- The paper presents STAMP, integrating Semantic Adaptive Pruning and Multi-step Auxiliary Prediction to address inefficiencies and performance instability in SID-based recommendation.
- The methodology leverages token saliency and attention centrality to prune redundant tokens, achieving significant VRAM reductions and training speedups.
- Empirical evaluations on academic and industrial benchmarks demonstrate that STAMP maintains or improves accuracy, showcasing its scalable, architecture-agnostic design.
Semantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation: An Expert Analysis
Introduction
The transition from atomic ID-based generative recommendation (GR) to Semantic ID-based generative recommendation (SID-GR) has fundamentally altered the landscape of recommender systems by leveraging hierarchical item tokenization to improve generalization across large item corpora. However, this paradigm introduces significant computational and optimization challenges, principally attributable to increased sequence lengths and supervision sparsity. "Semantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation" (2604.05329) introduces a comprehensive solution, STAMP, that explicitly confronts these challenges via a dual-end strategy: Semantic Adaptive Pruning (SAP) and Multi-step Auxiliary Prediction (MAP). The theoretical foundation, empirical evidence, and architecture-agnostic design demonstrate the efficacy of STAMP as a practical approach to reconcile efficiency and robustness in GR systems.
Problem Analysis: Semantic Dilution Effect in SID-GR
SID-GR augments the item space via high-granularity semantic decomposition, represented as sequences of SIDs. This approach, although beneficial for mitigating cold-start and vocabulary explosion, leads to two tightly coupled, previously under-explored challenges:
- Training inefficiency: Sequence expansion via tokenization increases input length by a factor of L, where L is the SID granularity, leading to quadratic computational and memory growth.
- Performance instability: Empirically, finer-grained SID representations yield non-monotonic and often degraded performance, with observed accuracy fluctuations as SID vocabularies and sequence lengths grow. The underlying causal mechanism is the Semantic Dilution Effect—information non-uniformity in the input (redundant tokens diluting sparse learning signals) and supervision sparsity at the output.
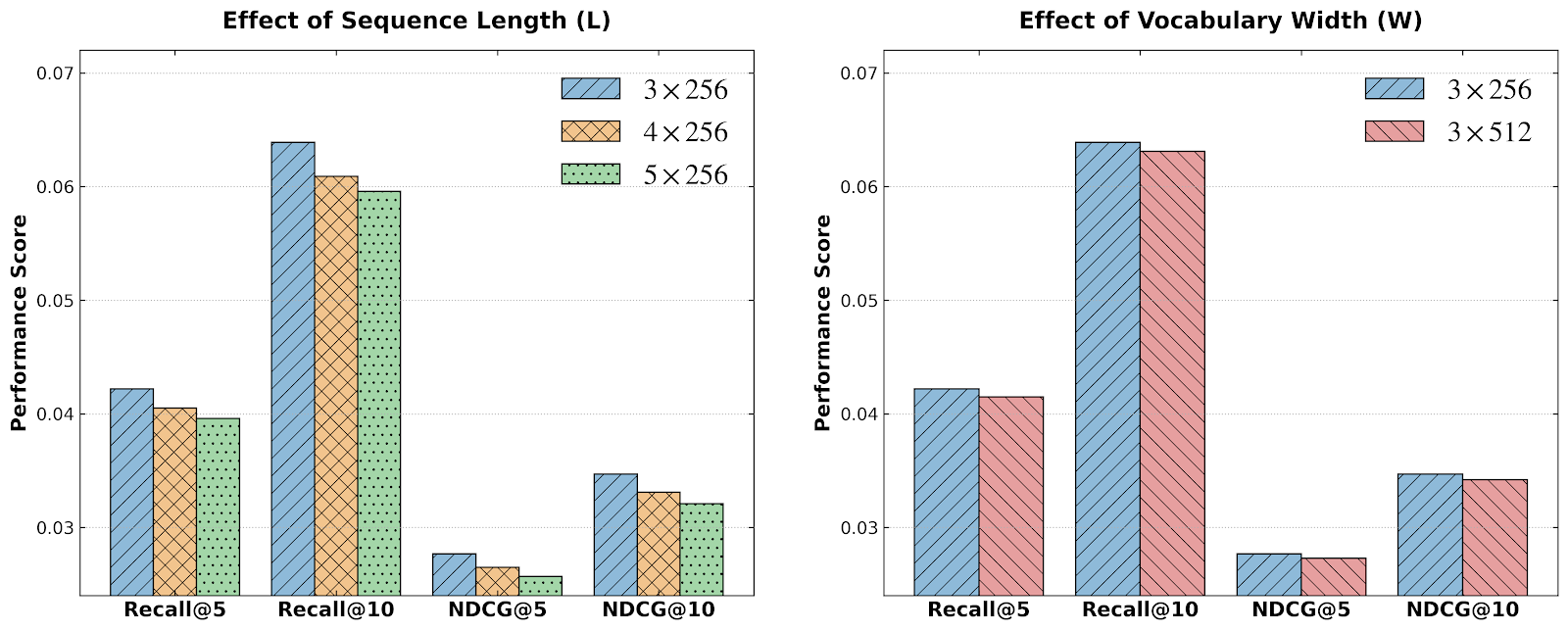
Figure 1: The adoption of finer-grained SID representations, entailing longer sequences and larger vocabularies, results in performance degradation.
