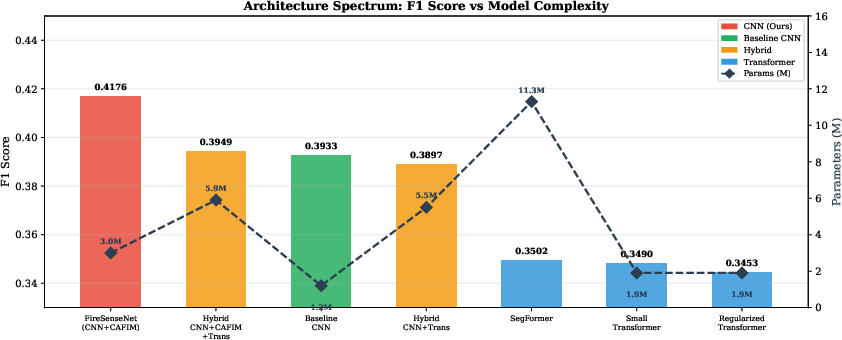
- The paper introduces a dual-branch CNN using CAFIM to fuse modality-specific features, achieving an F1 score of 0.4176 for wildfire spread prediction.
- It employs separate encoders for static fuel/terrain and dynamic meteorological data, combined with a U-Net decoder and Monte Carlo Dropout for uncertainty estimation.
- The study emphasizes that explicit cross-modal attention and strict evaluation protocols offer more reliable operational insights compared to traditional and Transformer-based models.
FireSenseNet: Dual-Branch CNNs with Cross-Attentive Feature Interaction for Operational Wildfire Spread Prediction
Introduction and Context
The accurate, automated prediction of next-day wildfire spread is operationally critical for disaster mitigation and emergency response. Traditional deep learning models in this domain have predominantly used monolithic encoder architectures to ingest all heterogeneous geospatial rasters—static fuel/terrain and dynamic meteorology—via channel concatenation, neglecting the distinct causal roles these modalities play in fire dynamics. "FireSenseNet: A Dual-Branch CNN with Cross-Attentive Feature Interaction for Next-Day Wildfire Spread Prediction" (2604.07675) introduces a new architectural paradigm that embeds modality-specific inductive biases and explicit cross-modal attention. The study demonstrates that their approach achieves state-of-the-art performance and fundamentally challenges the presumed superiority of Vision Transformers in remote sensing tasks with limited and sparse data.
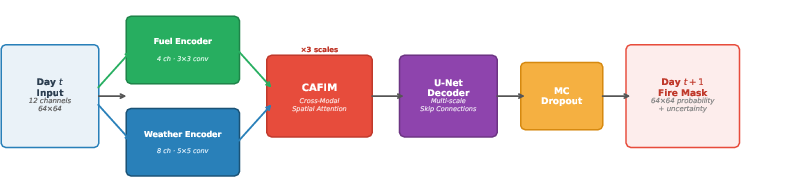
Figure 1: FireSenseNet pipeline overview. Modality-specific encoding and multi-scale fusion enable spatially resolved, uncertainty-calibrated next-day wildfire segmentation.
The work targets the Google Next-Day Wildfire Spread benchmark, which provides 64×64 raster patches covering variable terrain, vegetation, and meteorological histories. The 12-channel input is explicitly partitioned: four "fuel/terrain" channels (elevation, NDVI, population density, previous-day fire mask) and eight weather/meteorology channels (winds, temperatures, humidity, precipitation, drought index, energy release component). The ground truth label segregates burned (fire), unburned (non-fire), and unknown (−1) pixels, with the latter systematically excluded from both loss and metric computation in the strict evaluation protocol.
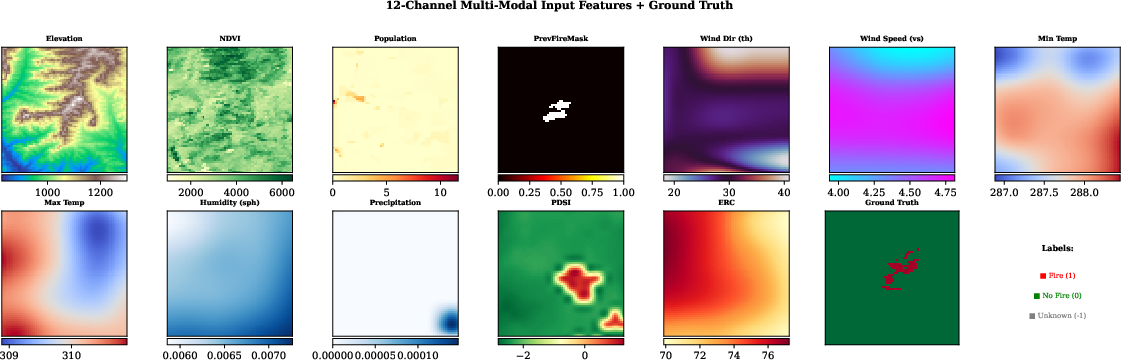
Figure 2: Test sample visualization: static terrain and dynamic meteorological channels exhibit distinct spatial statistics, motivating dual-branch/CAFIM architecture.
