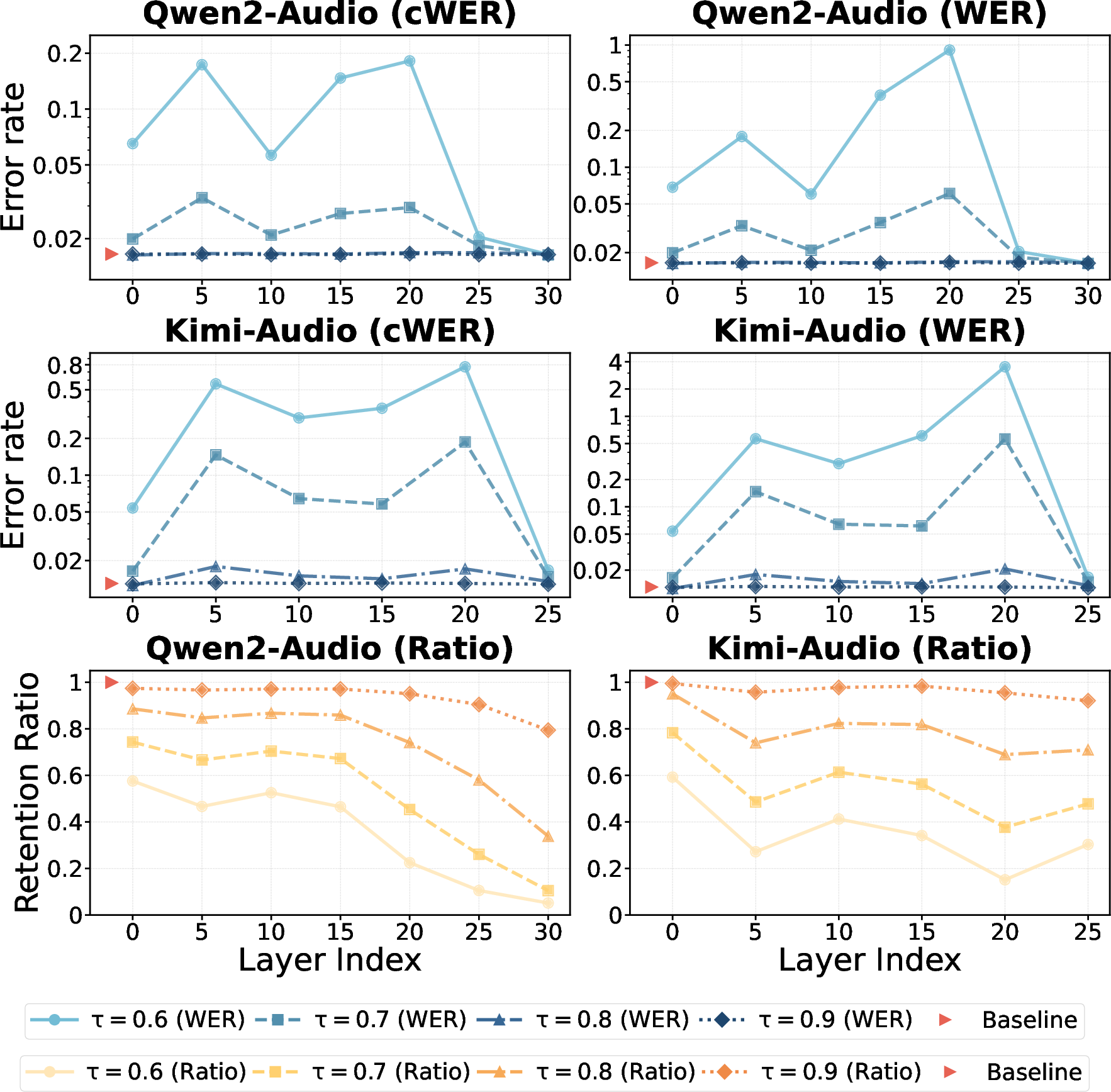
- The paper demonstrates that deep LSLM layers exhibit high semantic redundancy, enabling token retention rates as low as 25.67% without increasing WER.
- The paper introduces Affinity Pooling, a training-free token merging algorithm that leverages cosine similarity to reduce tokens by up to 85% while maintaining performance.
- The paper reveals a non-uniform redundancy structure across layers, with middle layers prone to instability and deep layers robust to aggressive compression.