Existing mitigations such as KV-caching and general token pruning transfer poorly, given the structurally dense and interdependent nature of SIDs and the unique requirements of recommendation over natural language generation.
The STAMP Framework
STAMP addresses Semantic Dilution from two orthogonal axes:
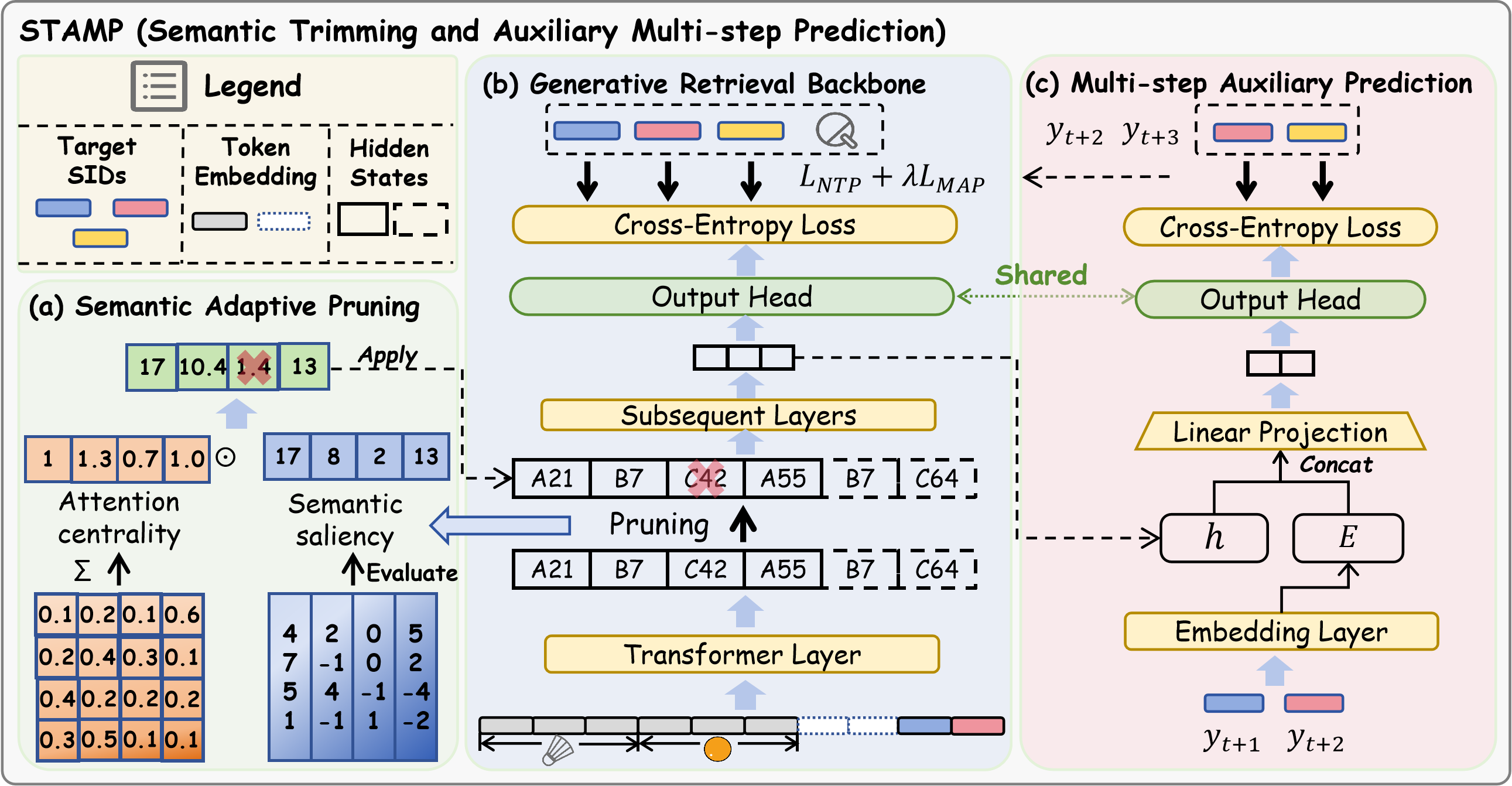
Figure 2: Overview of the STAMP framework, showing the SAP pruning path and the MAP multi-token prediction head.
Semantic Adaptive Pruning (SAP)
SAP dynamically identifies and prunes redundant tokens during the forward pass, leveraging:
- Semantic saliency: Token-level ℓ1-norm feature magnitude.
- Attention centrality: Aggregated attention mass across heads to capture context dependencies.
The token importance score is the product of saliency and centrality. Tokens are pruned by rank, preserving a protected window for autoregressive targets and maintaining sequence order. This enables substantial acceleration and VRAM reduction even in deep models.
Multi-step Auxiliary Prediction (MAP)
MAP densifies output supervision using a multi-token prediction objective. It concatenates the current hidden state with the embedding of the ground-truth next token, using a shared unembedding head. The auxiliary loss is introduced at train time only and guides the model to learn long-range dependencies lost through input compression.
Experimental Evaluation
STAMP's claims are supported by extensive experiments on both academic (Amazon/GRID, using T5) and industrial (AL-GR-Tiny/FORGE, using Qwen) benchmarks. Key experimental findings include:
Efficiency and Accuracy:
- Training speedup: 1.23–1.38× (with up to 54.7% VRAM reduction) on T5/GRID and 1.34× (17.2% VRAM reduction) on Qwen/FORGE.
