- The paper demonstrates a reinforcement-guided diffusion model that adaptively fine-tunes synthetic data to preserve identity fidelity while boosting intra-class diversity.
- It introduces a composite multi-objective reward combining semantic consistency, distribution matching, and variance control to optimize downstream recognition performance.
- Dynamic sample selection further enhances utility by prioritizing samples that significantly improve mAP scores and reduce subgroup biases.
Reinforcement-Guided Synthetic Data Generation for Privacy-Sensitive Identity Recognition
Introduction
The increasing stringency of privacy regulations and growing concerns regarding data ownership substantially restrict the collection and annotation of identity-labeled datasets. This data scarcity drastically limits the efficacy and generalization of deep identity recognition models. Conventional synthetic data augmentation techniques offer only incremental gains and suffer from mode collapse or poor diversity, especially when supervision is limited. In "Reinforcement-Guided Synthetic Data Generation for Privacy-Sensitive Identity Recognition" (2604.07884), Jia et al. address these limitations by proposing a reinforcement-learning (RL) paradigm that adaptively fine-tunes generative diffusion models under a composite reward, resulting in synthetic samples that simultaneously optimize fidelity, intra-class diversity, and downstream utility.
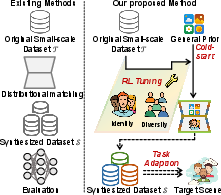
Figure 1: Pipeline comparison. (a) Traditional methods degrade in utility due to limited supervision. (b) Reinforcement-guided adaptation of general-domain priors yields improved diversity and task-specificity.
Methodology
Diffusion Model Backbone and Initialization
The framework utilizes a Diffusion Transformer (DiT) pretrained on large-scale general-domain datasets. DiT outperforms UNet-based latent diffusion backbones due to superior modeling of long-range semantic dependencies and class-conditional structures. To ensure stable RL optimization under privacy constraints, a cold-start initialization aligns the pretrained model to the target identity label space via lightweight fine-tuning on a constrained dataset, replacing the class embedding head without modifying the backbone.
Reinforcement-Guided Fine-Tuning
The central contribution is formulating synthetic data generation as a Markov Decision Process, where the generative diffusion policy is optimized against a composite multi-objective reward:
- Semantic Consistency: Encourages identity-preserving synthesis via cosine similarity to class prototypes in the embedding space.
- Distributional Coverage: Employs a kernel-based maximum mean discrepancy (MMD) reward to match the support of the synthesized and real identity feature distributions, mitigating mode collapse and maximizing intra-class variance.
- Expression/Variance Regularization: Controls global covariance to ensure the synthetic feature distribution is neither degenerate nor excessively diffuse, stabilizing generation for utility on downstream recognition.
Each reward is batch-normalized and combined via learnable weights, and the full RL optimization leverages a DPOK-style policy gradient adaptation.
Dynamic Sample Selection
A lookahead-inspired utility criterion is introduced for batch selection, simulating virtual gradient updates to estimate the marginal utility of individual synthetic samples for downstream model training. The most utility-enhancing samples are selected for each batch, further mitigating negative transfer from low-quality or domain-misaligned syntheses.
Experimental Evaluation
Synthesis Diversity and Fidelity
Qualitative analysis of Market-1501 and CASIA-WebFace demonstrates that the proposed method increases intra-class diversity—identity clusters cover broader regions in the feature space with significant variation in pose, lighting, and expression, while preserving identity labeling.

Figure 2: Person images synthesized for Market-1501. RL fine-tuning yields substantial intra-class diversity while maintaining identity, outperforming standard DiT generation.

Figure 3: Face images from CASIA-WebFace. RL optimization produces more expressive and varied samples than baseline DiT, compensating for limited real data.
Feature projections with DOSNES indicate that samples generated by this method populate contiguous regions around the real data clusters, improving the local manifold structure and enhancing the representation available for discriminative training.

