- The paper introduces Sparse Memory Finetuning, retrofitting Transformers with sparse memory layers to minimize catastrophic forgetting.
- It presents a three-stage pipeline—Retrofitting, Recovery, and Task-Specific Finetuning—using gradient masking and dual slot-selection (TF-IDF and KL-divergence).
- Empirical results show rapid adaptation and retention on benchmarks like TriviaQA and SimpleQA, enabling continual learning on consumer hardware.
Improving Sparse Memory Finetuning: An Expert Review
Motivation and Context
The research addresses the challenge of continual learning in LLMs, specifically the goal of updating models to acquire new knowledge without catastrophic forgetting of previous capabilities. Standard approaches—such as full finetuning and parameter-efficient finetuning (PEFT) like LoRA—operate on dense representations, inevitably leading to interference and degradation of older knowledge. Sparse Memory Finetuning (SMF) is posited as a principled solution, restricting updates to specific memory slots, thereby isolating new information and minimizing interference.
The methodology involves retrofitting existing open-weight Transformers (Qwen-2.5-0.5B) by replacing selected Feed-Forward Networks (FFN) with sparse memory layers. The memory layer architecture consists of trainable keys and values, and only those memory slots accessed during a forward pass receive gradients during training. This explicit sparsity mitigates the risks of catastrophic interference inherent in dense update regimes.
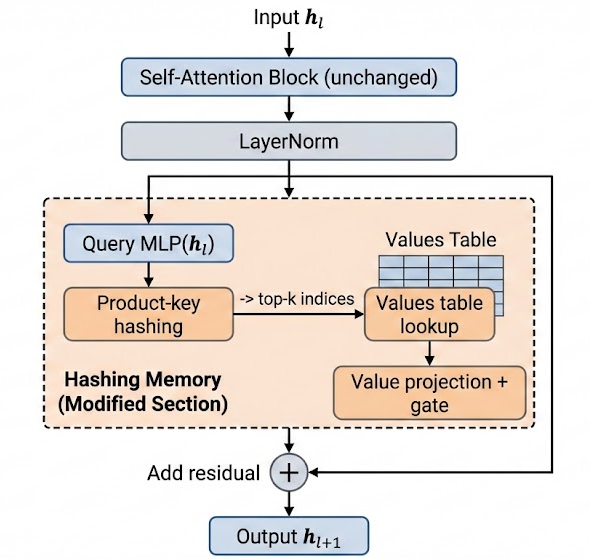
Figure 1: Retrofitted pretrained Transformer with sparse Memory Layers.
Retrofitting requires a three-stage pipeline:
- Retrofitting: FFN layers are surgically replaced by memory layers, causing an initial drop in model performance due to altered forward computation.
- Recovery (Healing): Finetuning on general instructional data realigns memory layers with the pretrained backbone, restoring baseline competence.
- Task-Specific Finetuning: Only the accessed memory slots are updated during adaptation to new tasks, enforcing sparsity.
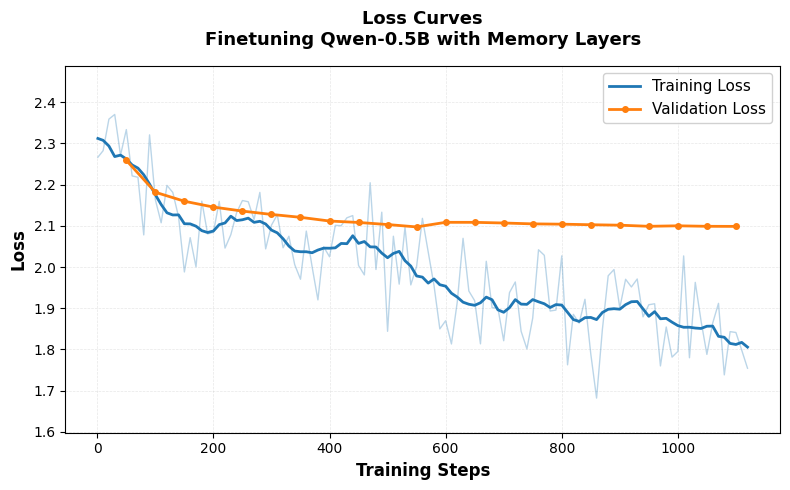
Figure 2: Recovery phase training loss on the instruction dataset (using TF-IDF).
Sparse Updates: Mechanism and Slot Selection
Sparse updates are operationalized via gradient masking—only the memory entries corresponding to retrieved slots are eligible for parameter updates. This isolation is crucial for reducing interference between sequential learning tasks.