- Accuracy preservation/improvement: STAMP not only matches but occasionally surpasses the baseline model's accuracy, especially with moderate pruning following initial feature aggregation. Importantly, the framework is agnostic to backbone architecture and dataset composition.
Ablation Results:
- SAP alone yields notable efficiency gains; in certain datasets (e.g., Beauty, Toys), it also improves denoising and recommendation quality, confirming the prevalence of non-informative tokens.
- MAP provides independent improvements by supplementing supervision, useful even apart from pruning.
- STAMP achieves the full synergy of SAP's efficiency and MAP's robustness.
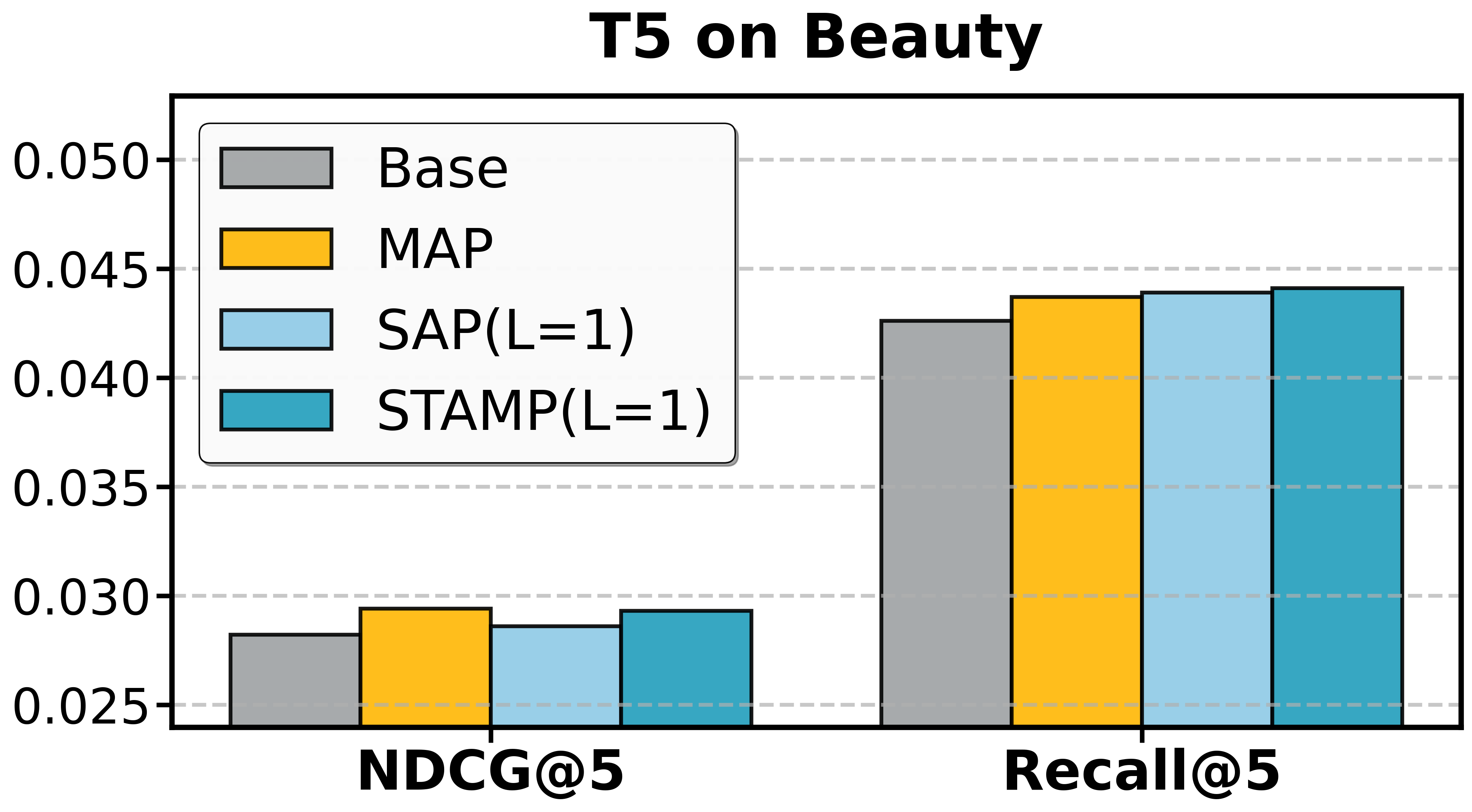
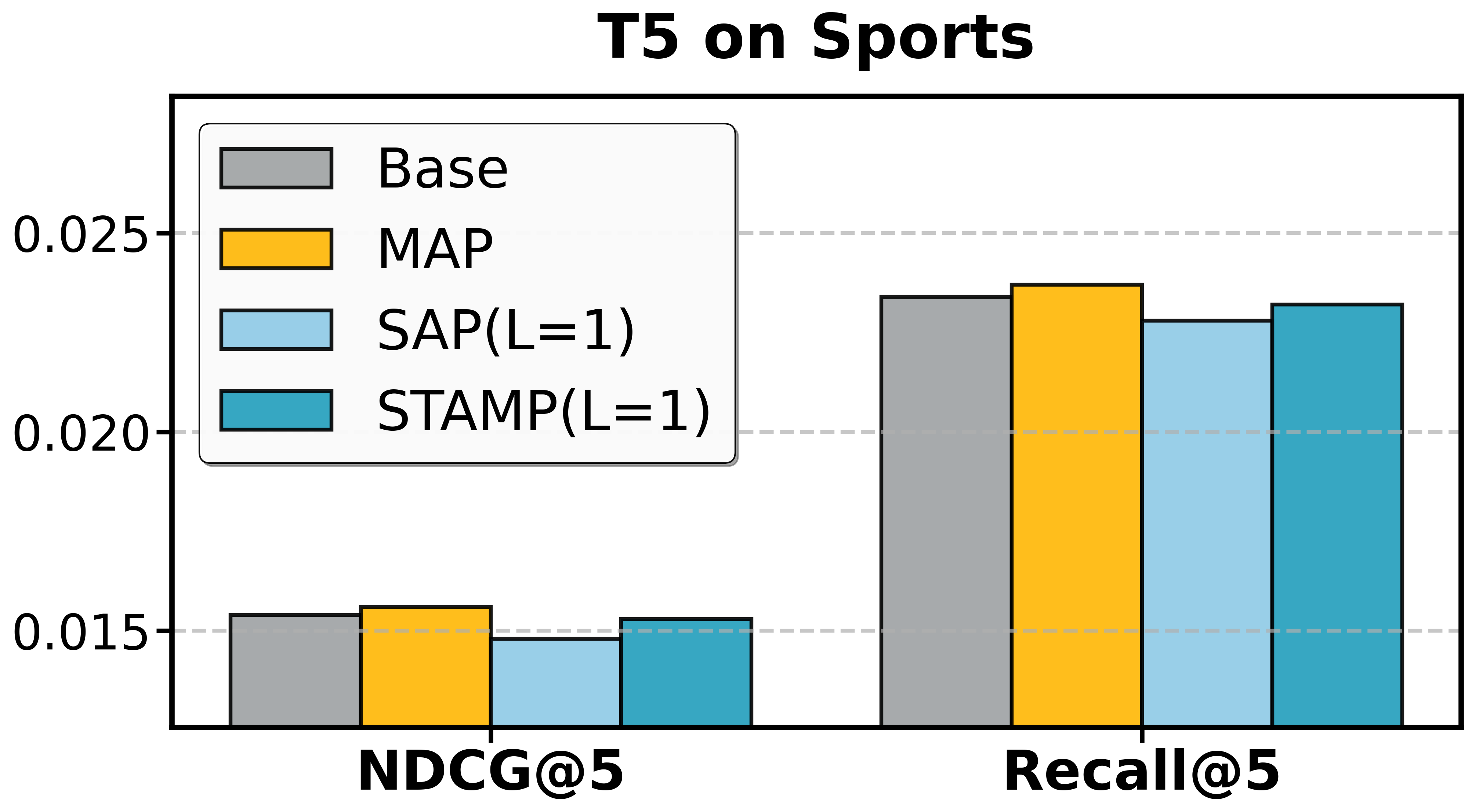
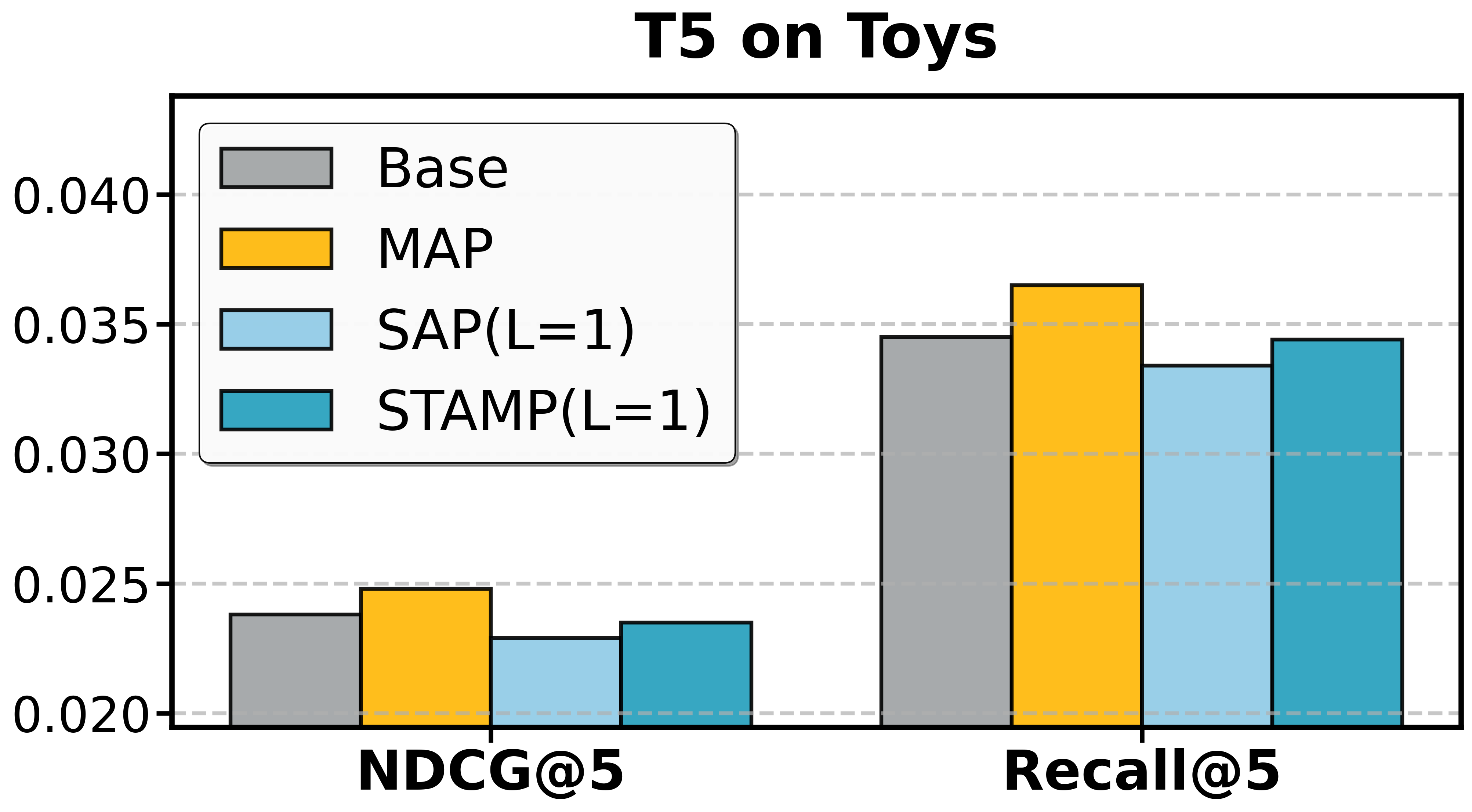
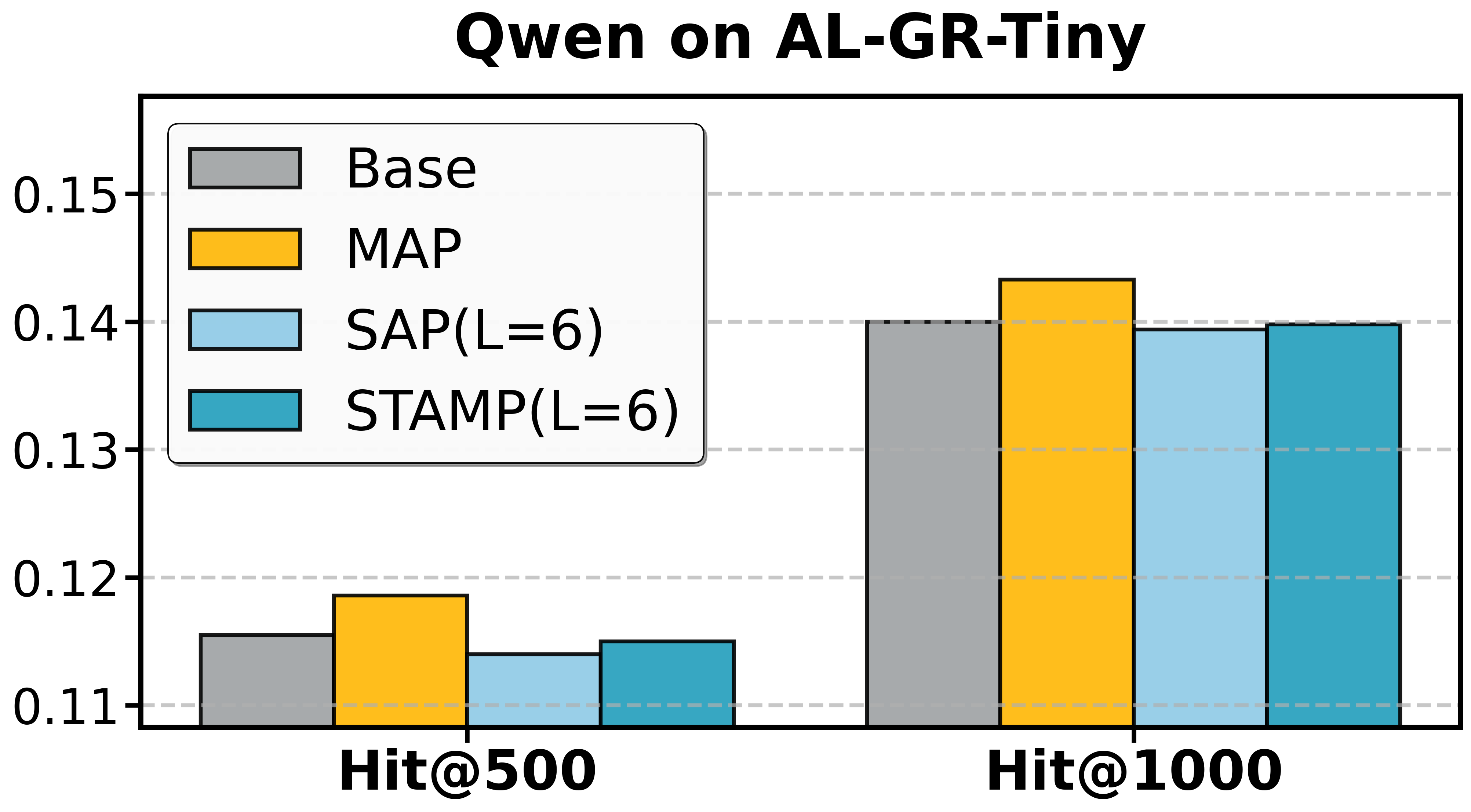
Figure 3: Ablation study of T5 on Amazon datasets and Qwen on AL-GR-Tiny confirms the independent and joint contributions of SAP and MAP.