Figure 4: DOSNES feature visualization reveals that RL-guided synthesis expands intra-identity manifolds while preserving class separability.
On Market-1501 and CUHK03-NP, the method achieves 88.6% mAP and 76.6% mAP, respectively, yielding a 3.2% (Market-1501) and 2.5% (CUHK03-NP) increase over classical and GAN-based augmentation pipelines. Synthetic augmentation with the RL-guided process consistently outperforms all distribution-matching approaches in both absolute accuracy and generalization to unseen classes.
In face recognition, the average verification accuracy on five public benchmarks reaches 79.07%, exceeding all GAN and diffusion model (DM) competitors by at least 0.6% (real-data baseline) and 0.94% (best prior DM), providing empirical evidence of improved feature quality despite minimal supervision.
Bias and Robustness
The method shows lower performance gaps across race subgroups (RFW benchmark), with the highest reported average accuracy (69.78%), and increased performance for historically under-represented subgroups (e.g., Indian, Asian, African categories). This demonstrates the potential for RL-guided synthesis to address distributional bias even without explicit debiasing objectives.
Ablation Analysis and Backbone Generalization
Ablative experiments confirm the additive effect of each reward component and dynamic selection. The full pipeline achieves a 3.42% absolute gain in face verification over the DiT-only baseline. Gains are robust across both CNN and ViT backbones.
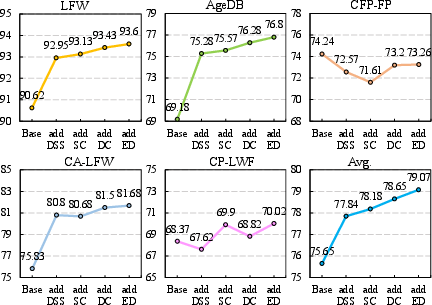
Figure 5: Progressive integration of each pipeline component yields additive accuracy improvements in face verification.
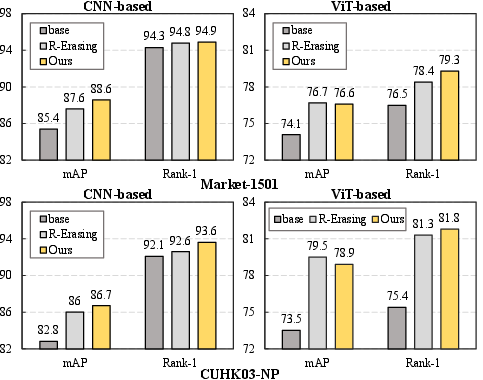
Figure 6: Performance comparison between baseline and RL-guided augmentation on person ReID tasks—consistent gain on both CNN and Vision Transformer backbones.
Theoretical and Practical Implications
The reinforcement-guided adaptation approach re-frames synthetic data generation for privacy-sensitive identity recognition as a downstream-task-aligned process, explicitly balancing fidelity, diversity, and class-conditional discriminability. This framework generalizes to scenarios with severe data collection restrictions (e.g., privacy regulation, copyright encumbrance, small populations) by leveraging general-domain priors and aligning synthesis towards utility, not merely distributional matching.
Practically, the pipeline can support rapid deployment of re-identification and face recognition systems in clinical, security, or federated settings where access to data is transient, minimal, or ultra-sensitive. The absence of any explicit supervision requirements beyond the small seed dataset and the use of utility-driven sample selection mechanisms position this approach as a viable candidate for privacy-aware synthetic data generation at deployment scale. The observed mitigation of subgroup biases further suggests its long-term value for responsible and equitable model development.
Limitations and Future Directions
Performance is bounded by the generalization characteristics of the base diffusion backbone; adaptation is challenging when the prior is poorly aligned with the target domain or label semantics. The reward definitions, while effective for identity recognition, require tuning or extension for other tasks or modalities. Extension to multi-modal, spatio-temporal domains (video, 3D, event) is unaddressed. Incorporation of privacy-preserving policies (e.g., differential privacy, secure multiparty computation) is a logical next extension for real-world translation.
Conclusion
This study offers a principled utility-driven framework for overcoming data scarcity in privacy-sensitive recognition by coupling general-domain generative priors with reinforcement-guided adaptation. The combination of carefully designed reward objectives and dynamic utility-aware sample selection yields statistically significant improvements in downstream performance, diversity, and fairness, establishing a new standard for synthetic data generation in regulatory-constrained identity domains.

