- The paper introduces a listener-driven interruption paradigm that dynamically manages message flow based on real-time context sufficiency.
- It employs the HandRaiser model trained via supervised finetuning to predict optimal interruption points, achieving up to 32.2% token savings.
- Experimental results across diverse benchmarks demonstrate robust performance and transferability of the framework in multi-agent environments.
Interruptible Listener-Oriented Communication in Multi-Agent LLM Systems
Introduction and Motivation
LLM-based multi-agent systems are emerging as scalable solutions for complex tasks in reasoning, coordination, and simulated social environments. However, a critical bottleneck in these systems is the rapid accumulation of verbose, redundant communications, leading to context window overflow, inference latency, and mounting compute costs. Traditional techniques focus on speaker-side message compression, yet these strategies fail to flexibly adapt to the heterogeneous informational needs of different downstream listeners and cannot efficiently identify redundant content dynamically. This paper proposes a paradigm shift toward listener-driven communication efficiency by introducing an interruptible communication framework where listening agents can dynamically signal the speaker to halt, controlling the granularity and timing of message exchanges.
Listener-Oriented Interruptible Communication Framework
The cornerstone of the paper is the formalization and implementation of an interruptible, listener-oriented communication protocol for LLM-based multi-agent systems. In this protocol, the speaker (e.g., Alice) generates messages in discrete chunks, transmitting each as soon as it is produced. The listener (e.g., Bob) evaluates, after each chunk, whether the accumulated information suffices to act or if more context is necessary. When Bob deems the message sufficient or identifies confusion, he may send an interruption signal, halting Alice's generation and promptly responding. This paradigm mirrors certain dynamics in human dialogue, allowing the interlocutor to control input adaption and interaction flow.
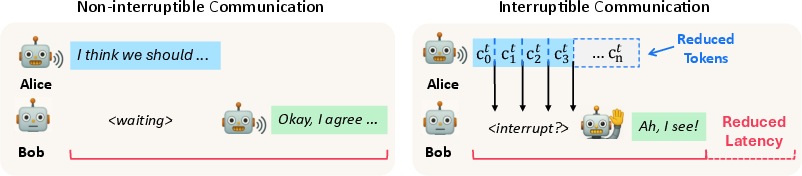
Figure 2: Comparison between non-interruptible (full message transfer) and interruptible (chunk-wise, listener-mediated) communication protocols, illustrating reduced context growth and latency in the latter.
This adjustment enables each listener to optimally truncate input, rather than rely on a one-size-fits-all speaker-side compression. As observed in settings like the Text Pictionary game, listener-driven interruption accommodates varying listener inference capabilities, which a fixed speaker-oriented compression cannot address.
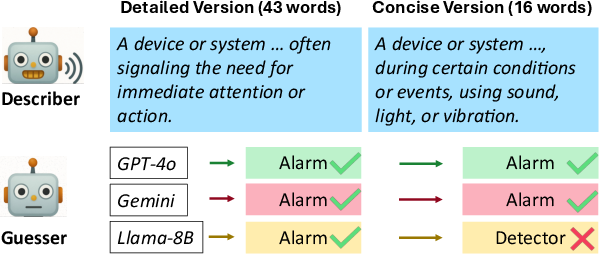
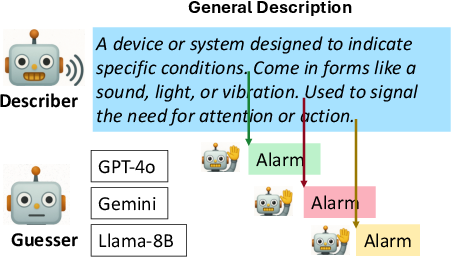
Figure 1: Speaker-side compression fails to generalize across listeners, whereas listener-side interruption allows personalized truncation.
Learning Algorithm: Optimal Interruption Point Prediction
A key challenge is algorithmically determining when an interruption yields an optimal balance between communication cost and downstream task performance. Simple prompting approaches exhibit systematic overconfidence—LLMs tend to interrupt too early, incorrectly inferring sufficient context and thus hampering overall task progress.
To address this, the proposed HandRaiser model is trained via supervised finetuning on conversation rollouts. Each token chunk is annotated post hoc using a tree-based sampling strategy, estimating the future expected cost and task success payoff of interrupting versus continuing. This enables the model to learn a policy that, given dialogue history and current message prefix, predicts the interruption point that minimizes ΔCost (fewer generated tokens) while maximizing ΔPerf (maintaining or improving task reward).

Figure 3: Tree-sampling structure for estimating expected communication cost and performance payoff at each potential interruption point.
