- The paper demonstrates that instruction following in LLMs relies on task-specific skill coordination rather than a universal constraint mechanism.
- It employs diagnostic probing and INLP-based causal ablation across diverse tasks to reveal sparse, asymmetric dependencies among linguistic representations.
- The study challenges aggregated compliance benchmarks and suggests targeted interventions on model-specific linguistic subspaces for enhanced instruction fidelity.
Coordination of Linguistic Skills in LLM Instruction Following: Evidence Against a Universal Mechanism
Introduction
This essay provides a technical synthesis and analysis of "How LLMs Follow Instructions: Skillful Coordination, Not a Universal Mechanism" (2604.06015). The study interrogates a foundational assumption in instruction tuning for LLMs: the existence of a universal, task-invariant mechanism for constraint satisfaction during instruction following. Employing an array of diagnostic probing methodologies across nine linguistically diverse tasks and multiple instruction-tuned models, the work presents strong evidence refuting the notion of a general constraint satisfaction mechanism. Instead, the results support a model in which compositional skill deployment and sparse, asymmetric representational dependencies underlie instruction following.
Methodological Framework
The core methodological contribution is a diagnostic probing and intervention framework explicitly designed to disentangle task-specific skill deployment from putative general constraint satisfaction signals. Key experimental axes include:
- Specialist versus general probes to directly compare task-specific versus task-agnostic decoding capability.
- Cross-task transfer and causal ablation using Iterative Null-space Projection (INLP) to assess the degree of information sharing and causal dependence between tasks.
- Analysis of representational specificity by projecting unconstrained versus constrained activations onto extracted rowspaces.
- Temporal dissection of when, during the generation sequence, constraint satisfaction signals appear.
- Cross-task representational similarity quantified by PWCCA and hierarchical clustering.
The probed models—Llama 3.1 8B Instruct, Gemma 2 2B IT, and Qwen2.5-0.5B-Instruct—span a range of scales and architectures, strengthening the generality of the findings.
Universality and Task Stratification
Specialist vs. General Probes
Specialist probes consistently outperform their general (task-agnostic) counterparts across all evaluated conditions. General probes do not achieve peak accuracy for any task or model, indicating a lack of a universal representational axis for constraint satisfaction (see Figure 1).
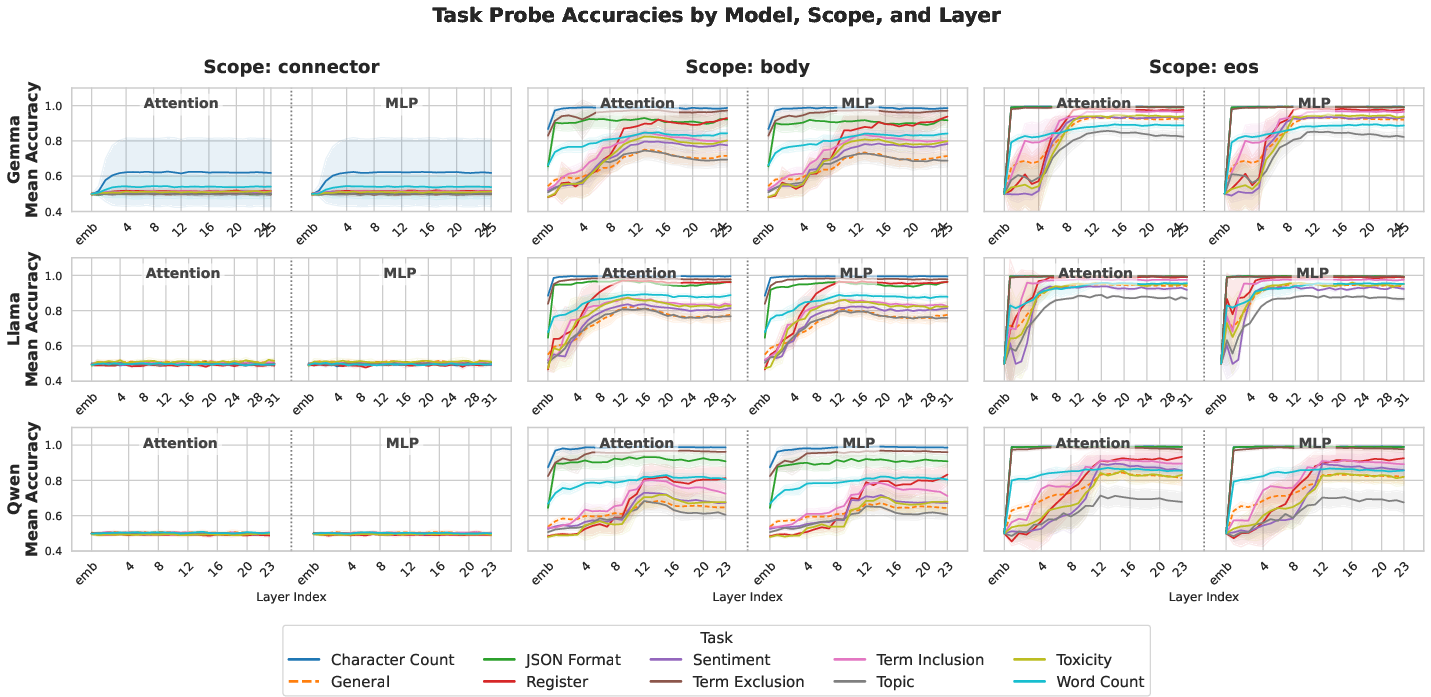
Figure 1: Probe accuracy across network layers for attention (left) and MLP (right) streams, with general probes failing to reach specialist probe performance.
