- Use case: Reduce super-linear error accumulation in long clinical sequences and maintain geometric fidelity without retraining.
- Workflow: Training-free merging applied at inference; entropy/rank monitoring as a safety/quality signal; clinician-facing flags when geometry stability degrades.
- Assumptions/dependencies: Domain validation and QA; device-specific tokenization; potential regulatory review for clinical deployment.
- MLOps/Quality Assurance — Attention-collapse diagnostics and guardrails
- Use case: Detect and prevent collapse in long-sequence workloads via real-time metrics (attention entropy decay, effective rank).
- Workflow: Instrument transformer blocks; define thresholds; auto-adjust or switch to local/windowed attention when collapse is imminent.
- Assumptions/dependencies: Access to attention matrices at inference; lightweight telemetry; policy for automatic intervention.
- Cost and Energy Management — Compute budgeting for long-sequence workloads
- Use case: Reduce GPU-hours and carbon footprint in 3D reconstruction services by applying the scaling law to capacity planning.
- Workflow: Model demand curves vs. merge factor; pick to meet SLA while keeping geometric error within acceptable bounds.
- Assumptions/dependencies: Reliable performance-vs- curves for target datasets; GPU scheduler support; acceptance of small accuracy trade-offs at higher compression.
- Academia/Education — Theory-informed benchmarking and teaching
- Use case: Use the mean-field PDE predictions to design experiments and assignments (entropy/rank decay vs. ATE/RPE), reproducing collapse and mitigation.
- Workflow: Public benchmarks with entropy/rank logging; classroom labs linking diffusion equations to transformer dynamics.
- Assumptions/dependencies: Access to pre-trained backbones; reproducible logging of attention statistics.
Long-Term Applications
These applications require further research, integration, or domain validation to mature into reliable products and standards.
- Adaptive Controllers for Attention Mobility — Closed-loop collapse avoidance
- Use case: Learn controllers that modulate head-by-head and layer-by-layer using entropy/rank feedback to keep attention in a non-degenerate regime.
- Potential tools: “Collapse Monitor & Controller” libraries integrated with PyTorch/TF; policies that adjust merge strength, window sizes, or sparsity patterns.
- Dependencies: Robust online metrics; latency-tolerant control loops; safety proofs for stability.
- PDE-informed Transformer Design — Architecture co-design with diffusion regularization
- Use case: Build attention kernels and residual paths that explicitly counteract the degenerate diffusion toward Dirac measures; integrate entropy regularizers at train time.
- Potential products: “Diffusion-regularized attention” blocks; training recipes combining token merging with skip-MLP, windowed masks, or entropy penalties.
- Dependencies: Retraining large models; theoretical guarantees under realistic initializations (beyond ); benchmarking across domains.
- Continuous/Streaming 3D Perception — Persistent-state models at city/building scale
- Use case: Collapse-aware token pooling in streaming architectures (e.g., persistent memory or camera token pools) for continuous mapping and digital twins.
- Potential workflows: Dynamic merging/unmerging with memory compaction; multi-session scene fusion with collapse-aware scheduling.
- Dependencies: Scalable datasets; persistent-state training; multi-session consistency constraints.
- Multi-modal Fusion (Vision–LiDAR–IMU–Text) — Collapse-aware long-sequence integration
- Use case: Extend the PDE framework to cross-modal attention, adding anisotropic diffusion terms for modality-specific dynamics in autonomous driving and robotics.
- Potential tools: Modality-conditioned merging; cross-modal anchor preservation; structured sparse attention guided by geometry.
- Dependencies: New theory for anisotropic/adaptive diffusion; multi-modal datasets; calibration pipelines.
- Healthcare-grade Reconstruction Pipelines — Regulated deployment
- Use case: Robust 3D reconstruction for long clinical videos (endoscopy, intraoperative imaging) with collapse-aware controls and audit trails.
- Potential products: FDA-ready toolchains with entropy/rank monitors; fail-safe fallback to local attention.
- Dependencies: Clinical validation, regulatory approval, domain-specific optimization, explainability requirements.
- Policy and Standards — Metrics, reporting, and “Green AI” guidance
- Use case: Establish organizational and industry standards to report attention-collapse metrics (entropy/rank profiles) and energy savings from token reduction.
- Potential frameworks: Procurement and compliance guidelines requiring collapse diagnostics; carbon accounting tied to scaling.
- Dependencies: Consensus on metrics and thresholds; auditors and tool support; sector-specific governance.
- City-scale AR/VR and Mapping — Consumer devices coordinating large-area scans
- Use case: Collapse-aware capture protocols and on-device merging to enable persistent, multi-user maps in urban environments.
- Potential workflows: Entropy-budgeted scanning; shared anchors across devices; cloud-edge collaboration.
- Dependencies: Robust synchronization; privacy and data-sharing policies; large-scale deployment trials.
- Training-time Co-optimization — Jointly balancing expressivity and efficiency
- Use case: Combine merging, sparsity, windowed attention, and entropy regularization during training to delay collapse without inference-only compromises.
- Potential tools: AutoML for merge schedules; curriculum learning that controls diffusion mobility.
- Dependencies: Compute budgets for retraining; generalization studies; cross-benchmark validation.
- Open-source Ecosystem — Standardized libraries and benchmarks
- Use case: Community packages for collapse monitoring, adaptive merging, and PDE-based analysis; standard datasets logging attention statistics.
