- The paper introduces SAGE, reducing optimizer memory by 10–45% and achieving lower perplexity than AdamW and Lion on LLaMA models.
- The paper presents a novel hybrid method using a Lion-style update and an adaptive damper to tame high-variance gradients in embedding layers.
- The paper demonstrates that SAGE improves convergence and efficiency, enabling larger batch sizes and scalable training for large language models.
SAGE: Sign-Adaptive Gradient for Memory-Efficient LLM Optimization
Introduction and Motivation
The proliferation of LLMs has accentuated the memory bottlenecks in training, particularly stemming from optimizer state requirements. Traditional optimizers like AdamW necessitate two full-sized moment states per parameter, imposing a memory burden proportional to twice the size of the model, significantly constraining batch sizes and model scaling. Recent advances sought relief through light-state optimizers—Lion, GaLore, APOLLO, SWAN, SinkGD—by halving or reducing state storage, yet these innovations falter in handling embedding layers with sparse, high-variance gradients. Consequently, current methods revert to AdamW for embeddings, eroding memory gains.
The paper introduces SAGE (Sign Adaptive GradiEnt), a memory-efficient optimizer targeting the embedding layer dilemma. SAGE replaces AdamW in hybrids with a Lion-style single-state update direction, augmented by a novel O(d) adaptive scale damper, theoretically bounded by $1.0$. This scale modulates update magnitudes dynamically, taming high-variance dimensions typical of embeddings, delivering enhanced stability and permitting more aggressive learning rates without sacrificing convergence.
Embedding Layer Dilemma and Justification
Sparse and high-variance gradients in embedding layers, driven by the Zipfian token distribution, invalidate stateless normalization approaches. Experimental evidence demonstrates that SinkGD-Pure, despite learning rate tuning, fails to deliver effective embedding representations, resulting in degraded perplexity relative to SinkGD-Hybrid with AdamW for embeddings.
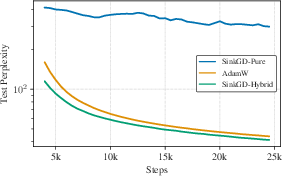
Figure 1: Test Perplexity for SinkGD-Pure vs. SinkGD-Hybrid. Pure stateless optimizers fail to learn robust embeddings, yielding high perplexity.
This result underlines the necessity for adaptive, stable memory-light optimization strategies tailored to the embedding layer, catalyzing the development of SAGE.
SAGE Optimizer Architecture and Algorithm
SAGE’s hybrid structure leverages SinkGD for dense 2D weights and applies the SAGE algorithm to embedding, bias, and normalization parameters. The SAGE update generalizes Lion: it replaces static $1.0$ scaling with an adaptive damper Ht, computed from an exponential moving average of the mean absolute gradients (L1 norm). The adaptive scale is calculated relative to the root mean square (RMS) of layer updates, ensuring scale invariance and provable safety (∣∣Ht∣∣∞≤1). For low-variance dimensions, updates default to Lion’s unit scale; for high-variance (loud) dimensions, strong damping is applied.
The algorithm further introduces an instantaneous stability constraint, analogous to Adaptive Gradient Clipping, enabling rapid adaptation to sudden gradient spikes. This dual mechanism ensures robust, variance-aware update directions.
Theoretical Foundations
SAGE’s convergence is established under standard smoothness and bounded variance/gradient assumptions. The adaptive state St is shown to remain bounded, providing a safe proxy for per-dimension gradient scale. The damper Ht is element-wise bounded, ensuring the update magnitude does not exceed Lion’s, yielding a strictly safer generalization. SAGE's convergence to stationary points is guaranteed, with its theoretical framework grounded in established sign-based optimizer analysis.
Rigorous experimental validation is conducted on LLaMA-architecture models (270M, 0.6B, 1.3B parameters), pretrained from scratch on The Pile dataset, comparing SAGE and multiple memory-efficient optimizers. SAGE consistently achieves the best final test perplexity across scales, with the performance gap widening for larger models. Notably, for the 1.3B parameter model, SAGE attains a perplexity of 24.33 versus AdamW's 27.81 and Lion's 28.37.
