Boxer: Robust Lifting of Open-World 2D Bounding Boxes to 3D
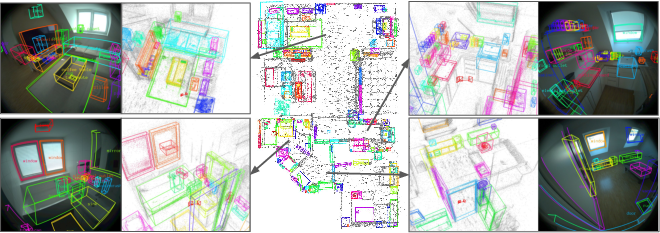
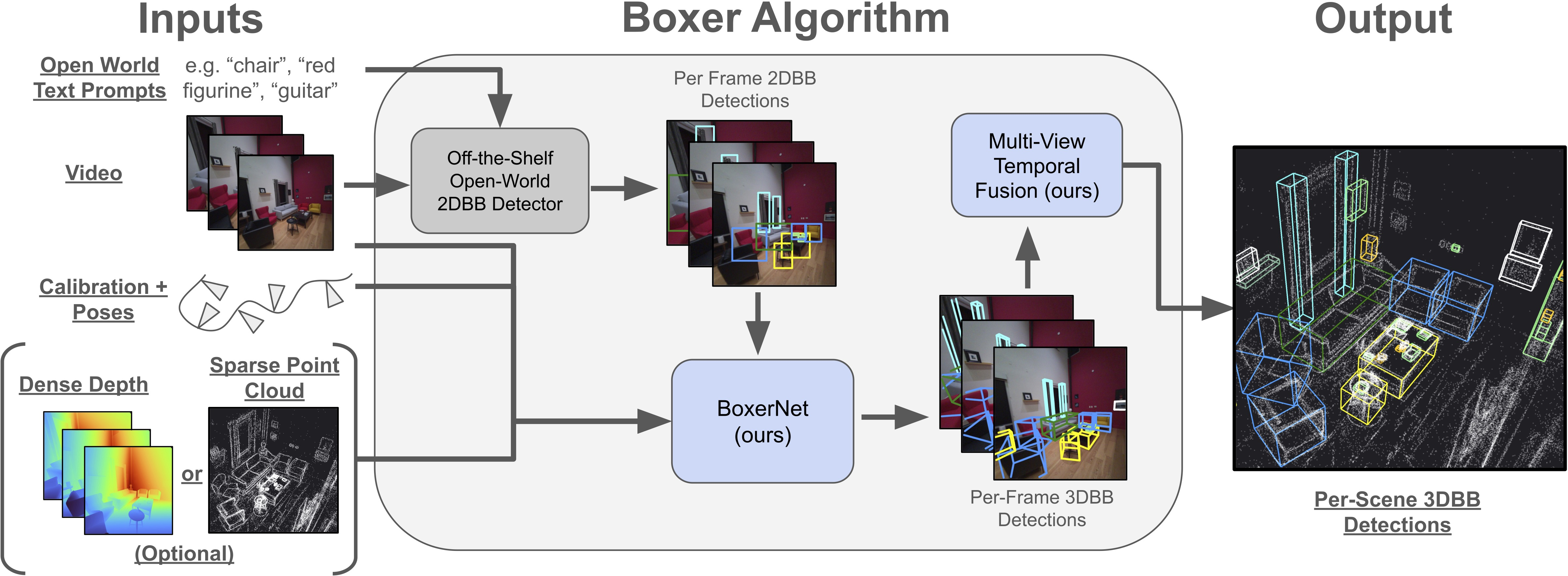
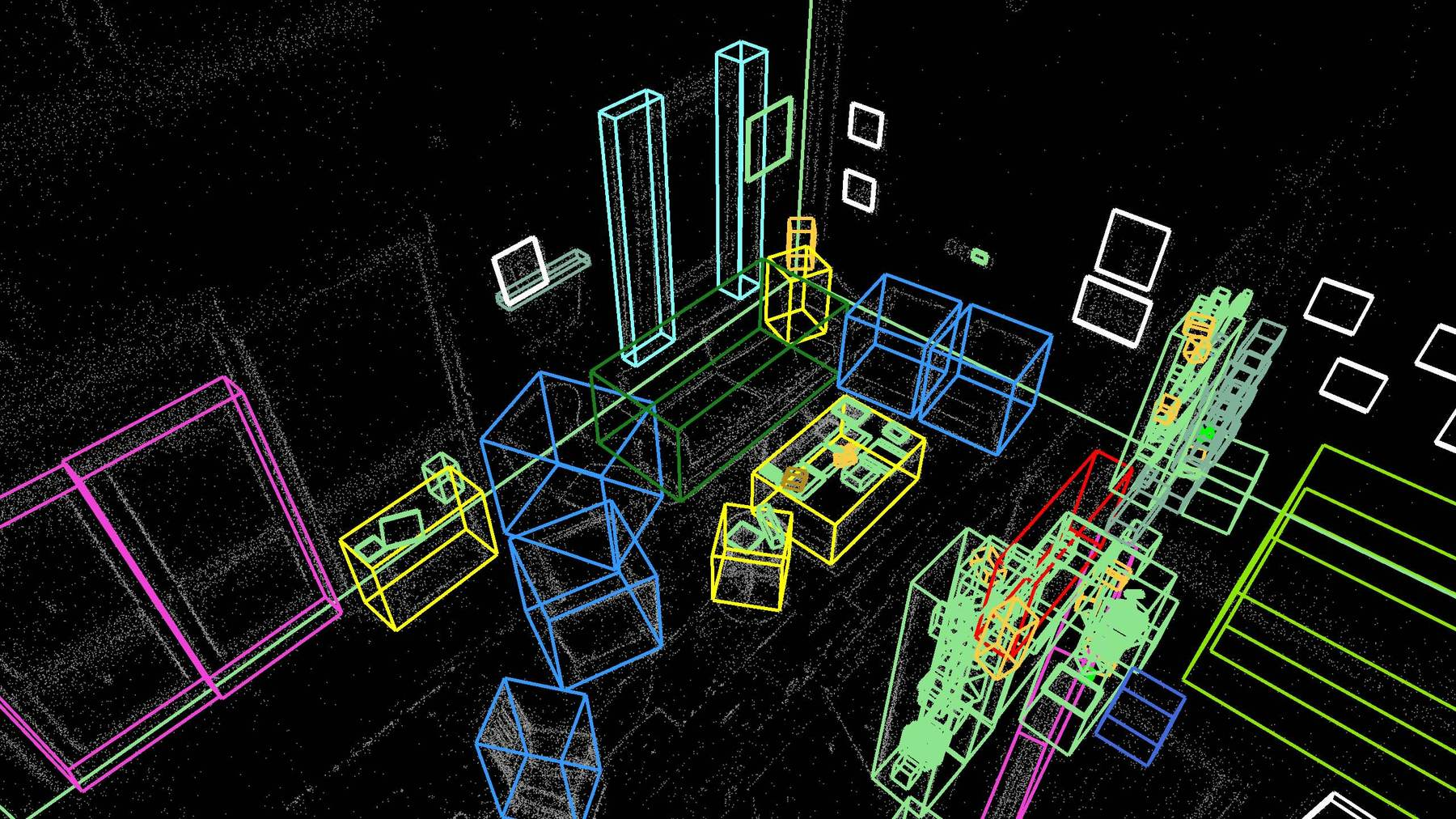
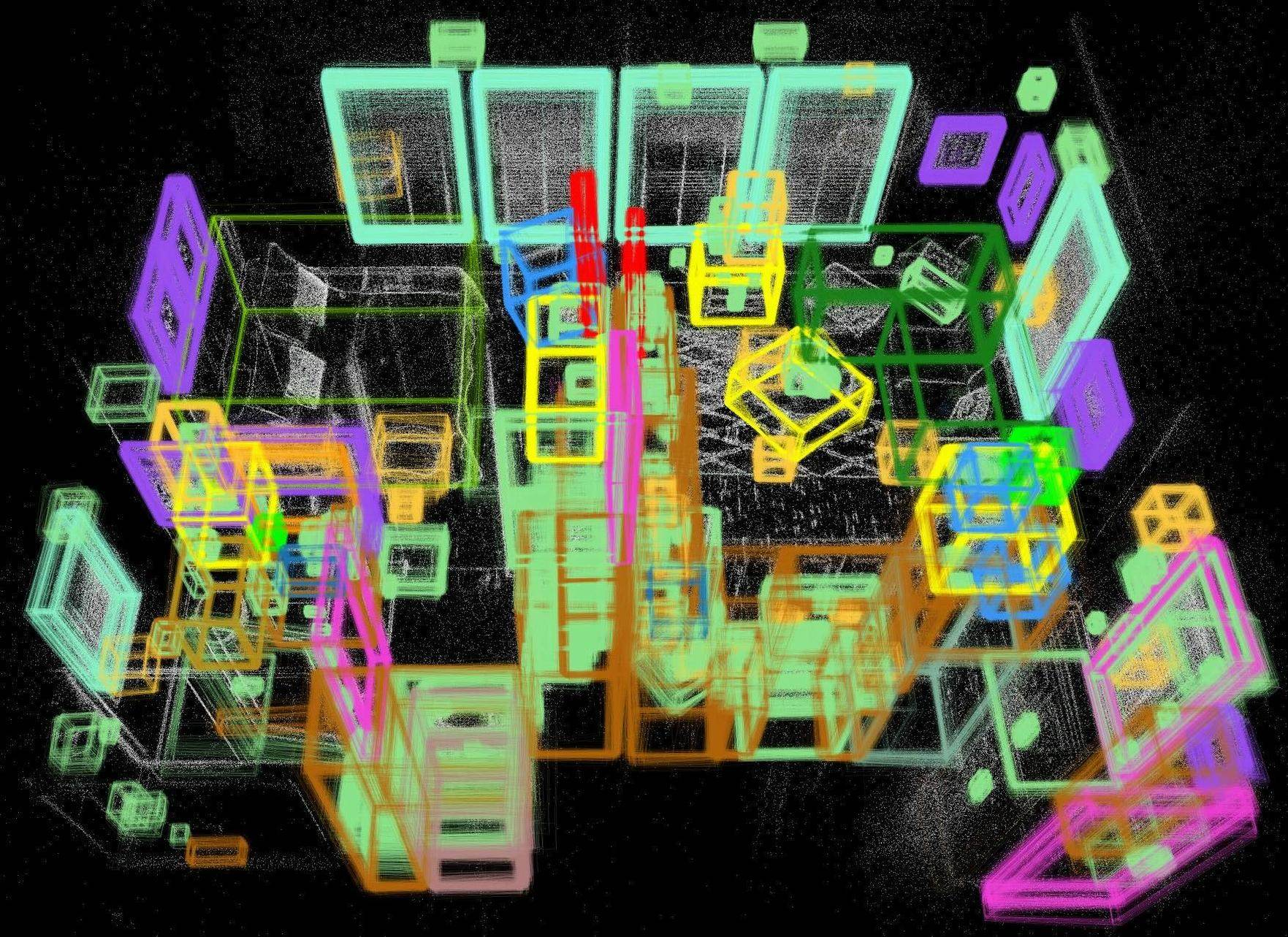
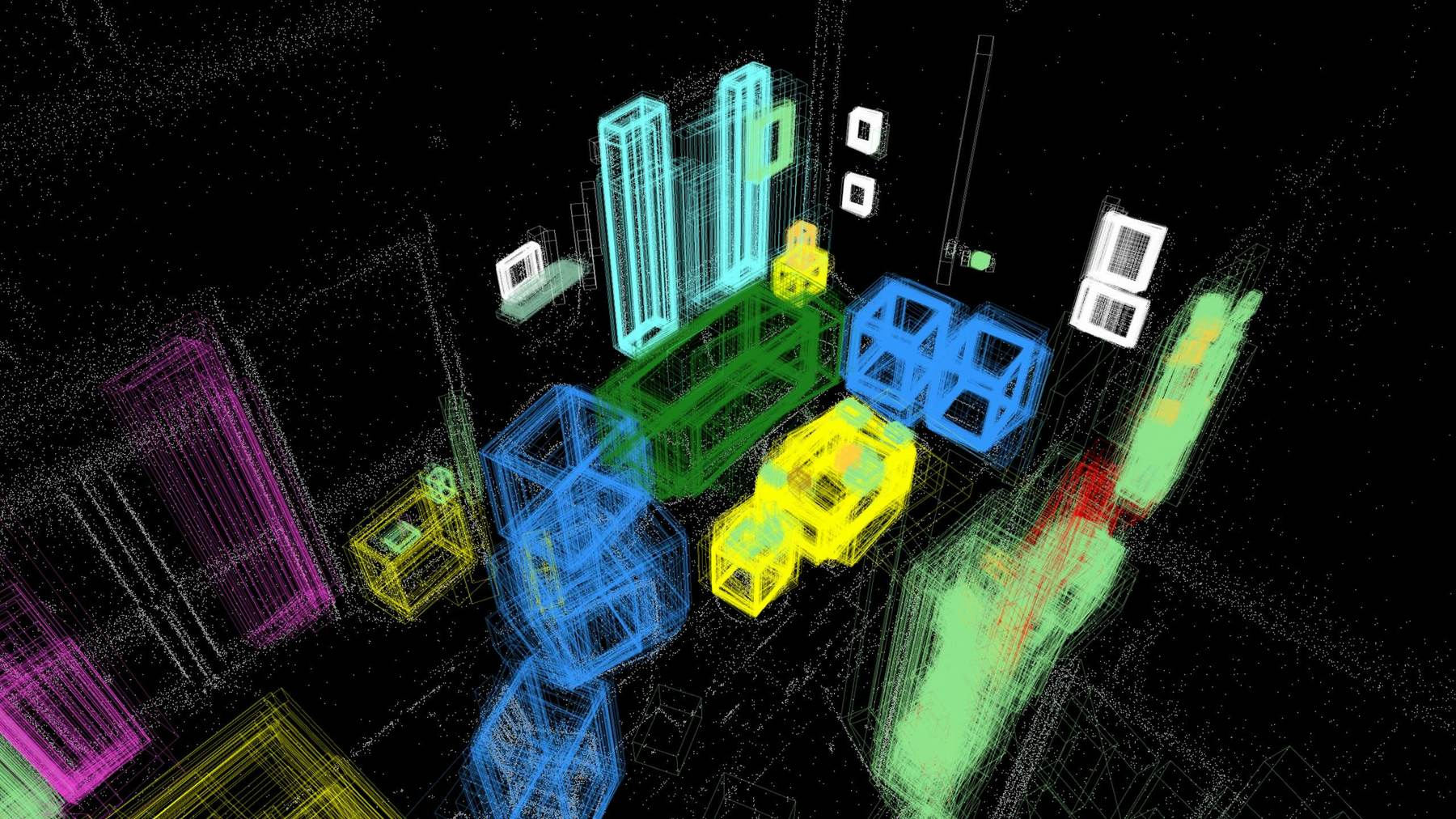
Abstract: Detecting and localizing objects in space is a fundamental computer vision problem. While much progress has been made to solve 2D object detection, 3D object localization is much less explored and far from solved, especially for open-world categories. To address this research challenge, we propose Boxer, an algorithm to estimate static 3D bounding boxes (3DBBs) from 2D open-vocabulary object detections, posed images and optional depth either represented as a sparse point cloud or dense depth. At its core is BoxerNet, a transformer-based network which lifts 2D bounding box (2DBB) proposals into 3D, followed by multi-view fusion and geometric filtering to produce globally consistent de-duplicated 3DBBs in metric world space. Boxer leverages the power of existing 2DBB detection algorithms (e.g. DETIC, OWLv2, SAM3) to localize objects in 2D. This allows the main BoxerNet model to focus on lifting to 3D rather than detecting, ultimately reducing the demand for costly annotated 3DBB training data. Extending the CuTR formulation, we incorporate an aleatoric uncertainty for robust regression, a median depth patch encoding to support sparse depth inputs, and large-scale training with over 1.2 million unique 3DBBs. BoxerNet outperforms state-of-the-art baselines in open-world 3DBB lifting, including CuTR in egocentric settings without dense depth (0.532 vs. 0.010 mAP) and on CA-1M with dense depth available (0.412 vs. 0.250 mAP).