- Potential products: “CollapseBench” with entropy/rank vs. accuracy curves; plugins for FlashAttention/NA/WinTr-style kernels.
- Dependencies: Maintainer support; broad hardware coverage; reproducible telemetry pipelines.
Key cross-cutting assumptions and dependencies
- Model assumptions: Results rely on VGGT-like global attention, DINOv2-style initialization, and mean-field approximations (); residual/normalization effects and head specialization are simplified in theory.
- Merging constraints: Excessive merging ( or very large ) can remove informative tokens, degrading geometry; reference-frame protection and salient-token shielding are crucial.
- Metrics and thresholds: Practical use depends on reliable attention entropy/effective-rank estimation and domain-specific accuracy thresholds (e.g., normalized entropy > 0.8 correlating with low ATE).
- Hardware/software: Benefits scale with attention-heavy workloads and compatible kernels (e.g., FlashAttention); edge/mobile deployment requires quantization and memory-aware engineering.
- Domain validation: Healthcare and safety-critical robotics require additional validation and governance; multi-modal generalization needs new theory and datasets.
Glossary
- Absolute Rotation Error (ARE): A metric measuring the angular difference between predicted and ground-truth camera rotations. "Absolute Rotation Error (ARE)"
- Absolute Trajectory Error (ATE): A metric quantifying overall deviation between predicted and ground-truth camera trajectories. "Absolute Trajectory Error (ATE)"
- Aligned Relative Pose Error in Translation (RPE-Trans): A frame-to-frame translation error after alignment between trajectories. "Aligned Relative Pose Error in Translation (RPE-Trans)"
- Attention collapse: Degeneration of self-attention where attention becomes nearly uniform and low-rank, losing discriminative features. "This phenomenon, which we refer to as attention collapse"
- Attention heatmaps: Visualizations showing where tokens attend, used to interpret attention behavior. "The output visualizes attention heatmaps across different transformer blocks"
- Bundle Adjustment (BA): Nonlinear optimization refining camera parameters and 3D points jointly. "Bundle Adjustment (BA)"
- Chamfer distance: A symmetric distance between point sets used to measure geometric error. "geometric error (measured by Chamfer distance or camera drift)"
- Degenerate diffusion process: A diffusion dynamic that concentrates mass, leading to collapse in feature distributions. "by viewing the global-attention iteration as a degenerate diffusion process."
- Diffusion coefficient: The parameter controlling the rate of diffusion in the PDE dynamics of token features. "slows the effective diffusion coefficient"
- DINOv2 initialization: Using weights from the DINOv2 pretrained model to initialize the transformer. "under DINOv2 initialization"
- Dirac-type measure: A distribution concentrated at a single point, indicating total collapse of diversity. "converges toward a Dirac-type measure"
- Effective rank: An entropy-based measure of the number of significant singular values of a matrix. "the effective rank"
- Entropy decay: The monotonic decrease of entropy indicating increasing concentration or loss of diversity. "entropy decays monotonically:"
- Entropy regularization: A technique that encourages higher-entropy attention distributions to avoid collapse. "entropy regularization"
- Essential matrix decomposition: Factorization of the essential matrix to recover relative camera pose. "essential matrix decomposition and triangulation"
- FastVGGT: A variant of VGGT that accelerates inference via token reduction while preserving accuracy. "FastVGGT adapted token merging specifically for VGGT"
- FlashAttention-style: A memory-efficient exact attention computation optimized for IO. "FlashAttention-style"
- Fokker–Planck equation: A PDE describing time evolution of probability densities under drift-diffusion. "degenerate Fokker--Planck equation"
- Global self-attention layer: An attention mechanism attending over all tokens in the sequence, enabling global context. "global self-attention layer suffers from a drastic collapse phenomenon"
- Mean-field limit: The asymptotic regime as the number of tokens tends to infinity, leading to continuum dynamics. "mean-field limit"
- Mean-field partial differential equation (PDE): A continuum equation governing the evolution of the token-feature distribution. "mean-field partial differential equation (PDE)"
- Normalized singular-value entropy: Entropy computed on the normalized singular-value spectrum to quantify matrix diversity. "normalized singular-value entropy"
- Rank-one matrix: A matrix with only one non-zero singular value, indicating minimal expressivity. "near rank-one"
- Reference-frame protection: A heuristic to prevent merging tokens from key frames to preserve geometric anchors. "reference-frame protection and salient token shielding"
- Relative Pose Error in Rotation (RPE-Rot): A frame-to-frame rotational error measure after alignment. "Rotation (RPE-Rot)"
- ScanNet-50: A standardized subset of ScanNet used for evaluation. "ScanNet-50 split"
- Structure-from-Motion (SfM): A pipeline that reconstructs 3D structure and camera poses from images. "Structure-from-Motion (SfM)"
- Token merging: Combining redundant tokens to reduce sequence length and computational cost. "token merging"
- Token sparsification: Reducing the number of tokens or interactions to make attention more efficient. "token sparsification and efficient attention"
- Token unmerging: Re-expanding previously merged tokens to restore local detail for subsequent processing. "token unmerging"
- Visual Geometry Grounded Transformer (VGGT): A transformer architecture for feed-forward multi-view 3D reconstruction. "Visual Geometry Grounded Transformer (VGGT)"
- Windowed attention: Restricting attention to local windows to reduce quadratic complexity. "windowed attention (sliding windows, local attention)"
Collections
Sign up for free to add this paper to one or more collections.