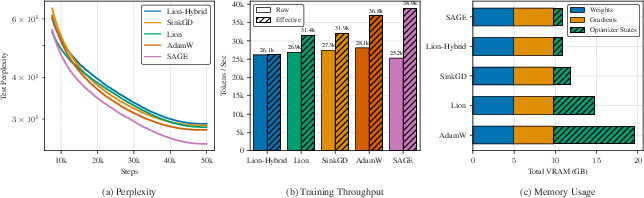
Figure 2: Convergence and efficiency on 1.3B model: SAGE achieves lowest final perplexity, faster convergence, and superior effective throughput.
Memory savings are substantial: by replacing AdamW’s embedding optimizer with SAGE’s O(d) state, optimizer memory is reduced by 10–45% at comparable performance. This matches Lion-Hybrid’s footprint and enables larger batch sizes or models.
Adaptive Scale Analysis and Internal State Dynamics
Visualization of the adaptive scale Ht demonstrates SAGE’s sparse damping mechanism: most embedding dimensions retain unit scale, while only select loud dimensions receive strong damping, corresponding to high-variance gradient activity.
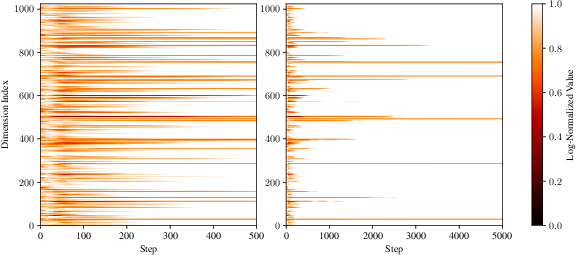
Figure 3: Visualization of SAGE adaptive scale $1.0$0; only specific dimensions are strongly damped.
Temporal dynamics reveal initial aggressive damping during early training, followed by stabilization and localization to high-variance dimensions—a two-phase adaptation process confirmed via PCA analysis.
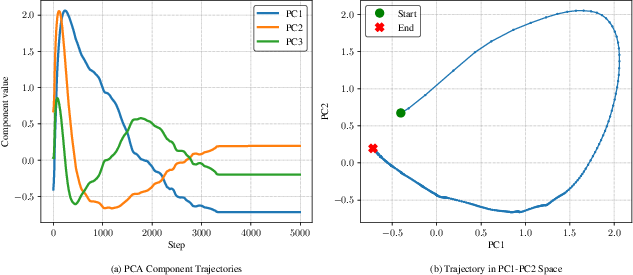
Figure 4: PCA analysis of $1.0$1 trajectories highlights coherent principal directions and long-term stabilization.
SAGE thereby maintains a low-rank, compact representation of update geometry, aligning with established findings in network optimization subspace structure.
Implications and Future Directions
SAGE resolves the persistent memory bottleneck for embedding layer optimization in LLMs, offering enhanced scalability and stability at reduced memory cost. The robust adaptation mechanisms unlock higher learning rates and stability, improving convergence and reducing hardware requirements.
Practically, SAGE enables training of larger models or batch sizes, facilitating research and deployment on resource-constrained environments. Theoretically, its adaptive damper contributes evidence toward the efficacy of low-rank, sign-based optimizers tailored to high-variance regimes.
Future developments could extend SAGE to larger scales (7B+), investigate cross-modal applicability, and benchmark against alternative orthogonal optimization paradigms like Muon. Its robust handling of gradient variance may stimulate further innovation in high-dimensional memory-efficient optimization.
Conclusion
SAGE introduces a provably safe, memory-efficient optimizer tailored to the embedding layer dilemma in LLM training. By generalizing Lion with an adaptive, bounded scale, SAGE delivers superior convergence, stability, and efficiency at scale, validating its role as a foundation for scalable, efficient LLM optimization. The implications for model scaling, batch size flexibility, and computational efficiency position SAGE as a pivotal advancement in memory-conscious neural network training methodologies.