- The paper introduces a novel reference-free RL approach that unifies long-form planning with short-form spontaneous generation.
- It employs an adaptive reward model (AC-GenRM) and group-based optimization to enhance both structural coherence and creative expressiveness.
- Empirical results show significant gains in narrative structuring and expressive output, highlighting emergent meta-cognitive capabilities.
UniCreative: Unifying Paradigms for Creative Text Generation via Reference-Free RL
Introduction
The paper "UniCreative: Unifying Long-form Logic and Short-form Sparkle via Reference-Free Reinforcement Learning" (2604.05517) addresses the core challenge in creative text generation: reconciling the divergent requirements of long-form logical coherence and short-form expressive spontaneity. Existing LLMs are limited by their reliance on static alignment pipelines and high-quality supervised reference data, which are neither economically scalable nor adaptable to tasks with inherently subjective evaluation signals. The authors propose a unified reinforcement learning (RL) framework that adaptively selects between Plan-then-Write and Direct Generation paradigms, employing a novel reference-free RL approach that facilitates emergent meta-cognitive capabilities.


Figure 1: Examples of UniCreative generations. The long-form task (left) follows a Plan-then-Write procedure, while the short-form task (right) employs direct generation without intermediate planning.
Methodological Framework
Dual-Mode Creative Generation
UniCreative decomposes creative writing into two regimes: tasks requiring macroscopic planning for long-range consistency and those favoring high-entropy, stochastic expressiveness. The system introduces an explicit computational switch, leveraging a Plan-then-Write mode for narratives that require hierarchical reasoning and Direct Generation for tasks where planning induces over-determination and linguistic homogenization.
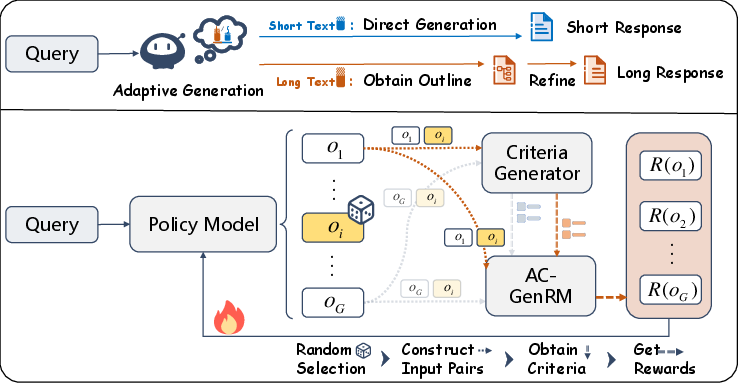
Figure 2: The UniCreative architecture selects between planning or direct modes per task and optimizes via ACPO using feedback from the generative reward model.
Adaptive Constraint-Aware Reward Modeling
Central to UniCreative is AC-GenRM, a generative reward model performing dynamic criteria synthesis and debiased pairwise judging. Unlike prior static, scalar reward frameworks, AC-GenRM synthesizes query-specific evaluation dimensions Cx based on each prompt and trains with symmetrical data augmentation to enforce position-invariant quality discrimination. This alleviates known biases in LLM judges and enhances alignment with expert creative standards.
Reference-Free Reinforcement Learning: ACPO
The Adaptive Constraint Preference Optimization (ACPO) method eschews SFT and external ground-truth references. Instead, it leverages group-based internal rollouts, combining three orthogonal RL signals:
- Relative rewards from self-play driven by AC-GenRM judgments
- Paradigm-aware structural penalties to enforce contextually appropriate cognitive regimes
- Adaptive length regularization to prevent mode collapse—either content starvation in long-form or verbosity in short-form
Policy updates use Group Relative Policy Optimization (GRPO), normalizing reward signals within groups to reduce variance and stabilize optimization without auxiliary value models.
Empirical Evaluation
On WritingBench, UniCreative exhibits robust improvements over diverse open-source and proprietary LLMs. For instance, Qwen3-8B-Thinking + RL achieves competitive average scores (82.42), rivalling Claude-Sonnet-3.7 and DeepSeek-R1, and surpasses much larger instruction-tuned baselines (e.g., Llama-3.3-70B-Instruct, Qwen-2.5-72B) by margins exceeding 20–30 points. Notably, RL alignment boosts compliance in structurally-intensive requirements (style, format, length), overcoming the structural drift and topic degradation typical of base autoregressive models.
On the Blessing short-form benchmark, reference-free RL enables the model to bypass rigid planning when detrimental, with Qwen3-8B-Thinking + RL attaining 93.6% “excellent” ratings, matching Claude-Sonnet-4.5. The RL-optimized models gain 17–26% over “thinking” baselines, empirically confirming that adaptive switching restores the linguistic diversity and emotional resonance suppressed by SFT and monolithic planning.

Figure 3: Illustrates over-determination, where inappropriate application of planning impairs short-form creative generation.

Figure 4: Structural collapse arises in long-form generation without explicit macroscopic planning, leading to incoherent narratives.
Reward Model Evaluation
AC-GenRM, the learned critic, demonstrates strong agreement rates (80.7%) with expert LLM judges, outperforming major discriminative baselines and minimizing verbosity bias. The architecture’s ability to generate transparent, human-interpretable evaluation rationales (Figure 5) represents a substantive advance in explainable reward modeling.

Figure 5: AC-GenRM dynamically generates task-adaptive criteria for each evaluation instance.
A salient contribution is the emergence of robust task regime discrimination in models with adequate capacity. On Mode Discrimination Benchmarks, models at the 4B and 8B scale attain up to 96% accuracy in selecting the optimal generation strategy per prompt, a property absent in sub-2B models due to parameter bottlenecks. This empirical trend suggests that meta-cognitive inference—the ability to map latent prompt complexity to the correct computational pathway—emerges as a function of model size and is not encoded by SFT or static RL alignment alone.
Analysis and Implications
The results have far-reaching theoretical and practical implications. The framework operationalizes a move from static, reference-anchored alignment to dynamic, reward-driven self-organization—aligning with the “reward modeling as reasoning” trend in RLHF research. By decoupling the creative feedback signal from expensive, often ill-defined ground-truth annotations, UniCreative dramatically improves scaling for open-ended, subjective tasks.
On the practical front, the reference-free dual-mode RL paradigm is well-positioned for large-scale, cost-effective model alignment in domains where ground-truth is ambiguous (ideation, artistic writing, “sparkle-first” applications). The transparency of AC-GenRM criteria generation offers the additional benefit of interpretability, enhancing trust in deployed generative systems.
However, significant model capacity is required for stable emergent behavior; lightweight models fail to balance structural logic and linguistic vibrancy. In addition, the framework recognizes limitations in intermediate-length (“gray area”) tasks and exposes the high computational overhead of ultra-long context RL training, presenting challenges for practitioners with limited hardware.
Future Directions
Potential extensions include:
- Soft or hierarchical planning strategies for intermediate regimes
- Reducing RL sample and compute requirements via more efficient group-based updates
- Fusing dynamic reward modeling with cross-domain planning for broader creative task generalization
- Exploiting meta-cognitive signals for prompt-adaptive LLMs in diverse, open-ended tasks
Conclusion
UniCreative formalizes, for the first time, a scalable RL-based approach to unifying long-form structural reasoning and short-form spontaneity in creative text generation, without reliance on SFT or ground-truth completions. The joint adoption of AC-GenRM and ACPO enables interpretability, RL curriculum alignment, and an emergent capacity for meta-cognitive task differentiation. These innovations provide a new foundation for scalable, adaptive LLM alignment in subjective, high-entropy creative domains.