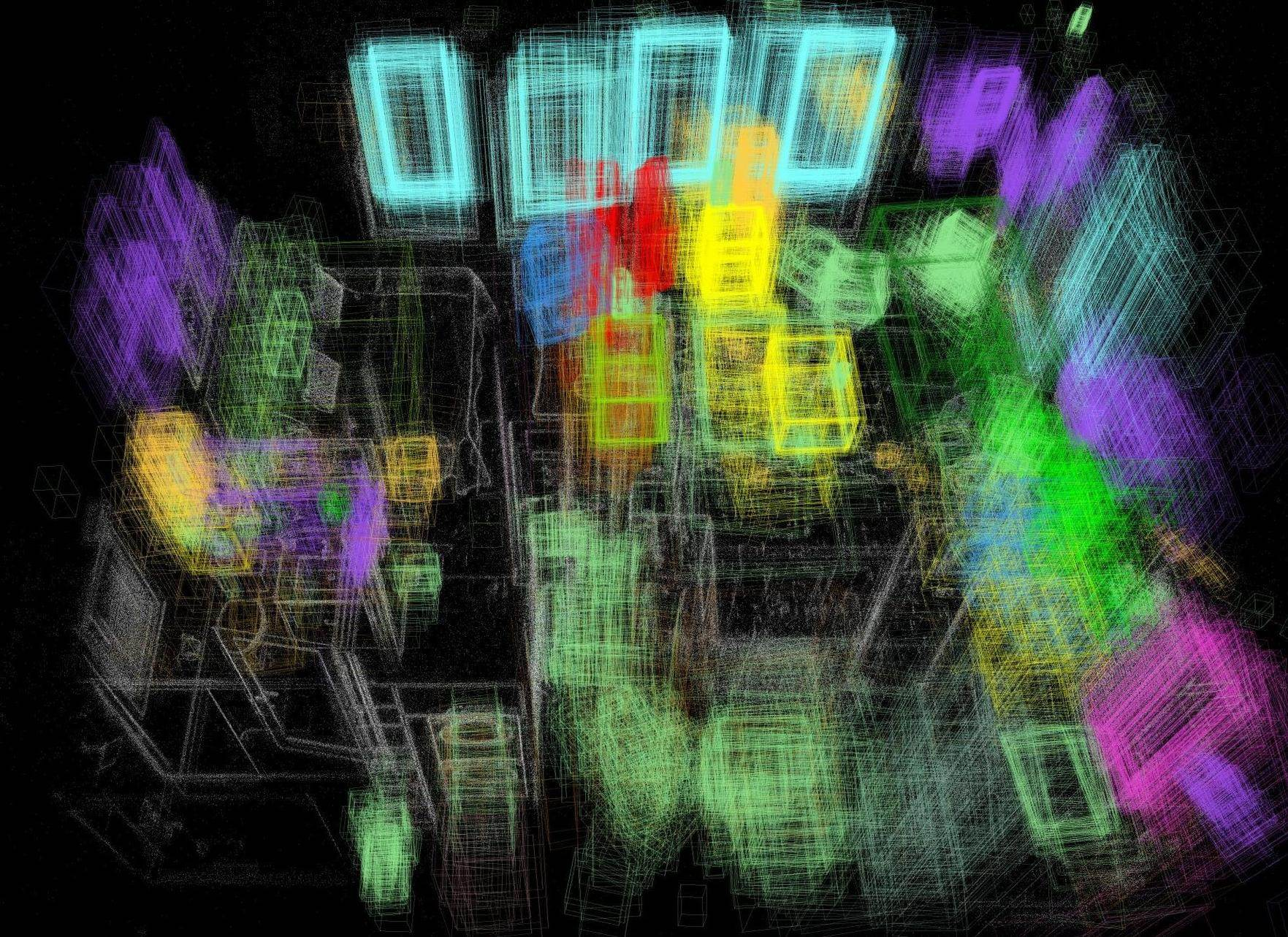




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
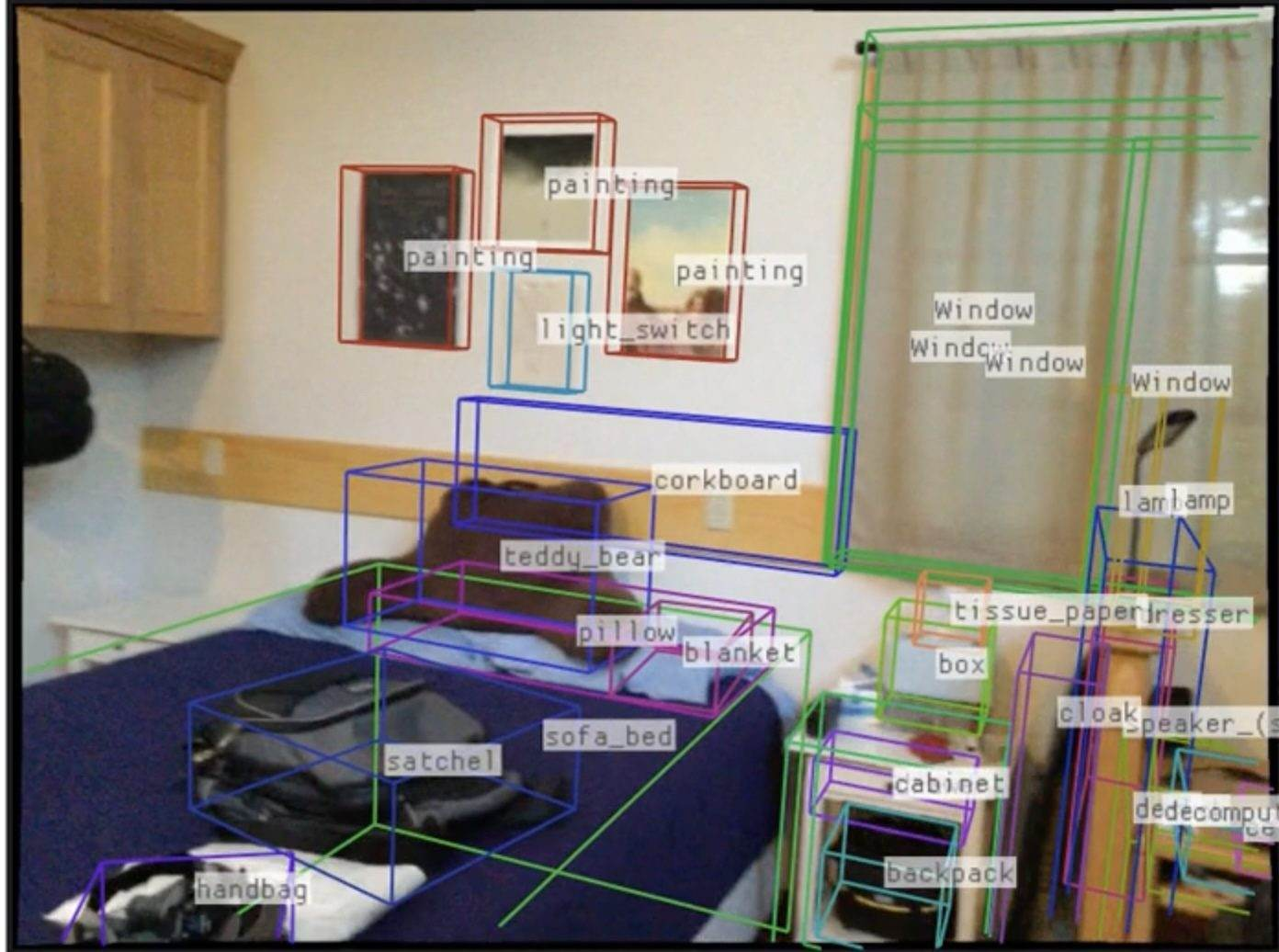
This paper introduces Boxer, a computer program that takes regular videos and turns the rectangles around objects you see in 2D pictures into accurate 3D boxes in the real world. In simple terms, it helps computers understand not just where things are in a photo, but where they are in space—how far away they are, how big they are, and which way they’re facing.