Analysis of SAP and MAP Mechanisms
Redundancy Identification
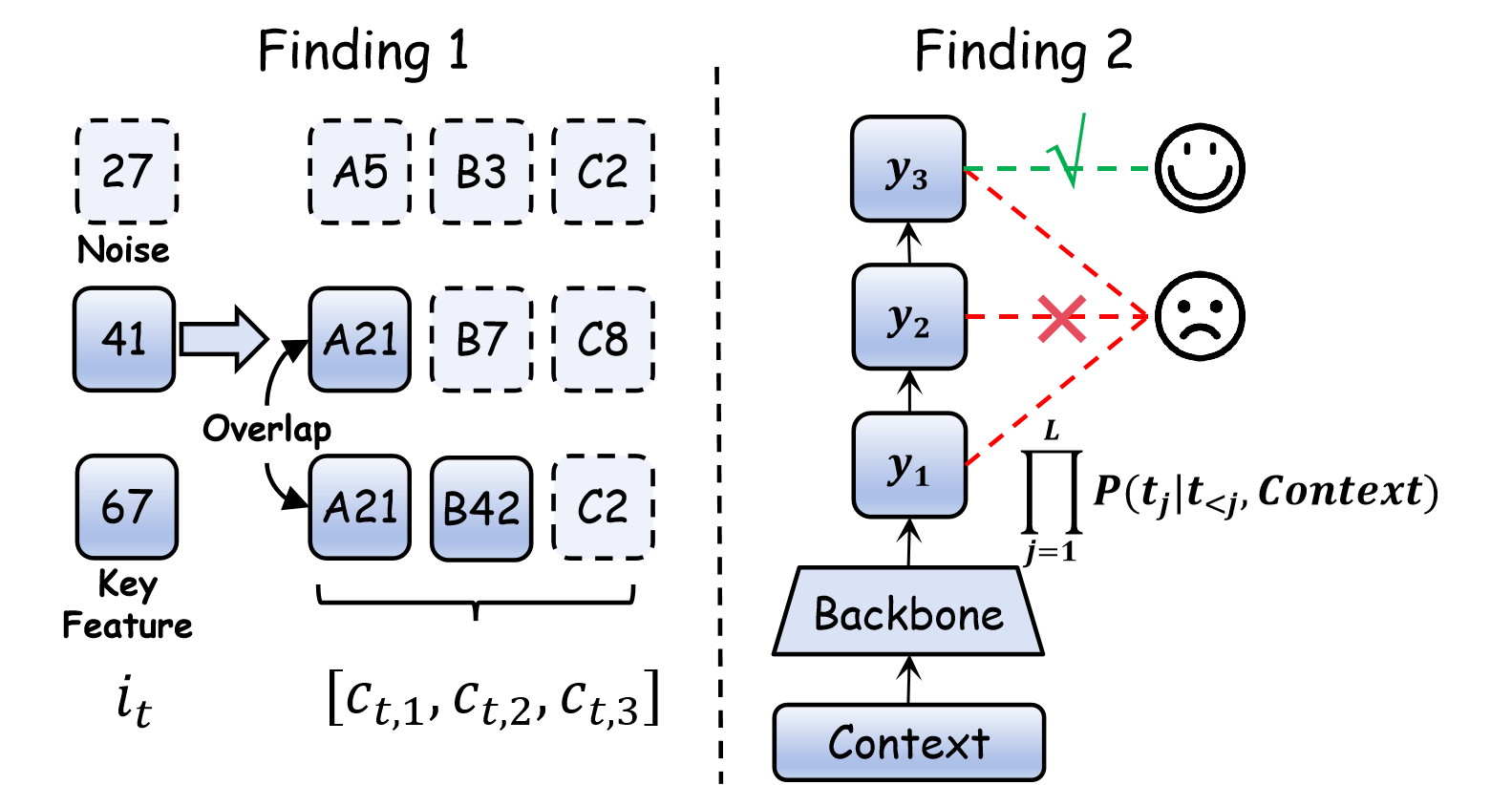
Figure 4: Redundancy is shown through both feature-level overlap and semantic sequence overlaps; joint probability constraints further exacerbate the challenge for long-sequence dependencies.
The centrality-driven approach substantially outperforms naïve pooling and scalar-magnitude pruning strategies. SAP's superior token selection is validated by direct validation set performance and test outcomes.