Layer-wise analysis reveals stratification by linguistic complexity: structural and lexical tasks (e.g., character count, word count) reach high accuracy in early layers; semantic and stylistic tasks (e.g., sentiment, register, topic) emerge later, supporting the view that different classes of constraints are encoded at distinct abstraction levels within the network.
Cross-task Transfer and Causal Ablation
Cross-task transfer is highly clustered—specialist probes only meaningfully transfer to related tasks. INLP-based causal ablation exposes sparse and asymmetric dependencies rather than the dense interdependence expected under a universal mechanism. The information excised by general probes is not required for specialist performance, indicating that what little is universal is neither sufficient nor necessary for task adherence.
Representational Specificity
Projection of unconstrained activations (null task baseline) onto task rowspaces demonstrates substantial inter-model variation (Figure 2). Llama exhibits low null task intensity and strong success-failure separation, suggesting high constraint specificity. In contrast, Qwen’s null task projections are entangled with those of constrained tasks, indicating that its probes often capture generic linguistic features rather than constraint-specific signals.
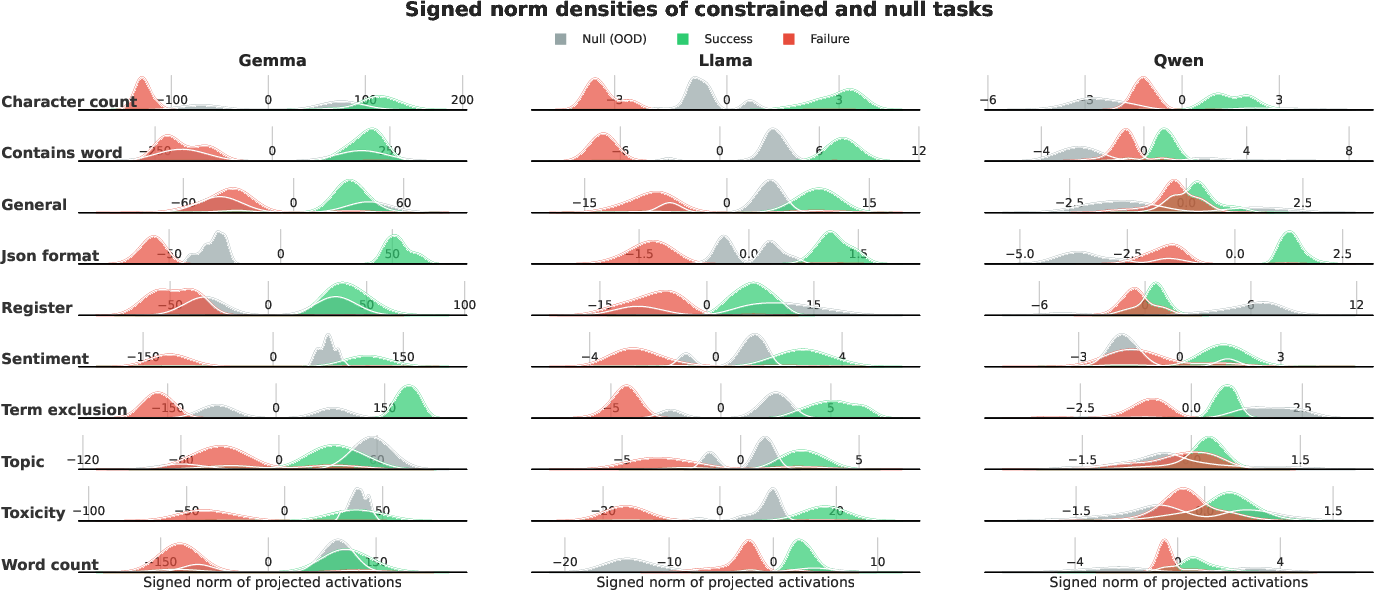
Figure 2: Density distributions show the degree of separation between constraint-following and unconstrained activations within rowspace projections.