What questions were the researchers trying to answer?
The team focused on three main questions:
- How can we take the huge progress in 2D object detection (finding things in photos) and use it to find those same objects in 3D space?
- Can we make this work for lots of different kinds of objects (not just a small, fixed list) and across different cameras and devices?
- Can we do it without needing tons of expensive 3D labels by reusing existing 2D detectors and using depth information when available?
How did they do it?
They split the problem into simple steps and used a mix of smart learning and geometry.
Step 1: Find objects in 2D images
- They start with off‑the‑shelf 2D object detectors. Think of these as tools that draw rectangles around things in a picture when you ask for “mug,” “remote,” or “hairdryer.”
- These detectors already know thousands of object types because they were trained on massive internet image datasets. This gives Boxer “open‑world” coverage—many kinds of objects, not just a few.
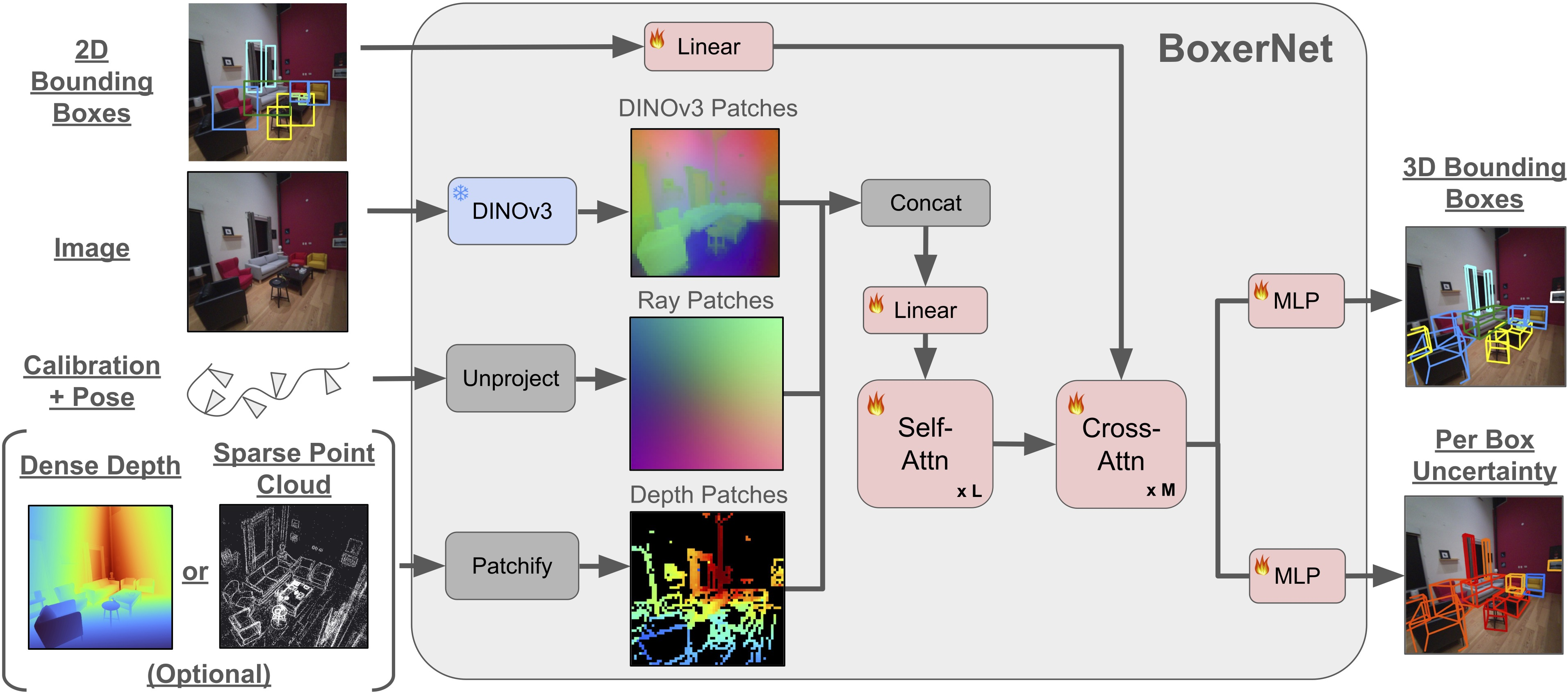
Step 2: “Lift” 2D boxes into 3D boxes (BoxerNet)
- BoxerNet is the brain of the system. It takes:
- the image,
- the 2D box around the object,
- the camera’s position and direction (called “posed” images),
- and optional depth info (from a depth sensor or a sparse point cloud from SLAM).
- It then predicts a 3D box: where the object is in space, how big it is, and how it’s rotated.
- Analogy: If a 2D box is like drawing a rectangle around a mug in a photo, a 3D box is like placing a shoebox around that mug in the real world—at the right place, size, and angle.
- BoxerNet uses a “transformer” (a modern neural network that’s very good at paying attention to the most useful parts of data). It mixes:
- visual features (what the object looks like),
- ray features (which direction each pixel points in 3D from the camera),
- and depth hints (how far things are).