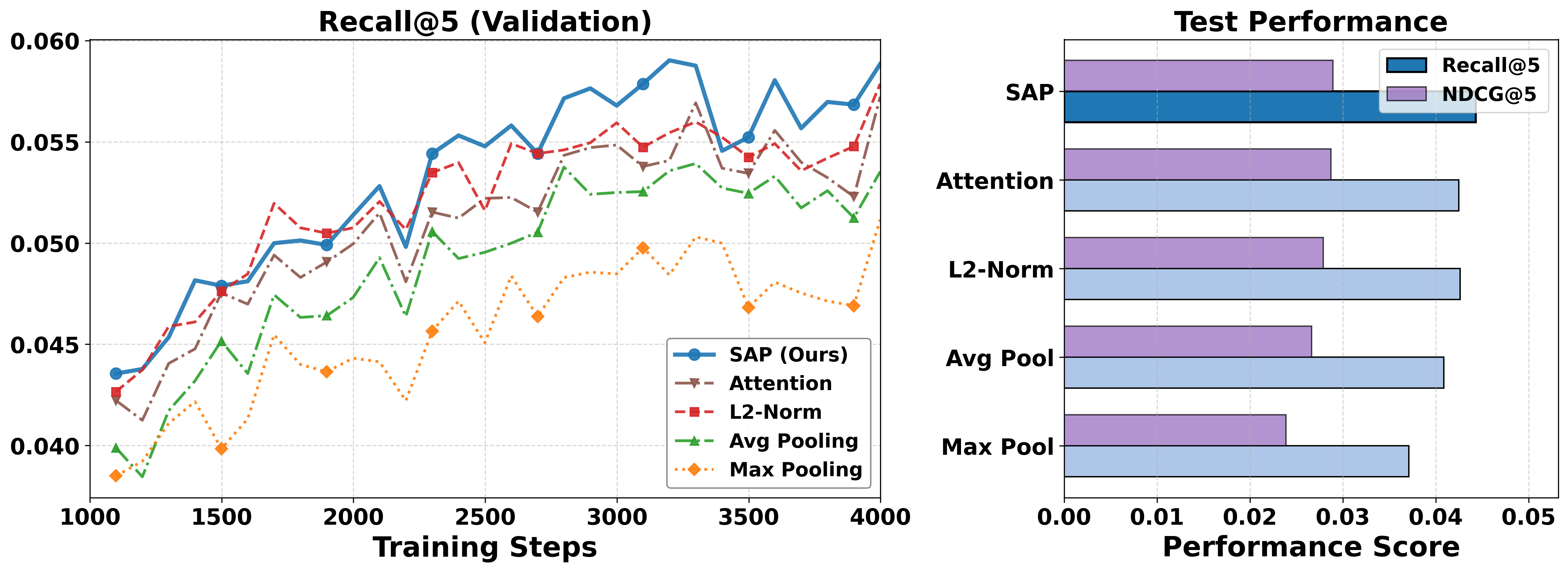
Figure 5: SAP outperforms pooling and single-criterion pruning baselines, highlighting the necessity of joint saliency-centrality consideration.
Hyperparameter Sensitivity
Aggressive retention ratios and earlier pruning layers maximize efficiency but can precipitate abrupt accuracy collapse after a threshold. Optimal settings balance SAP's layer placement and retention to maintain a sufficient information reservoir for long-range dependency modeling.
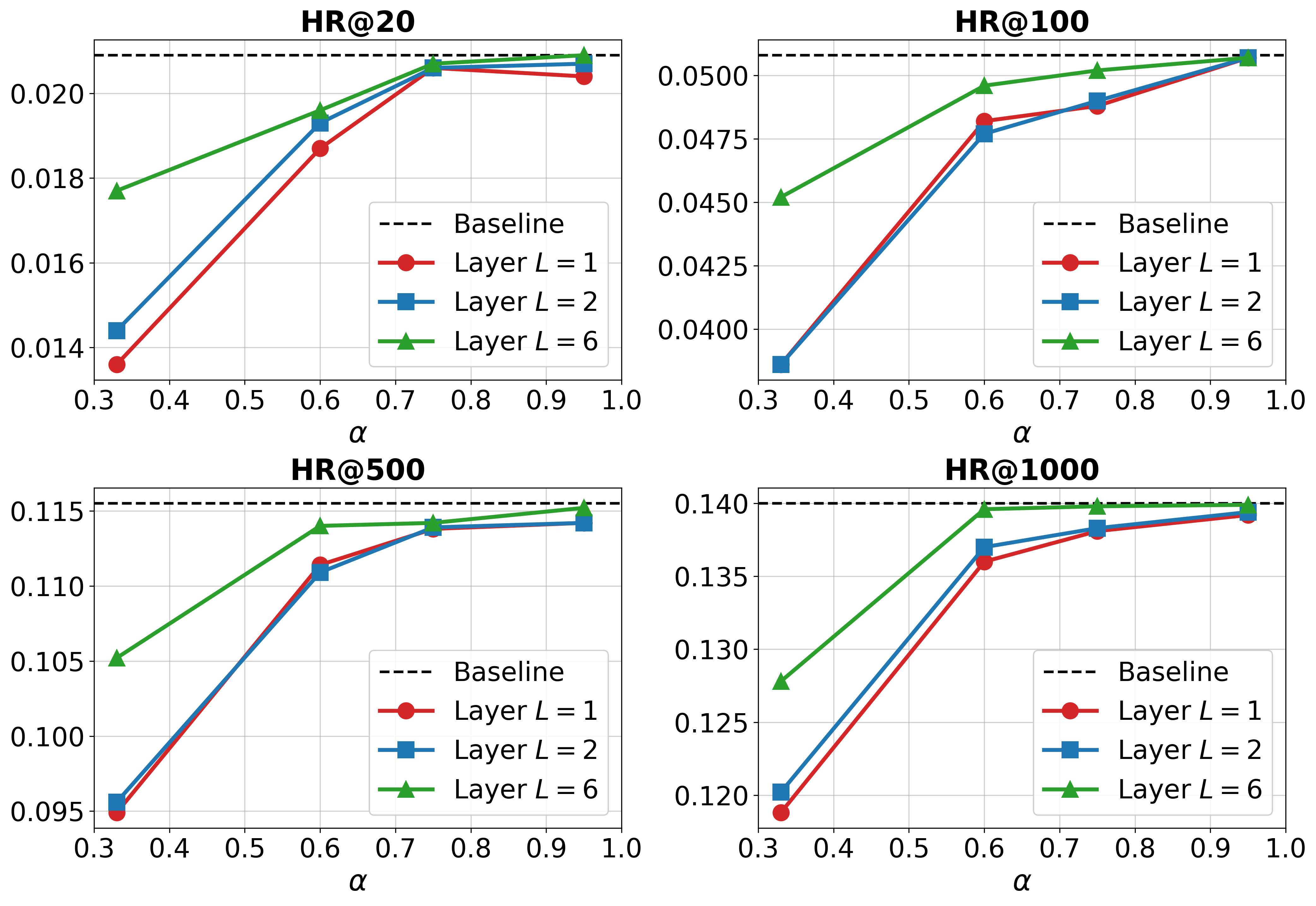
Figure 6: The performance/efficiency trade-off of SAP as a function of pruning layer and retention ratio on Qwen/AL-GR-Tiny.