Efficient Speech Token Representation and Redundancy in Large Speech LLMs
Motivation and Problem Statement
Large Speech LLMs (LSLMs) process audio using high tokenization rates—often at 12.5 to 25 tokens per second—resulting in input sequences that are significantly longer than the accompanying semantic content. This design preserves acoustic fidelity but incurs substantial computational and memory costs. Despite clear evidence of temporal redundancy in speech, prevailing LSLM pipelines lack mechanisms for selectively reducing redundant tokens at various stages. Additionally, the distribution of redundancy across model layers remains undercharacterized, thwarting efforts to deploy efficient, principled compression methods for speech token streams.
Layerwise Redundancy Analysis via Oracle Interventions
The paper conducts a systematic analysis of layerwise redundancy in two state-of-the-art LSLMs: Qwen2-Audio and Kimi-Audio. The approach leverages forced alignment to partition the audio token sequence into word-aligned semantic units and applies controlled interventions—compression operators including random drop, uniform drop, and uniform merge—at specific layers. Semantic recoverability is then quantified through Word Error Rate (WER) and clamped WER (cWER) on automatic speech recognition (ASR) tasks.
Key findings from these oracle interventions include:
- Redundancy increases monotonically with depth: Deep layers can sustain retention rates as low as 25.67% of the original tokens with almost no increase in WER, suggesting that these representations are extremely compressible.
- Non-uniform redundancy structure: Uniform Drop consistently outperforms Random Drop, indicating a structured temporal redundancy, while Uniform Merge provides the best results, likely due to the distributed encoding of semantic information.
- Acoustic-to-semantic transition: Middle layers demonstrate high instability and susceptibility to repetition, hallucination, and semantic drift, marking a critical transition from acoustic to semantic abstraction.
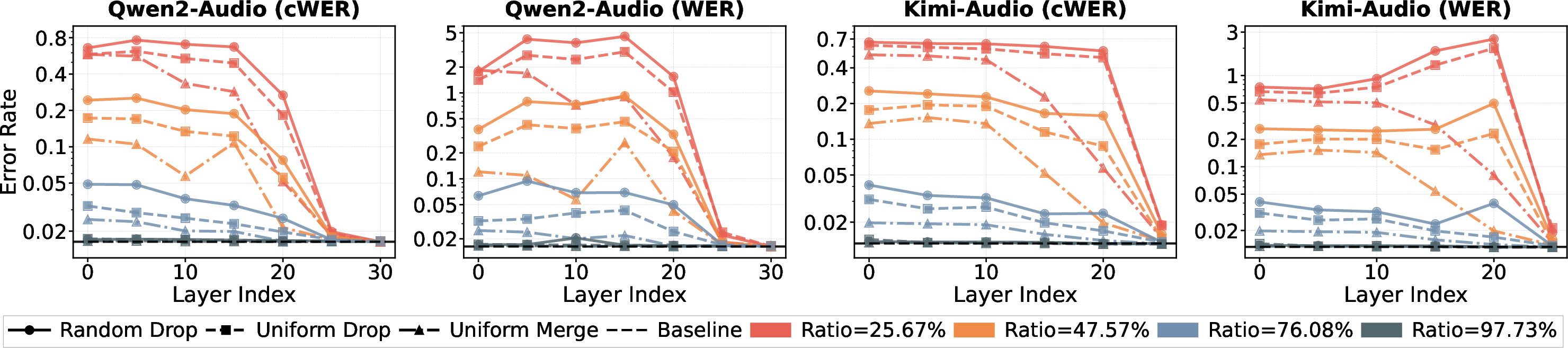
Figure 1: Layerwise oracle interventions on Qwen2-Audio and Kimi-Audio. Both clamped and standard WER show deep layers are highly robust to token compression.