Model Architecture: Dual-Branch Encoding and CAFIM
FireSenseNet replaces conventional channel concatenation with two independent encoder branches (3x3 residual blocks for fuel/terrain, 5x5 convolutions for weather), each optimized for its modality's spatial characteristics. Central to the design is the Cross-Attentive Feature Interaction Module (CAFIM), a multi-scale attention gate that generates spatially adaptive convex combinations of the two feature groups. For each scale, a learned attention map α∈[0,1]H×W allocates local importance between fuel and weather—interpretable as a hard-coded prior derived from fire science.
The decoder adopts a U-Net topology with MC Dropout for calibrated pixel-level uncertainty estimation, leveraging skip connections that preserve multi-scale feature specificity. The architecture maintains high parameter efficiency (∼3M parameters), offering a favorable FLOPs-latency-accuracy tradeoff.
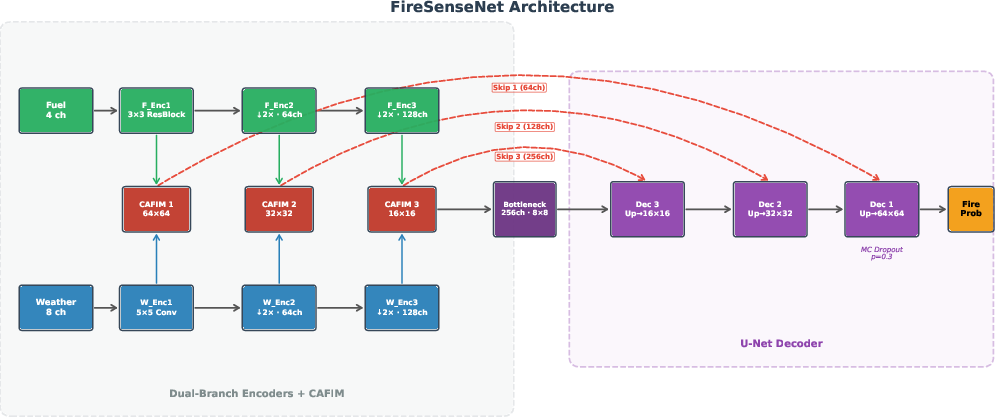
Figure 3: Schematic: modality-specific encoders, CAFIM fusion, U-Net decoder, and Monte Carlo Dropout for uncertainty quantification.
Head-to-Head Model Comparison
The paper systematically benchmarks seven architectures—pure CNNs, Transformers (SegFormer variants), and hybrids—while controlling for dataset, loss, and augmentation strategies.
Key empirical observations:
Qualitative prediction analysis further underscores that FireSenseNet yields spatially sharp and topologically coherent fire masks, whereas transformer architectures distribute probability mass diffusely, unable to localize boundaries critical for fire response planning.

Figure 5: Qualitative prediction comparison: precise geometric correspondence for FireSenseNet; transformers yield diffuse, over-spread outputs.
Ablation and Diagnostic Analysis
Ablating CAFIM (replacing with naive concatenation) reduces F1 by 7.1%, confirming that explicit, physically justified cross-modal gating is not a replaceable detail but a substantive enabler of generalization. Channel-wise feature masking further reveals that the previous-day fire mask dominates (ΔF1 = -0.21)—confirming the persistence-dominated regime—while the wind speed channel, counterintuitively, acts as noise at daily resolution levels (ΔF1 = +0.001).