Safety of Aggressive Pruning
Attention visualizations confirm that most tokens remain peripheral throughout layerwise aggregation, while only a subset accrue substantial centrality—rationalizing why aggressive lossless pruning is possible, so long as protected tokens remain and pruning is deferred post-aggregation.
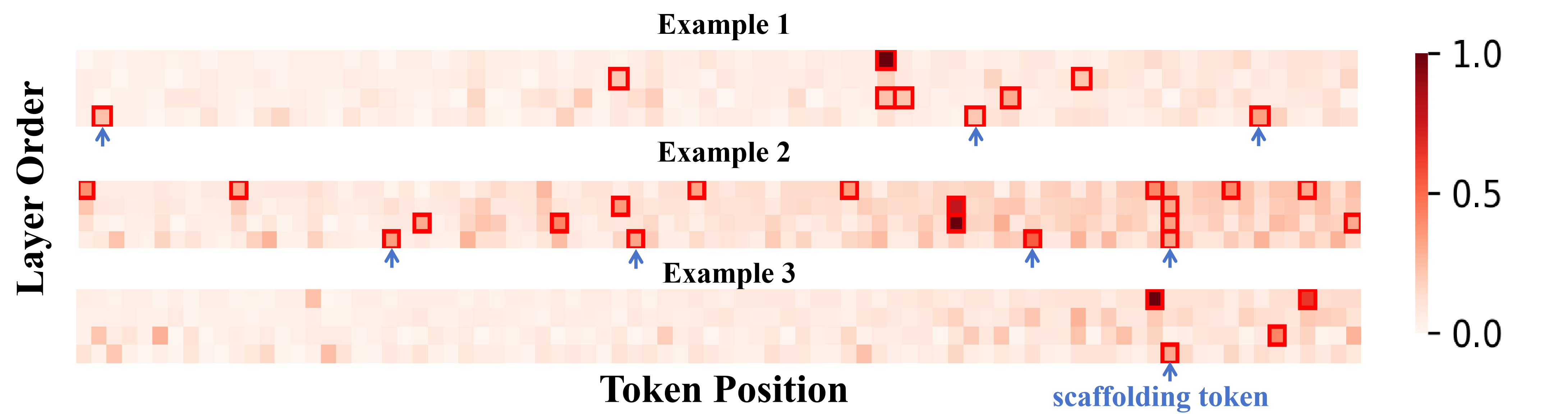
Figure 7: Attention visualizations on T5/Beauty sequences demonstrate that only a small token subset is central and robust to aggressive SAP pruning.
Theoretical and Practical Implications
STAMP fundamentally demonstrates that SID-based recommendation can be made arbitrarily more efficient by exploiting input redundancy and output signal sparsity, provided that appropriate dynamic token selection and supervision densification mechanisms are in place. For real-world deployments, this signifies a pathway to scalable, resource-efficient GR frameworks capable of frequent retraining on evolving datasets, without sacrificing representational power or inference quality.
Theoretically, STAMP presents a robust framework for rethinking optimization and regularization in structured tokenization paradigms, potentially generalizing to other dense-coded generative settings (e.g., multi-modal retrieval).
Future Directions
Future advancements may focus on:
- Jointly learning SID tokenization and SAP selection policies in a differentiable, end-to-end manner.
- Extending STAMP to support dynamic inference-time pruning for low-latency serving.
- Generalizing to other structured outputs (e.g., hierarchical labeling, graph codebooks).
Integration with reinforcement learning, better unsupervised redundancy metrics, and online adaptation remain promising.
Conclusion
STAMP delineates a precise, empirically validated framework for addressing the compounded inefficiency and instability caused by Semantic Dilution in SID-based generative recommendation. By synergizing SAP and MAP, STAMP attains a non-trivial balance between resource utilization and representational efficacy. The modular design sets a precedent for a new class of efficient, adaptive GR systems, regardless of underlying architecture or scale (2604.05329).