- The paper demonstrates that real-time 3D Gaussian Splatting achieves interactive frame rates on high-end GPUs, while lower-tier devices incur steep energy costs with increased scene complexity.
- The paper employs an emulation-based methodology using power capping and GPU underclocking to simulate multiple GPU tiers, enabling consistent, device-agnostic performance benchmarking.
- The paper reveals that layered Level-of-Detail and adaptive animation handling are crucial for maintaining rendering fidelity alongside energy-efficient performance on constrained devices.
Overview and Motivation
The paper "Splats under Pressure: Exploring Performance–Energy Trade-offs in Real-Time 3D Gaussian Splatting under Constrained GPU Budgets" (2604.07177) addresses the practical feasibility of deploying real-time 3D Gaussian Splatting (3DGS) rendering pipelines on edge clients with limited compute and power resources. The authors focus on empirical characterization of 3DGS rasterization performance, examining how interactive frame rates and energy efficiency scale across a spectrum of GPU classes ranging from flagship RTX 4090 down to entry-level RTX 3050, using an emulation-based methodology via systematic GPU underclocking and power capping.
This investigation is critical amidst growing interest in distributed and hybrid rendering pipelines, where shifting heavy computation from cloud to client devices minimizes latency and operational cost. Given that 3DGS demands substantial GPU throughput—millions of point primitives blended front-to-back in real time—the paper quantifies the lower bounds at which desktop-class hardware can sustain interactive performance and assesses the viability of deploying 3DGS in energy-constrained environments like standalone headsets and thin clients.
GPU Emulation Methodology
Rather than benchmarking disparate physical devices, the authors emulate four GPU capability tiers on an RTX 4090 via power and frequency throttling combined with empirical TFLOPS calibration. The procedure maps vendor-quoted theoretical FP32 maxima to realistic sustained compute envelopes (using a conservative 66% efficiency factor), adjusting core/memory clocks and power caps until the measured compute and memory bandwidth closely align with those of the reference GPUs. This results in four configurations representing RTX 4090, 4070 Ti, 3070, and 3050, encompassing high-end, mid-range, and entry-level devices.
This approach enables consistent benchmarking and isolates client-side rasterization cost. While not perfectly reproducing memory bandwidth or SM count, the methodology delivers a pragmatic device-agnostic analysis of real-time 3DGS rendering limits.
Layered Level-of-Detail, Animated Scene Handling, and Pipeline Structure
The experimental system leverages the gsplat Python/CUDA library, which provides accelerated training, optimized rasterization, and out-of-core data handling. Scene complexity is adapted via layered Level-of-Detail (LoD), as proposed in LapisGS, training splat sets at progressively finer resolutions and selectively disabling layers to control the active Gaussian count. This allows evaluation from ~580k up to ~3.5M splats per scene.
Animated assets utilize 4D Gaussian Splatting (Wu et al.), wherein each dynamic object is reconstructed as a base Gaussian set augmented by small MLPs that parameterize time-varying deformations. At render time, forward passes of the MLP update splat parameters per frame, introducing additional arithmetic and memory cost.
The execution model follows a client–server paradigm: all training and LoD construction occur offline on the server, with the client receiving relevant layers and animation weights. The study, however, abstracts network effects to focus strictly on rasterization metrics.
Core metrics include frame rate, memory usage, power consumption, energy per frame, and performance-per-watt, measured across all combinations of GPU tier, scene complexity, and animation inclusion at a fixed 1920×1080 resolution.
(Frame rates and performance envelope are visualized.)