Figure 3: Sparse update mechanism: only retrieved key/value entries receive gradients.
A critical innovation is slot selection for sparse updates. Two scoring functions are evaluated:
- TF-IDF-based selection: Prioritizes rarely accessed slots, assuming that common slots encode generic knowledge.
- KL-divergence-based selection: Uses information-theoretic surprise relative to a background distribution to select slots, identifying memory areas that are more task-relevant.
KL-divergence scoring leverages batch usage distributions versus background slot frequency, theoretically offering a principled signal for updating only relevant and "surprising" memory slots.
Empirical Evaluation: Plasticity and Stability
The empirical results span adaptation to TriviaQA and SimpleQA with assessment on held-out tasks (NaturalQuestions, GSM8K), evaluating both plasticity (learning new tasks) and stability (retaining prior capabilities).
Key findings:
- Sparse memory finetuning achieves rapid adaptation on the target task, with strong F1 scores after few hundred steps, outperforming dense finetuning which converges slowly.
- KL-divergence slot scoring introduces a task-dependent trade-off. For SimpleQA, it improves retention and stability; for TriviaQA, it exhibits slightly higher forgetting, indicating sensitivity to adaptation signal strength.
- Dense finetuning consistently increases loss on GSM8K, signifying catastrophic forgetting in reasoning tasks, while sparse updates preserve performance on held-out benchmarks.
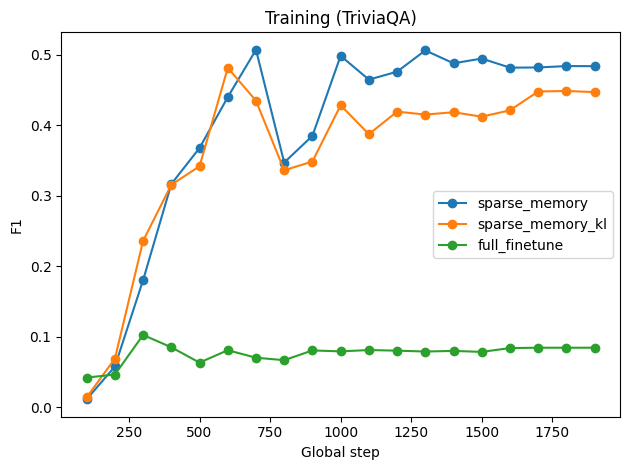
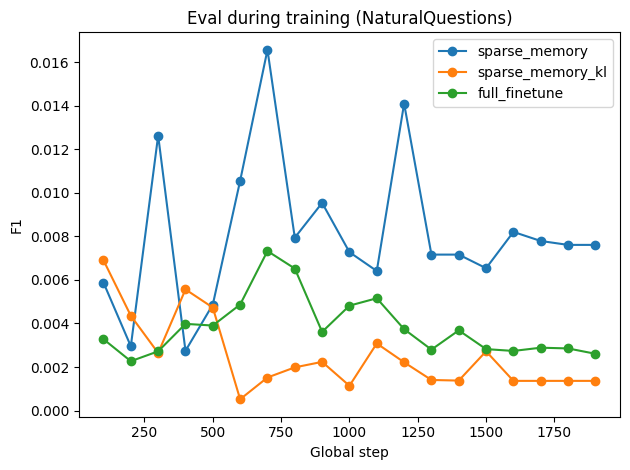
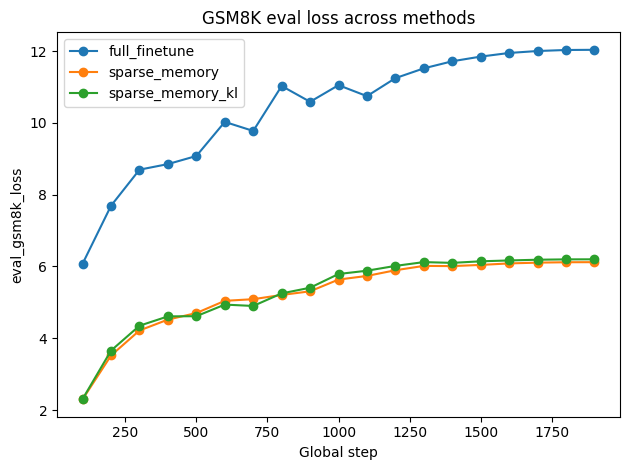
Figure 4: Finetuning performance across datasets: TriviaQA training F1, Natural Questions evaluation F1, and GSM8K evaluation loss for various update regimes.
