- The paper introduces a reversible hierarchical Markov chain to enable bidirectional reasoning and backward self-verification.
- It employs hierarchical pruning to reduce token consumption while maintaining semantic integrity across different layers.
- Experimental results demonstrate significantly improved accuracy on benchmarks like AddSub and GSM8K compared to traditional methods.
Cognitive Loop of Thought: Reversible Hierarchical Markov Chain for Efficient Mathematical Reasoning
Background and Motivation
Chain-of-Thought (CoT) prompting has served as a foundational strategy to enhance the mathematical reasoning capabilities of LLMs by decomposing complex tasks into explicit intermediate steps. Despite the empirical success of CoT and subsequent innovations such as Tree-of-Thoughts, Graph-of-Thoughts, and variants inspired by Markov chains, persistent issues remain. These include computational inefficiency due to excessive sequence lengths, error propagation, lack of robust backward verification, and the intrinsic memorylessness of classical Markovian architectures. Traditional self-correction mechanisms either require external feedback or often fail to reliably distinguish erroneous reasoning steps, leading to suboptimal robustness.
To address these limitations, the Cognitive Loop of Thought (CLoT) framework introduces reversible hierarchical Markov chains to foster bi-directional reasoning, enabling backward self-verification in addition to forward inference. The CLoT method not only advances interpretability and correctness, but achieves competitive efficiency through hierarchical pruning.
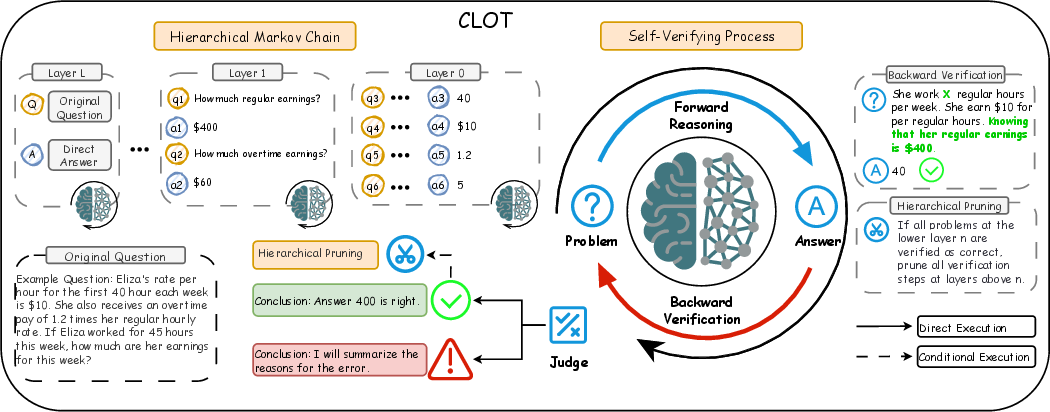
Figure 1: Overview of the CLoT Framework, illustrating hierarchical decomposition, bi-directional verification, and pruning mechanisms.
Method: Reversible Hierarchical Markov Chain and Bidirectional Verification
CLoT utilizes a hierarchical Markov process to model reasoning trajectories across multiple abstraction levels. Each layer in the hierarchy consists of sub-problems and associated derivation steps, with state transitions fulfilling the Markov property:
p(qt(l)∣qt−1(l),st−1(l)),
and cross-layer propagation functions for abstraction and refinement:
p(qt(l+1)∣qt(l)),p(qt(l)∣qt(l+1)).
Unlike memoryless Markov models, CLoT incorporates reversibility via backward verification. After forward refinement, the LLM reconstructs premises from conclusions, checking semantic consistency. A bi-directional coherence score is computed:
SRHMC=t=1∑Tlogp(st,q~t+1∣q~t)+t=1∑Tlogp←(st,q~t∣q~t+1),
where the backward term enables semantic-level backtracking rather than mere inversion. This dual-loop mechanism robustly flags logical inconsistencies and local errors absent from traditional forward-only schemes.