- It also predicts how uncertain it is about each 3D guess. That “uncertainty” helps it be cautious when the view is confusing or the depth is missing.
Step 3: Combine results from multiple frames
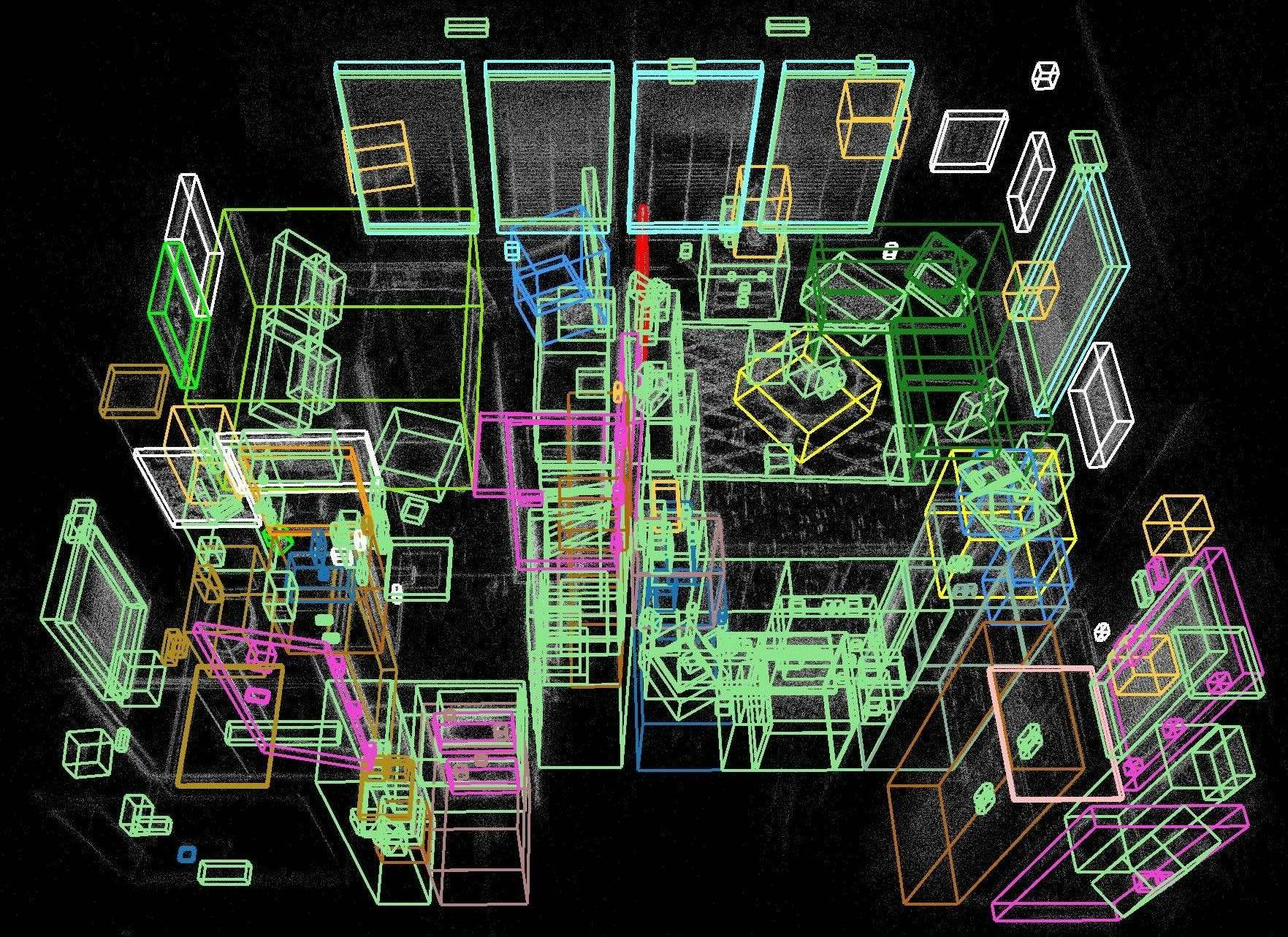
- Videos see the same object from many angles. Boxer uses a fusion step to merge multiple 3D guesses of the same thing into one clean, stable 3D box.
- It groups boxes that overlap in space and that refer to similar object names, then averages them in a smart way and removes duplicates.
- Result: a consistent, global map of objects in the scene.
A note on inputs
- “Posed images” means the system knows the camera’s position and orientation for each frame (common with AR/VR devices or phones with AR tracking).
- Depth can be:
- dense (a depth image, like from an RGB‑D camera),
- or sparse (a cloud of a few 3D points from SLAM). Boxer works with either, or even without depth—though depth helps a lot.
What did they find, and why is it important?
Here are the standout results and what they mean:
- Boxer beats previous methods at turning 2D detections into 3D boxes across several datasets and camera types.
- On egocentric video without dense depth (think smart glasses), Boxer achieves much higher accuracy than a strong baseline (e.g., 0.532 vs. 0.010 mAP in one evaluation with ground‑truth 2D boxes).
- On a large iPad dataset with depth available, Boxer also outperforms the baseline (e.g., 0.412 vs. 0.250 mAP).
- It works in an “open‑world” setting. That means it’s not limited to a short list like “chair, table, lamp”—it can handle many object types by using powerful 2D detectors trained on web‑scale data.
- It’s flexible about sensors and cameras. It can use depth when available (for better accuracy) or still function without it, and it supports different camera models (like normal, fisheye, or AR headsets).
- It needs far fewer special 3D labels because it reuses strong 2D detectors and focuses learning on the “lifting to 3D” step. The team still trained on a large mix of real-world data—over 1.2 million unique 3D boxes across multiple devices—but the approach is more scalable than trying to label everything in 3D from scratch.
- It’s efficient. The core lifting step runs in about 20 milliseconds per image on a modern GPU.