This finding is further supported by the tight correlation between representational specificity and the generalization capacity of probes: models with more disentangled and abstract constraint representations (Llama) display superior cross-task generalization.
Temporal Dynamics of Constraint Satisfaction
Temporal probing reveals that constraint satisfaction signals are largely absent during pre-generation stages (e.g., in connector tokens), only emerging as generation unfolds (Figure 3). Accuracy for predicting constraint compliance rises sharply after the generation begins, remains high throughout the response, and generally peaks at the EOS token—implying that satisfaction monitoring, rather than planning, is the dominant operational mode.
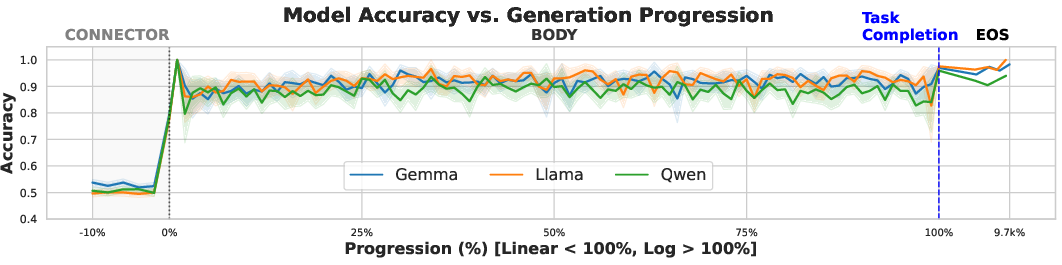
Figure 3: Best linear probe accuracy as a function of generation progression, showing late emergence and EOS peaks in all models.
This is incompatible with a premised static, globally active constraint satisfaction mechanism, disputing proposals relying on a first-token “compliance predictor.”
Representational Geometry and Task Clustering
PWCCA-based hierarchical clustering of INLP rowspaces reveals distinct and often model-specific clusters of tasks (Figure 4). There is substantial diversity in both representational overlap and in how architectures encode and compose skill subspaces. Task pairings (e.g., term exclusion with toxicity, structural formatting grouped together) suggest the emergence of reusable primitives, but no evidence of a singular, universal constraint-following subspace.
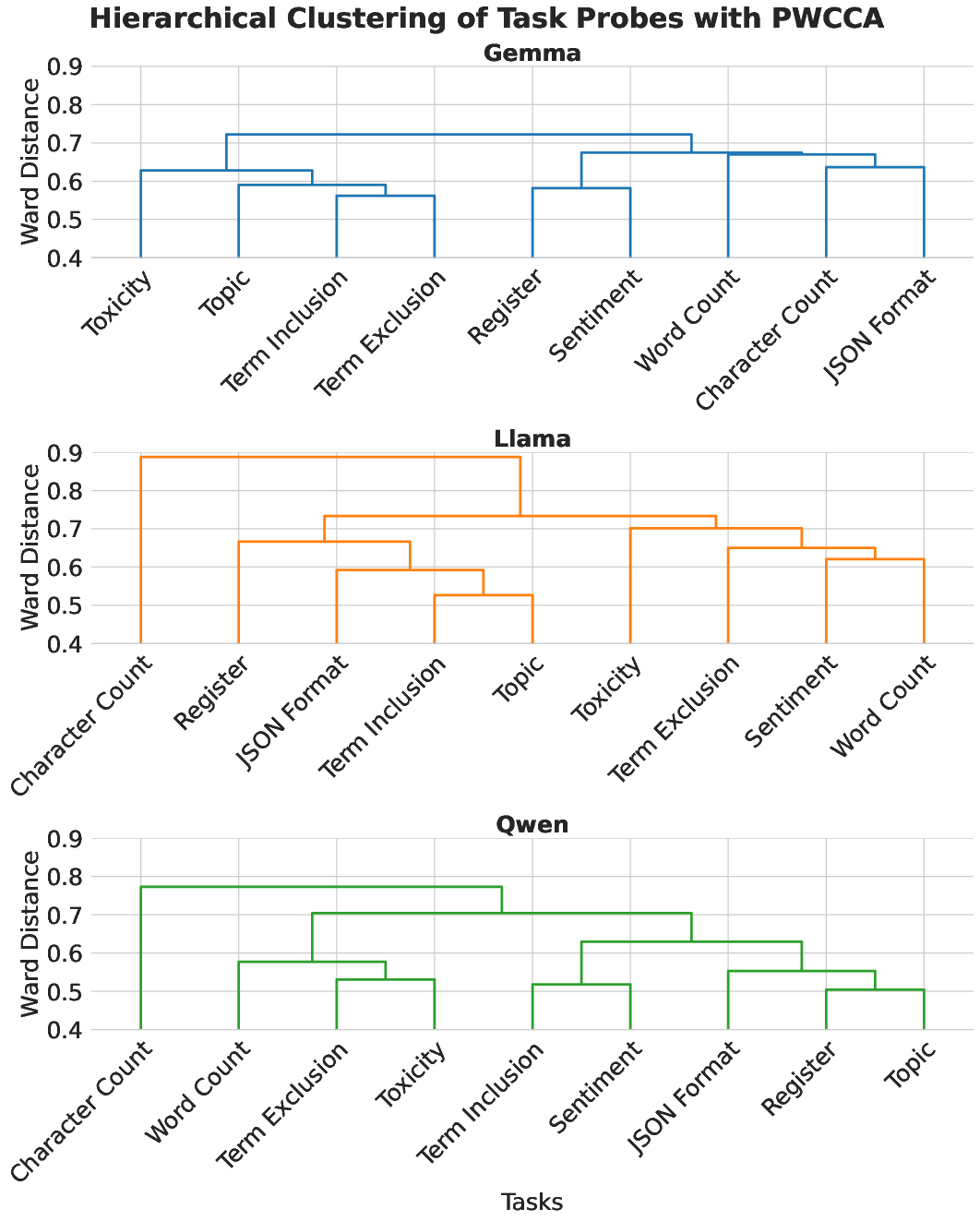
Figure 4: Dendrograms reveal task clusters by representational PWCCA similarity, with substantial variation across models and no universal structure.
Implications and Future Directions