Supervised finetuning on this interruption dataset leads to a robust interruption prediction policy that is empirically validated across different communication tasks.
Experimental Evaluation
Benchmarks and Baselines
The experiments span three diverse multi-agent benchmarks:
- Textual Pictionary: Two agents (describer, guesser), with the guesser allowed to interrupt once confident.
- Meeting Scheduling: Three agents (traveler, two planners) negotiating complex meeting schedules under private constraints.
- MMLU-Pro Debate: Three agents (pro, con, moderator), moderator may interrupt debates early upon confident solution identification.
Comparison is made against (i) non-interruptible generic and concise speaker baselines, (ii) random interruption, and (iii) prompt-based interruption.
Results
HandRaiser achieves comparable or superior task performance with pronounced reductions in communication cost: up to 32.2% overall (notable 48.9% in debate, 24–23% in the other tasks). In all scenarios, success rates remain on par or improve slightly versus the strongest baselines, despite substantial token savings.
Premature interruption—particularly from prompt-based policies—significantly degrades performance, increasing rounds/latency and failing to reduce net cost, a direct consequence of LLM overconfidence and lack of grounding in future payoff estimation.
HandRaiser demonstrates robust transferability: interruption behaviors trained on one set of speaker models (e.g., Llama-70B, GPT-4o, Gemini-2.0-flash) generalize well to unseen speakers, underscoring the task-level generality of the learned policy.
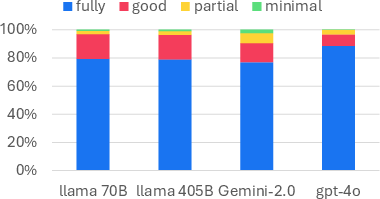
Figure 4: Overconfidence in prompt-based GPT-4o listeners leads to early interruption even when comprehension is lacking, as shown by self-reported understanding distributions on incorrect guesses.
Ablation on chunk size and decision thresholds reveals a U-shaped tradeoff—small chunk sizes (frequent checking) do not yield further gains and are not beneficial, while excessively conservative thresholds delay interruption, impacting cost without task benefit.
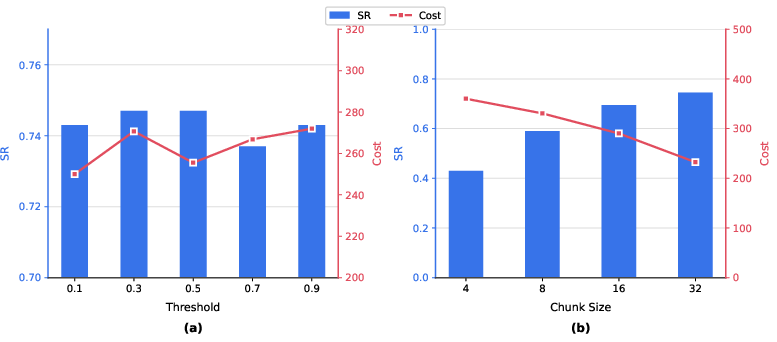
Figure 5: Ablation results: Success ratio and cost as a function of interruption probability threshold and chunk size.
Implications, Limitations, and Future Directions
This paper establishes that dynamic, learned listener-side interruption policies yield critical reductions in communication cost and system latency for multi-agent systems, improving the scaling characteristics of LLM-based collectives. Unlike speaker-side compression, these policies are inherently personalized, adaptable to listener needs, and robust to heterogeneity in agent capabilities.
The practical implication is a blueprint for efficiently orchestrating large multi-agent LLM deployments for agentic workflows, code synthesis, collaborative scheduling, and debate—anywhere listener needs deviate from a static canonical message structure.
Notably, the approach is extensible to context-rich mixes; for example, adapting to multiple interruptible agents (as shown in extension experiments), and composable with independent speaker-side compression for further efficiency. Analysis suggests HandRaiser-trained policies are not dependent on a single communication protocol or agent architecture, but rather leverage transferable interruption behaviors. However, (1) excessive interruption by ungrounded listeners in free-form protocol variants, and (2) the cost of initial rollout-based policy generation for new task domains, remain open optimization questions.
Conclusion
This work demonstrates that learning when to interrupt—rather than compressing from the speaker side—enables scalable, listener-personalized efficiency in LLM-based multi-agent systems. The HandRaiser framework yields significant compute and latency savings with no loss (and sometimes improvement) in goal success, transfers robustly across tasks and agent architectures, and establishes a principled methodology for listener-side communication control. This approach should inform future work in agentic communication topology, context management, and resource-optimal collaborative AI deployment.