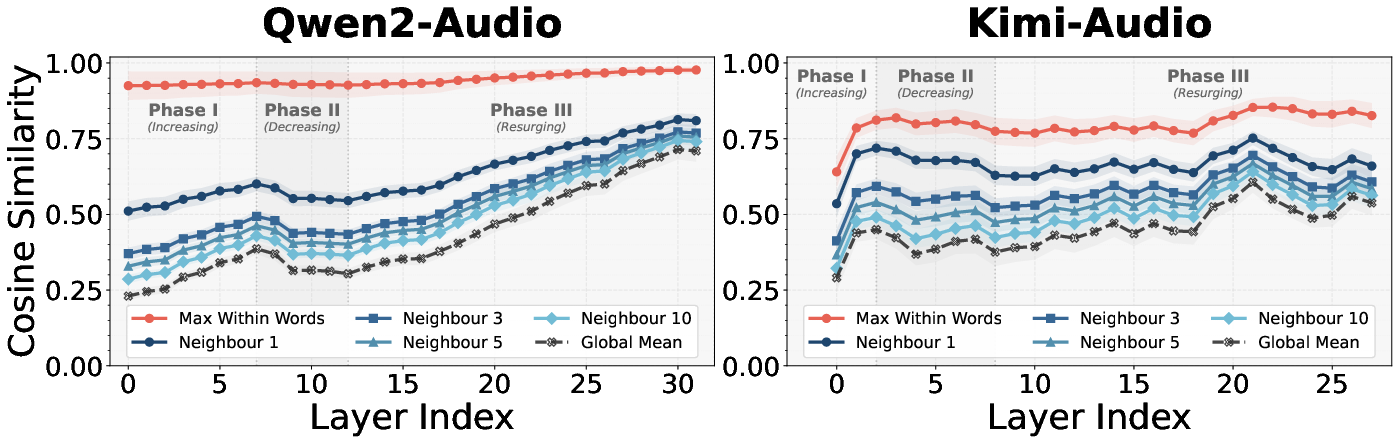
Figure 2: Cosine similarity metrics across layers reveal a rise–fall–rise trajectory, emphasizing local instability at intermediate depths and high redundancy at deep layers.
The cosine similarity analysis further reveals a "rise–fall–rise" pattern in local and global token similarity, with deep layers mapping multiple tokens corresponding to the same semantic unit into highly similar vectors. This directly explains the superior compressibility of deep representations.
Affinity Pooling: Training-Free Similarity-Based Compression
Motivated by the observed structure of redundancy, the authors introduce Affinity Pooling, an unsupervised, training-free token merging algorithm. This method aggregates temporally adjacent tokens based on cosine similarity, leveraging a configurable lookback window and similarity threshold.
Affinity Pooling is applied at both the input and deep layers, forming the Dual Affinity Pooling (DAP) approach. The method achieves three core outcomes:
Semantic Granularity and Decoding Robustness
Qualitative visualizations show that Affinity Pooling produces small token groups at shallow layers, while deep models merge entire phrases or multi-word units into individual tokens, confirming semantic abstraction and high information density.
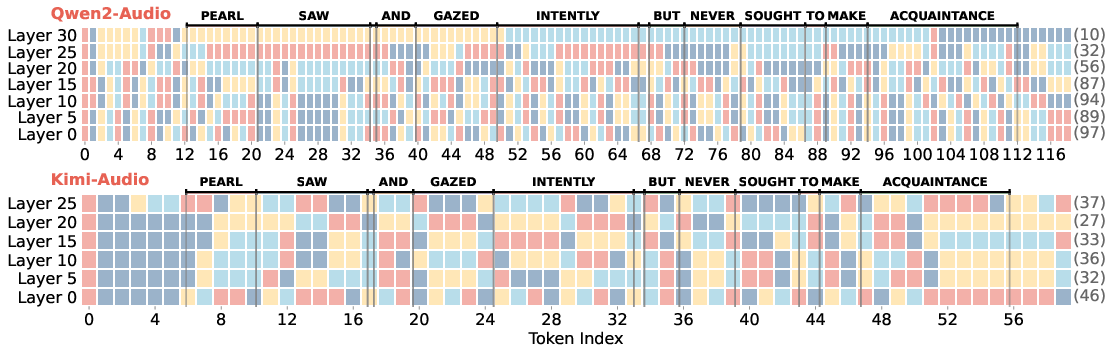
Figure 4: Visualization of Affinity Pooling (τ=0.7, ω=3) on Qwen2-Audio and Kimi-Audio; deep layers group multiple words into single, highly similar token clusters.
Representative decoding trajectories expose strong stability at input and deep layers under compression, but reveal failures such as looping or semantic drift at intermediate depths.