The falsification of a universal constraint satisfaction mechanism in instruction-tuned LLMs provokes a multivalent reconsideration of both evaluation and model development paradigms. The results strongly suggest that instruction following is achieved by skillful, context-dependent coordination of diverse, partially shared linguistic submodules. Task-specific skill disentanglement and compositionality, rather than monolithic abstraction, underpin robust adherence.
Theoretical Implications
- The findings support a compositional theory of neural instruction following, in line with modular representations observed in cognitive neuroscience.
- The observed stratification and model dependence highlight the importance of representational geometry—not just raw capability metrics—in understanding LLM operation.
Practical Implications
- Approaches to enhance instruction fidelity should focus on targeted intervention and “rowspace steering” in task-relevant subspaces, not universal control vectors.
- Aggregated compliance benchmarks may mask underlying skill deployment and coordination failures.
- Model scaling appears to improve the precision and disentanglement of skill coordination, not universality per se.
Future Work
Key open directions include elucidating the geometric organization of reusable linguistic primitives, probing multi-constraint prompt cases to test skill composability limits, and extending these diagnostics to more diverse and larger-scale architectures.
Conclusion
"How LLMs Follow Instructions: Skillful Coordination, Not a Universal Mechanism" (2604.06015) presents detailed empirical and analytical evidence against the existence of a universal task-agnostic instruction-following mechanism in current instruction-tuned LLMs. Instead, the results reveal dynamic, context-dependent activation of compositional, loosely shared linguistic skills, stratified by abstraction and organized in model-specific representational geometries. This paradigm shift invites refinements in both theoretical interpretation and practical intervention strategies within the study of neural instruction following.