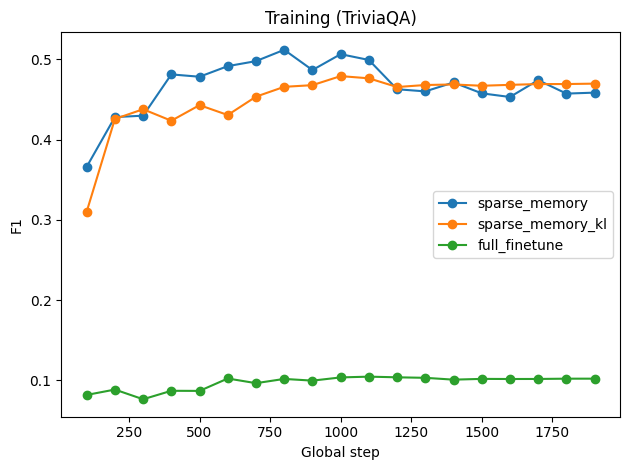
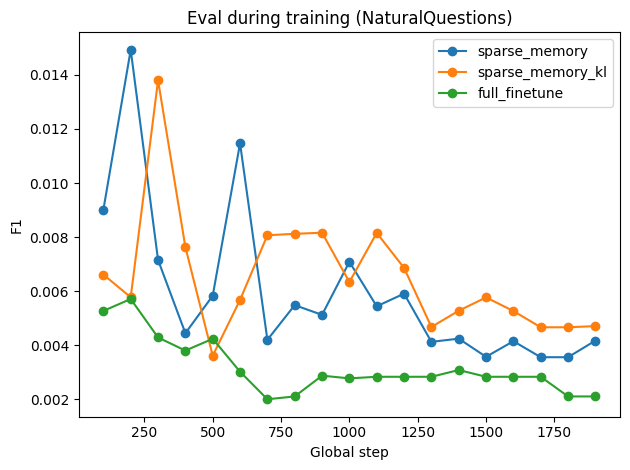
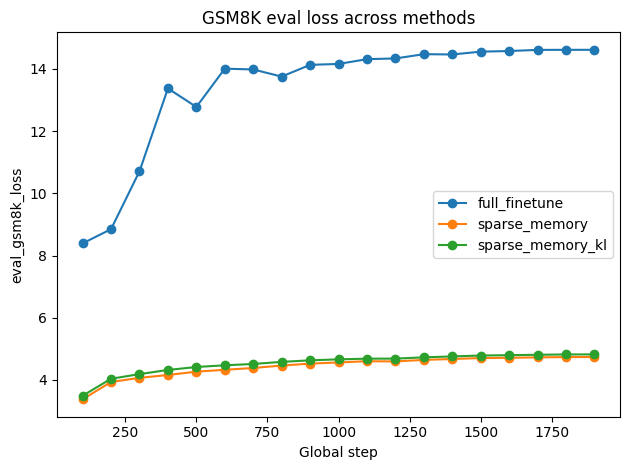
Figure 5: Finetuning performance when adapting to SimpleQA across TriviaQA, Natural Questions, and GSM8K.
Practical Implications and Theoretical Contributions
The pipeline enables continual learning on consumer hardware, bypassing the scalability issues of retrieval-augmented generation and the interference of dense PEFT approaches. By providing a reproducible method for retrofitting and updating only sparse subsets of parameters, the framework advances the practical deployment of LLMs in environments demanding continual adaptation.
Theoretical contributions include the formalization and empirical evaluation of slot selection mechanisms, especially the information-theoretic KL-divergence scoring, exposing nuanced dynamics in the stability-plasticity trade-off. The results validate the sparse update hypothesis: localized parameter adjustments minimize interference, enabling models to learn new facts while retaining reasoning and QA capabilities.
Speculation on Future Directions
Future work may expand the sparse memory paradigm by:
- Scaling to larger models and additional tasks, exploring optimal placement and sizing of memory layers.
- Refining slot selection algorithms through more sophisticated information-theoretic or reinforcement learning approaches.
- Integrating dynamic memory growth or compression to handle extended sequences of adaptation in lifelong learning settings.
- Applying the pipeline to privacy-preserving continual learning in sensitive domains, given that sparse updates circumvent raw data storage.
Conclusion
The research establishes a generalizable, principled methodology for retrofitting pretrained Transformers with sparse memory layers, enabling continual learning with minimal catastrophic forgetting. Sparse gradient updates driven by slot-selection scoring—particularly KL-divergence—allow rapid adaptation and robust retention across tasks. The findings underscore the value of explicit memory modules and selective parameter updates for practical, scalable lifelong learning in LLMs.