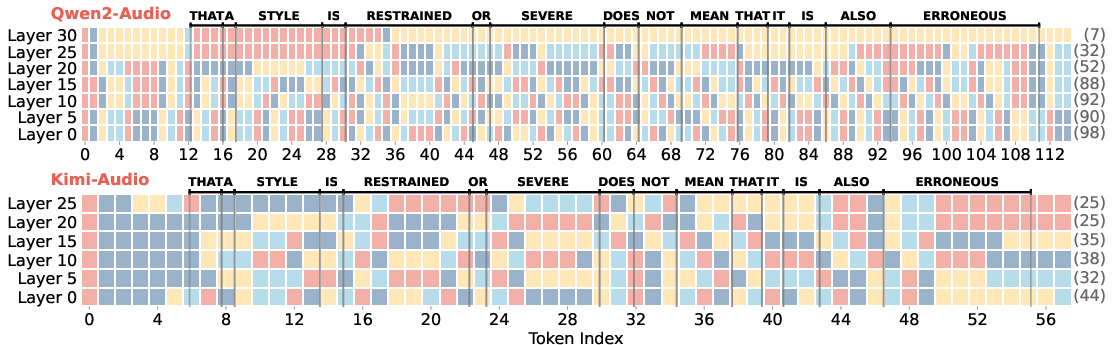
Figure 5: Decoding trajectories reveal that semantic integrity is preserved in deep and shallow layers even under heavy compression, while middle layers are unstable.
Experimental results on Qwen2-Audio and Kimi-Audio over ASR, speech QA, and speech translation benchmarks confirm that Affinity Pooling and DAP yield significant computational savings:
- Aggressive compression (DAP, τin=0.8, τdeep=0.7) achieves a Final Retention Ratio of 14.91% and a 27.48% reduction in FLOPs, with unchanged ASR (WER), QA (Acc), and ST (BLEU) scores.
- Deployment efficiency: On NVIDIA H200 hardware, DAP yields up to 1.7× memory savings and up to 1.1× speedup in time-to-first-token for long utterances.
Comparisons to signal-level speedup and linear interpolation baselines under fixed token budgets highlight the superior robustness of Affinity Pooling, especially at compression ratios below 70% retention.
Hyperparameter and Sensitivity Analysis
Systematic ablations indicate:
- The input embedding layer (l=0) is ideal for early compression, while deep layers (l≥25 for Qwen2-Audio, l≥24 for Kimi-Audio) are robust to aggressive token merging.
- The lookback window (ω) should be set to 1 at the input and broadened (e.g., ω=3) at depth to maximize semantic aggregation without accuracy loss.
(Figure 6), (Figure 7), (Figure 8)
Figure 6: Qwen2-Audio layer sensitivity validates only input and deep layers are robust to affinity-based compression.
Figure 7: Enlarging the lookback window improves deep-layer compression efficacy, but degrades input-layer fidelity.
Figure 8: Kimi-Audio layer sensitivity mirrors findings in Qwen2-Audio, with shallow and deep robustness.
Implications and Outlook
The study conclusively demonstrates that strictly distinct token representations at each speech timestep are unnecessary in deep LSLM layers, as these layers naturally abstract and replicate semantic information in highly redundant forms. This finding can fundamentally shift LSLM design and deployment, promoting dynamic, similarity-driven token pruning or merging and drastically reducing deployment costs for long utterances.
Practically, DAP can be integrated as an inference-time module—no retraining or backpropagation required—providing immediate inference acceleration and memory reduction in production ASR, speech QA, and ST systems. The empirical findings also suggest an information bottleneck transfer, with non-uniform semantic redundancy hierarchically distributed across network depths.
Theoretically, these results imply significant slacks in the representational and computational utilization of current LSLM architectures. Future models may integrate adaptive, data-driven token compression as a core architectural primitive, or even redesign token hierarchies that reflect the natural temporal and semantic structure of speech. The quantification of compression/accuracy tradeoffs provided here can enable more fine-grained control over cost/performance, particularly for edge deployment or real-time streaming applications.
Conclusion
This work establishes that LSLMs exhibit a clear, layerwise redundancy spectrum, with deep layers encoding highly compressible, semantically entangled representations. The proposed Affinity Pooling algorithm exploits this redundancy to deliver up to 85% token reduction and substantially improved inference efficiency, without degrading accuracy on ASR, QA, or ST tasks. By exposing the structural nature of speech token redundancy and validating efficient compression strategies, this research lays the groundwork for more computationally efficient and semantically faithful LSLMs in future real-world applications (2604.06871).