Why it matters:
- Understanding where objects are in 3D is crucial for robots (to move and grasp safely), AR apps (to place virtual objects correctly), and digital twins (to build accurate 3D maps of real places).
- Boxer offers a practical path to open‑world 3D understanding by combining the best of today’s 2D recognition with solid 3D geometry.
What could this lead to?
- Better home robots and assistive devices that can find and interact with everyday objects.
- Smarter AR experiences that align virtual content with real objects in your room.
- Easier creation of 3D maps for planning, inventory, and indoor navigation.
- A flexible foundation that can grow as 2D detectors get better, without retraining everything from scratch.
In short, Boxer shows a scalable way to move from “seeing” in 2D to “understanding” in 3D for many kinds of objects in the real world—bringing us closer to robots and AR systems that can truly understand and interact with our spaces.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper and could guide future research:
- Dynamic and articulated objects: The pipeline assumes static scenes; extending lifting and fusion to handle moving, in-hand, or articulated objects (with appearance and geometry changes over time) is unaddressed.
- Non-cuboidal and thin/deformable objects: 3DBBs poorly represent cables, fabrics, plant vines, or very thin/elongated items; alternatives (e.g., oriented 3D ellipsoids, meshes, implicit shapes) are not explored.
- Orientation representation: Only gravity-aligned yaw is predicted; full 9-DoF orientations (including roll/pitch) for tilted or wall-mounted objects remain unmodeled and unevaluated.
- Sensitivity to pose/intrinsics errors: Robustness to noisy camera intrinsics, extrinsics, IMU gravity estimates, or SLAM drift is not quantified; a systematic stress test with controlled perturbations is missing.
- Metric scale without depth/stereo: Performance when only monocular images are available (with scale ambiguity) is not evaluated; strategies to infer/regularize absolute scale remain open.
- Depth encoding design: The median-per-patch depth channel is a simple choice; the impact of depth sparsity, noise, outliers, patch size, and alternative encodings (e.g., multi-quantile histograms, learned depth uncertainty, point-feature transformers) is not studied.
- Depth quality vs performance: There is no characterization of how lifting accuracy varies with depth density/quality (e.g., stereo vs RGB-D vs sparse SLAM points) or minimum sparse coverage needed for reliable lifting.
- Learned vs heuristic fusion: Multi-view fusion uses hand-crafted IoU thresholds, text-embedding similarity, connected components, and NMS; learned, uncertainty-aware, or probabilistic fusion and sensitivity to hyperparameters are not explored.
- Scalability of fusion/tracking: Offline O(N2) fusion is described but not profiled on hour-long sequences; the online tracker is not quantitatively evaluated for accuracy/latency/memory on streaming, long-duration deployments.
- Confidence calibration: The final ranking averages 2D and 3D confidences; calibration quality (e.g., ECE, NLL), detector-specific calibration, and learned score fusion (or Bayesian decision rules) are not investigated.
- Use of uncertainty: Aleatoric uncertainty is only used for ranking; leveraging uncertainty to drive fusion weights, active view selection, or human-in-the-loop verification is unaddressed.
- Prompting strategy: The method relies on large prompt lists (e.g., LVIS+17); automatic prompt discovery, synonym de-duplication, hierarchical prompting, and prompt selection under compute budgets remain open.
- Semantic consistency in fusion: Text-embedding thresholds and handling of synonyms/polysemy are heuristic; failure modes (merging different but related categories or splitting same-category synonyms) are not analyzed.
- Dependence on 2D detectors: The system inherits biases and errors from OWLv2/DETIC; joint training/fine-tuning strategies, detector ensembling, or segmentation-conditioned lifting (using masks from e.g., SAM3) are not evaluated.
- Class-agnostic evaluation only: The paper reports class-agnostic mAP; semantic correctness (category-level precision/recall), category confusion, and long-tail category performance are not analyzed.
- Limited domains: Experiments focus on indoor data; generalization to outdoor, warehouse/industrial, and highly cluttered scenes, as well as scale to large spaces, is untested.
- Camera model coverage: Although the encoder is intended to be camera-agnostic, systematic evaluation across broad camera models (e.g., fisheye, equirectangular/panoramic, rolling-shutter effects) is missing.
- Pose source variability: The impact of different pose sources (stereo SLAM, monocular SLAM, VIO, offline SfM) and their failure modes on lifting/fusion accuracy has not been quantified.
- Floor/plane priors and physical reasoning: The model/fusion does not exploit scene-level constraints (e.g., objects supported by planes, gravity-aligned layouts); integrating geometric priors could improve metric accuracy.
- Size priors and metric accuracy: Category-level size priors are not used; dimension and distance errors (beyond IoU) and metric-scale bias analyses are absent.
- Multi-view end-to-end learning: Lifting is per-frame and fusion is post-hoc; end-to-end multi-view transformers that jointly reason across frames are not explored.
- Thin-object evaluation protocol: CA-1M modifies thin-object dimensions (min 5 cm) for evaluation; this introduces bias and suggests a need for standardized metrics/annotation protocols for thin structures.
- Visibility computation: Per-view visibility heuristics (≥2 depth points inside, 80% edge visibility) are unvalidated; more principled, differentiable, or learned occlusion reasoning is not considered.
- Training data reproducibility: A substantial portion of training data is internal; performance drops without it, raising reproducibility concerns and suggesting a need for public-scale datasets or domain adaptation methods to bridge gaps.
- Backbone usage: It is unclear whether DINOv3 features are frozen or fine-tuned; the effect of fine-tuning vs freezing and backbone choice/scale on lifting quality is unstudied.
- Model size inconsistency: The paper reports about 25M trainable parameters for lifting in the main text and ~71M (excluding DINOv3) in the supplement; clarifying what is trainable and its impact on speed/accuracy is needed.
- Compute and energy on-device: End-to-end runtime, memory, and energy profiles (2D detection + lifting + fusion) on edge devices (e.g., AR headsets, mobile GPUs) are not provided; scheduling strategies under real-time constraints remain open.