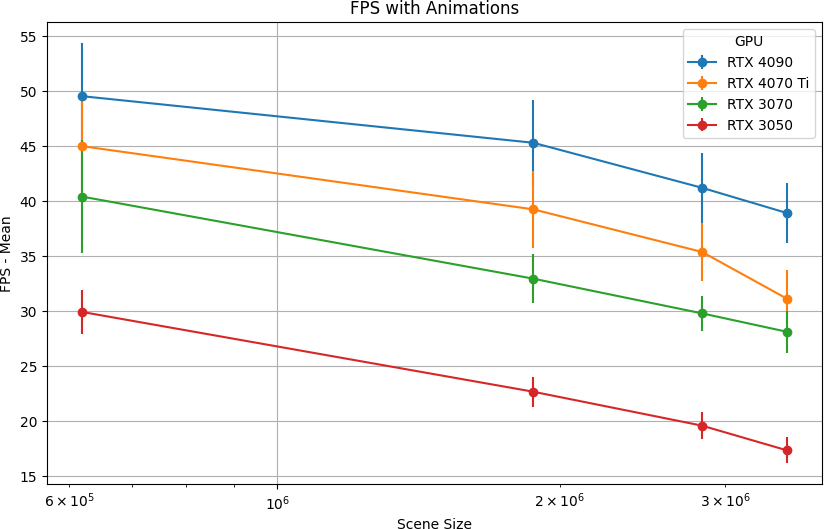
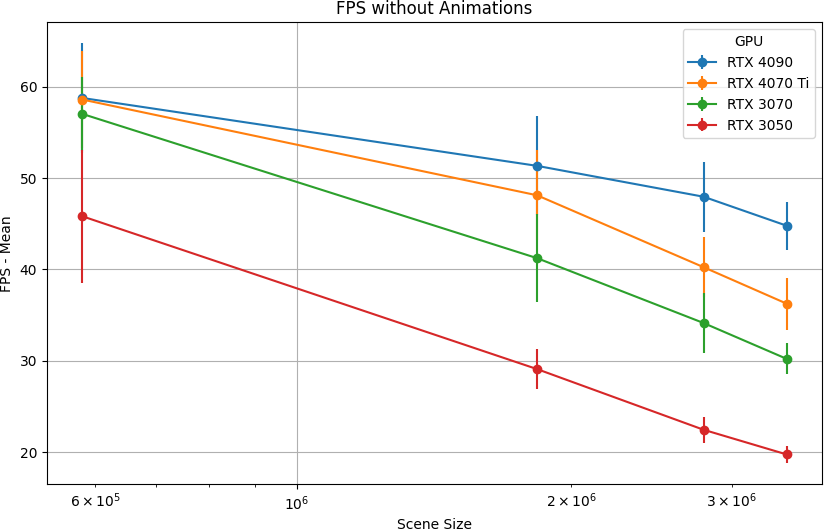
Figure 1: Mean and standard deviation of frame rates across emulated GPU capability tiers and scene sizes, illustrating the performance envelope of real-time 3DGS under constrained compute budgets.
Frame Rate Scaling
Results establish that real-time (≥60 FPS) 3DGS rasterization is available on RTX 4090, 4070 Ti, and 3070 for scenes up to ~600k splats. The RTX 3050 maintains usable performance (46 FPS) at this coarser LoD but drops below 30 FPS for larger ~3M splat scenes, rendering it impractical for high-complexity content without aggressive LoD pruning or cloud assistance. In pure animation scenarios (with 38,844 animated splats), the overhead rises to 35% frame-rate loss on RTX 3050 compared to only ~15% on RTX 4090, indicating severe sensitivity to arithmetic and memory-bound operations in low-end hardware.
LoD and Scene Complexity Implications
LoD control enables scalability: fine-detail layers are disabled to maintain interactive rates on lower-tier GPUs. However, fidelity and detail retention scale inversely with splat count—practical thin client deployments require either server-side rasterization for dense scenes or predictive LoD scheduling and bandwidth-aware streaming to adapt to device constraints.
The study exposes clear trade-offs: high-end devices achieve both higher FPS and superior performance-per-watt (FPS/W) metrics, while entry-level GPUs exhibit steep increases in energy per frame for higher scene complexities, exacerbated by animation inference costs. Thus, reporting both graphics and energy efficiency is essential for evaluating edge-deployed rendering pipelines.
Limitations and Perspective
The emulation approach, though device-agnostic and replicable, inherits several limitations:
- Memory bandwidth mismatch: Emulated configurations retain excess bandwidth compared to real target devices, likely inflating FPS for large splat counts.
- SM count disparity: Reduction via clocking does not precisely mimic lower thread-level parallelism or cache characteristics.
- Single efficiency assumption: FP32 throughput is fixed at 66%; actual sustained TFLOPs may vary.
Moreover, the dataset scope is restricted to a single Garden-style scene; highly occluded or city-scale datasets may stress rasterizer bottlenecks differently. The exclusive use of CUDA limits immediate applicability to NVIDIA hardware; porting to Vulkan/Metal on mobile SoCs (Snapdragon XR2, Apple M2) would require radical pipeline reengineering.
Implications for Future AI and Graphics Systems
Findings delineate a clear landscape for client-side 3DGS: desktop-class GPUs down to RTX 3070 can render moderately complex scenes unaided, while lower-end systems necessitate either cloud-based fine-detail streaming or aggressive LoD reduction. The results guide system architects in selecting deployment targets, motivate research into bandwidth-aware hierarchical LoD prediction, and inform hybrid pipeline design where detail is adaptively shifted between server and client.
Adapting 3DGS for mobile SoCs remains open; compression techniques such as temporally-compressed blend-splats, memory bandwidth emulation, and cross-API kernel development are prospective directions. Furthermore, benchmarking schemes that include energy-aware metrics alongside FPS are imperative, especially for XR and edge platforms constrained by thermal and power envelopes.
Conclusion
This work systematizes the benchmarking of real-time 3DGS rasterization under constrained GPU budgets. By emulating four consumer GPU tiers and analyzing performance–energy trade-offs across layered LoD budgets and animated scenes, it establishes quantifiable viability points for desktop-class hardware. The methodology is scalable and isolates client-side rendering cost, providing a common framework for future assessments of LoD compression, animation handling, and API portability. The results concretely inform device selection and pipeline construction for democratizing photorealistic neural rendering in latency-sensitive, power-constrained environments.