Hierarchical pruning exploits the dependency structure across abstraction levels. If global semantic consistency is confirmed at the highest level, lower-level verifications are pruned, typically lowering token consumption without sacrificing accuracy. Consistency metrics at each layer act as gatekeepers, ensuring pruning occurs only when the reasoning path is globally and locally validated.
CLoT-Instruct Dataset
To operationalize bidirectional reasoning, the authors constructed CLoT-Instruct, a dataset encoding both forward and backward reasoning trajectories for mathematical benchmarks. Each instance in CLoT-Instruct comprises:
- Original problem and ground truth answer
- Hierarchical decomposition into layers, each containing forward reasoning steps and associated backward verification prompts and answers
This design enables scalable supervision and intrinsic self-consistency tracking, facilitating instruction-tuning for LLMs toward cognitive loop reasoning.
Experimental Results
Comprehensive experiments across six benchmarks (AddSub, GSM8K, SVAMP, MATH, AQuA, CSQA) and three backbone models (GPT-4o-mini, GPT-4, DeepSeek-V3) reveal that CLoT delivers consistently superior accuracy and efficiency.
- Under GPT-4o-mini, CLoT achieves 99.0% accuracy on AddSub, outperforming CoT and CoT-SC by 4.1% and 2.9%, respectively.
- With GPT-4, CLoT attains 90.5% average accuracy, with substantial improvements on GSM8K (+1.2%) and AQuA (+3.8%) over competitive baselines.
Efficiency analysis demonstrates that CLoT, via hierarchical pruning, consumes just 136k tokens to solve 100 GSM8K problems, markedly lower than the 3.3M tokens required by Thought Rollback and about half of CoT-SC and CCoT.
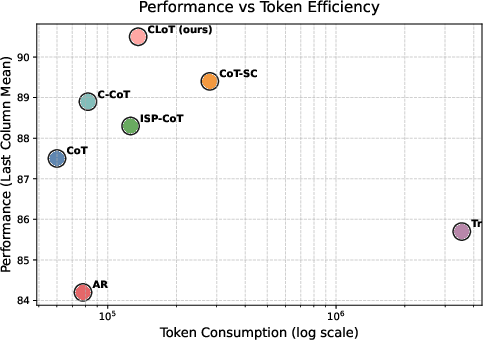
Figure 2: CLoT efficiency—token consumption for solving 100 GSM8K problems, showing significant improvements over traditional methods.
Dataset analysis reveals low error omission rates and high verification accuracy, particularly in multi-round settings for complex tasks. Ablation studies confirm the synergistic effect of reversible hierarchical reasoning and pruning, which yields both accuracy enhancement and efficiency gains.
Practical and Theoretical Implications
CLoT establishes a new paradigm for reasoning in LLMs by mathematically formalizing the cognitive loop of problem-solving and verification. The hierarchical reversible Markov chain provides a principled mechanism for maintaining long-range dependencies and local semantic integrity. Backward verification imbues models with introspective robustness, minimizing error propagation and reducing reliance on external ground truth or feedback.
Practically, CLoT’s efficiency and accuracy render it highly deployable in scenarios with computational constraints or correctness-critical applications, such as automated mathematics tutoring and advanced QA systems. The release of the CLoT-Instruct dataset provides a foundation for further research into bidirectional instruction tuning.
Theoretically, CLoT stimulates future investigations into cognitive architectures for LLMs, such as the extension to multimodal environments, creative reasoning, and domains with ambiguous premises. The hierarchical reversible framework may catalyze advances in interpretability, controllability, and autonomous error correction, bridging gaps between formal reasoning and emulation of human cognition.
Conclusion
CLoT introduces reversible hierarchical Markov chains, backward verification, and hierarchical pruning to mitigate the limitations of classical CoT frameworks. Strong empirical results validate the robustness and efficiency of this bi-directional reasoning protocol. By shifting from linear chains to closed cognitive loops, CLoT advances the development of self-correcting and autonomous reasoning agents. The proposed methodology, dataset, and analysis offer substantial avenues for further exploration in reliable AI reasoning.