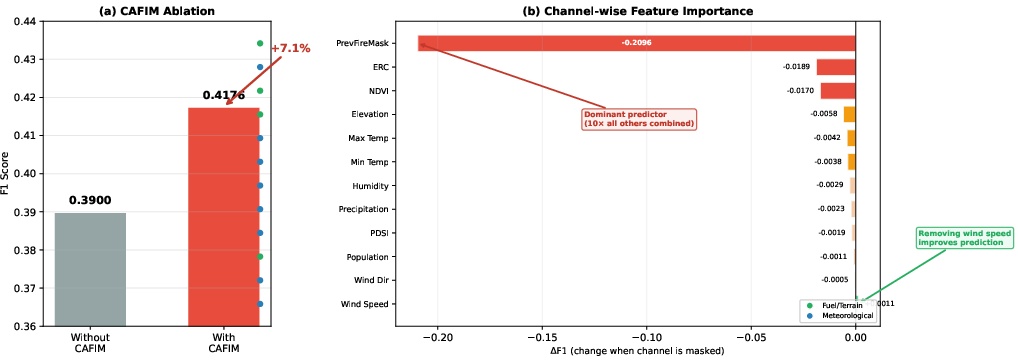
Figure 6: (a) CAFIM ablation: 7.1% F1 loss; (b) Feature importance: PrevFireMask is critical, wind speed is counterproductive at daily granularity.
Attention maps confirm that learned CAFIM gate values align with fire science: at high resolution, attention focuses on fire perimeters (transition zones), broadening with scale to reflect overall regional susceptibility.
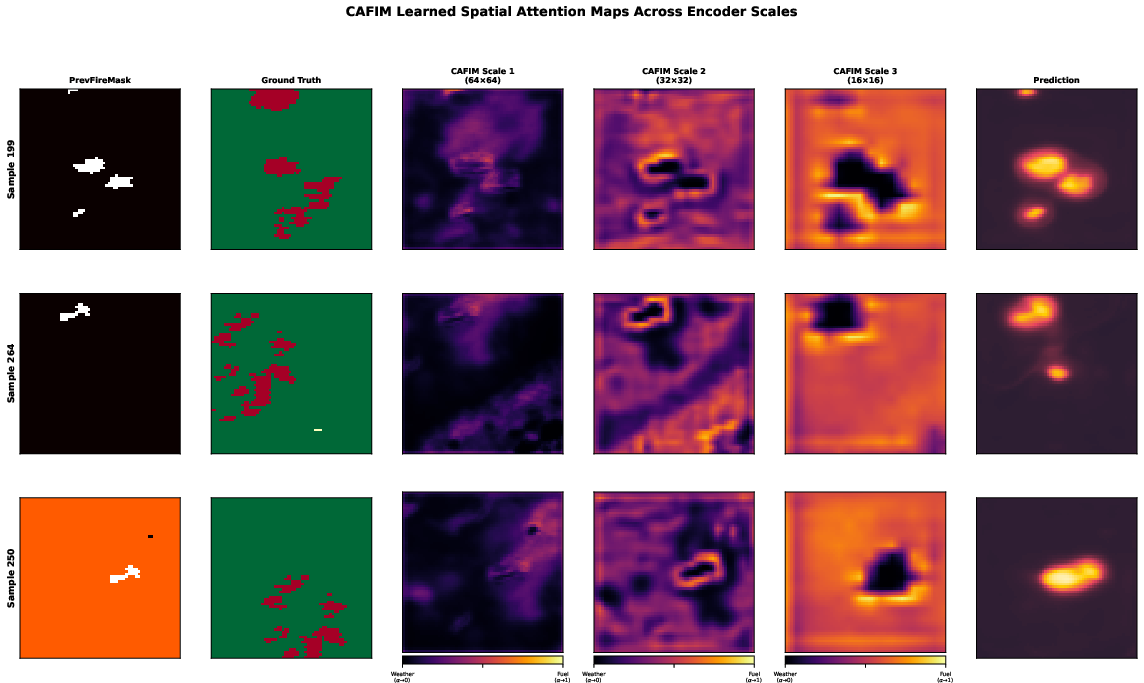
Figure 7: CAFIM attention maps at different scales, showing interpretable spatial focus corresponding to likely fire spread interfaces.
Evaluation Protocol Sensitivity
A crucial contribution is the methodologically rigorous critique of widespread, inflationary evaluation shortcuts: including the previous-day fire mask as part of the target and relabeling unknown pixels as non-fire. These modifications systematically inflate reported F1 by 44–50% and compress model differences, thus hampering scientific progress in fair benchmarking. The strict protocol adopted in this work adheres to operationally valid constraints, ensuring that observed gains reflect true advances in prediction rather than metric gaming.
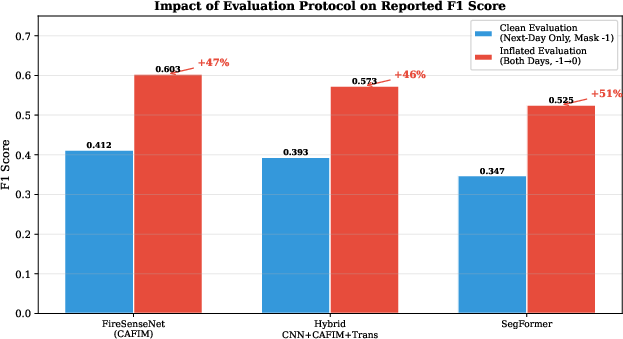
Figure 8: Comparison of strict vs. inflated protocols: the latter obscures true model performance and disproportionately benefits low-capacity models.
Uncertainty Quantification
FireSenseNet’s Monte Carlo Dropout framework provides calibrated, actionable uncertainty maps. High uncertainty naturally aligns with fire perimeters—precisely where operational resource prioritization is most critical.
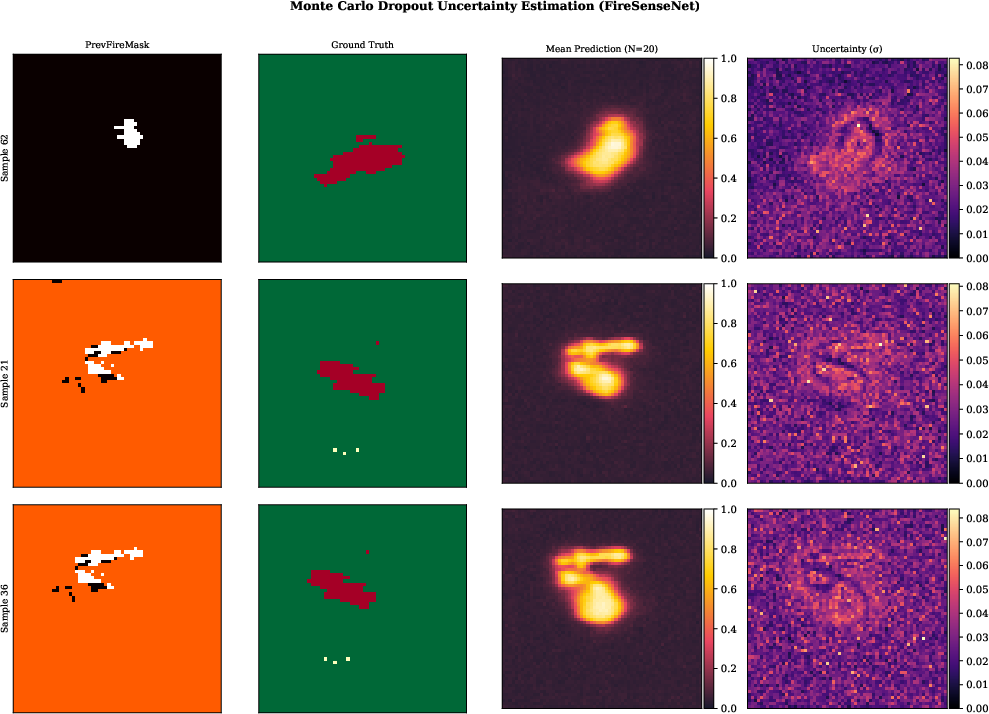
Figure 9: MC Dropout: uncertainty is highest at advancing perimeters—regions where model guidance is most valuable in response contexts.
Implications and Theoretical/Practical Consequences
Theoretical implications: The demonstrated supremacy of CNNs with explicit cross-modal attention over Transformers in this setting contradicts the broader recent trend observed in generic semantic segmentation. These findings assert the continued relevance of strong domain-specific inductive biases for tasks characterized by small sample sizes, sparse signals, and structured physical causality. Architectural priors remain vital when universal attention-based models lack the scale or spatial grounding required by the underlying process.
Practical consequences: FireSenseNet’s architectural design yields a deployable, computationally tractable model suitable for operational next-day planning. Uncertainty maps provide emergency managers with rational criteria for resource triage and ground truth verification. The identified protocol pitfalls directly inform future benchmarking standards, preventing overstatements of improvement due to relaxed data handling.
Future directions: Extending the approach to temporally resolved wind fields, leveraging richer multi-day stacks, and integrating CAFIM with spatiotemporal transformers on larger, denser datasets constitute promising avenues for theoretical advancement and further operational application.
Conclusion
FireSenseNet establishes that dual-branch modality separation with interpretable, spatially adaptive attention outperforms both monolithic and Transformer-based paradigms for next-day wildfire spread prediction, given data and label constraints characteristic of this application. The work not only achieves strong quantitative and qualitative improvements but also offers critical guidance on fair evaluation and the continued importance of explicit domain-driven architectural priors in neural spatiotemporal prediction frameworks.