- Comparative coverage of baselines: Some relevant open-world 3D baselines (e.g., DetAny3D, LocateAnything3D under comparable inputs) are not exhaustively compared; unified protocols across monocular/sparse/dense depth settings would improve clarity.
- Failure-mode taxonomy: A detailed error analysis (e.g., by occlusion level, object size/distance, texture, reflectivity/transparency, clutter) is missing; such analysis could prioritize targeted model improvements.
- Multilingual grounding: Prompting and semantic fusion are tested in English only; multilingual prompts, cross-lingual embeddings, and cultural object naming variations remain unexplored.
- Robustness to reflective/transparent materials: Depth sensors often fail on mirrors/glass; behavior and mitigations (e.g., learned depth-inpainting uncertainty) are not characterized.
- Handling part–whole relationships: Fusion can conflate parts with wholes or fail to merge object subcomponents; part-aware reasoning and hierarchical associations are not addressed.
- Synonym/duplicate prompt explosion: Strategies to prevent duplicate detections across near-synonymous prompts and to enforce semantic hierarchies are not proposed.
- Augmentation ablations: While four augmentation types are used, their individual contributions and interactions are not ablated; guidelines for robust augmentation recipes are lacking.
Practical Applications
Overview
This paper introduces Boxer, a practical pipeline that lifts open-vocabulary 2D detections into metric 3D bounding boxes using posed images and optional depth (dense depth or sparse SLAM points). A transformer-based lifter (BoxerNet) handles diverse cameras, incorporates aleatoric uncertainty for robust scoring, and supports multi-view fusion into global, de-duplicated 3D object maps. Code and models are released, and inference runs in real time on a desktop GPU.
Below are concrete, real-world applications derived from the paper’s findings, organized by deployment horizon. Each item includes likely sectors, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now with available tools, given posed/calibrated image streams and (ideally) some depth or SLAM.
- AR object anchoring, labeling, and occlusion in indoor spaces
- Sectors: healthcare, education, retail, facilities, real estate, media/entertainment
- Tools/Workflows: integrate Boxer into AR runtimes (Unity/Unreal plugins) to overlay persistent 3D object boxes; export to USDZ/GLB with 3DBBs for digital twins; use OWLv2/DETIC for prompting common items (e.g., “extinguisher,” “defibrillator,” “projector”)
- Assumptions/Dependencies: calibrated/posed camera (VIO/SLAM or headset SDK), gravity estimate, relatively static scenes; open-vocab 2D detector quality and prompt selection drive coverage
- Object-aware navigation and obstacle mapping for service robots
- Sectors: robotics (cleaning, delivery, home assistance)
- Tools/Workflows: ROS2 node subscribing to /image, /camera_info, /pose (+/depth) and publishing /boxes_3d; fuse Boxer outputs into occupancy/object-layered maps for navigation and semantic planning
- Assumptions/Dependencies: reliable SLAM and camera calibration; better performance with depth; static-object assumption holds for many indoor obstacles
- Inventory of assets and equipment in facilities
- Sectors: facilities management, manufacturing, healthcare, hospitality
- Tools/Workflows: “walkthrough-to-inventory” pipeline (video capture → SLAM → OWLv2 prompts → Boxer lifting → multi-view fusion → asset list with 3D positions and sizes); link 3DBBs to CMMS/asset databases
- Assumptions/Dependencies: indoor asset categories covered by 2D detector; consistent pose estimates; static assets
- Retail shelf analytics and planogram checks
- Sectors: retail
- Tools/Workflows: store cameras or staff scans; detect product types or fixtures via open-vocab prompts; lift to 3D to check shelf occupancy, facings, and compliance at aisle/fixture level
- Assumptions/Dependencies: category prompts tuned to product/fixture taxonomies; clutter and occlusions may require multi-view fusion; better with dense depth (RGB-D)
- Rapid, lightweight room/object digital twins
- Sectors: real estate, AEC (architecture/engineering/construction), interior design
- Tools/Workflows: video-based capture to generate object-level 3DBBs (furniture, appliances) for quick as-built representations; export to CAD/BIM as proxy boxes for early planning
- Assumptions/Dependencies: limited for large structural elements (walls/floors) and thin/non-cuboidal items; camera pose quality dictates metric accuracy
- VFX/virtual production set capture
- Sectors: media/entertainment
- Tools/Workflows: on-set scans for prop localization and collision proxies; real-time 3DBBs used for previsualization and blocking
- Assumptions/Dependencies: sufficient lighting and calibration; static props
- Home inventory and “find my object” assistants
- Sectors: consumer software, smart home, accessibility
- Tools/Workflows: home walkthrough generates a persistent 3D map of common items (remote, tools); mobile/AR app queries the spatial index via text prompts
- Assumptions/Dependencies: initial mapping requires device with SLAM (ARKit/ARCore/AR glasses); limited support for moving/temporarily displaced objects
- Claims documentation and risk surveys
- Sectors: insurance, property management
- Tools/Workflows: adjuster or policyholder captures a video; auto-generate a 3D inventory (types, placement, approximate dimensions) to support baseline valuation or claims evidence
- Assumptions/Dependencies: careful prompt curation to avoid mislabeling; privacy and compliance considerations for open-world detection
- Safety and compliance spot-checks for static fixtures
- Sectors: industrial safety, healthcare, education
- Tools/Workflows: detect presence and placement of extinguishers, AEDs, signage, emergency lights, guards; compare 3D positions to policy rules (e.g., clearance)
- Assumptions/Dependencies: reliable open-vocab categories; well-lit, low-occlusion views; policies often require precise measurements—Boxer gives boxes, not certified measurements
- Academic dataset bootstrapping and benchmark creation
- Sectors: academia, software tools
- Tools/Workflows: use Boxer to generate weakly supervised 3DBB labels across heterogeneous sensors/cameras; curate open-world 3D benchmarks with consistent metrics
- Assumptions/Dependencies: quality control via human-in-the-loop verification; domain gaps (egocentric vs. static rigs) should be considered
- Robotics grasping initialization for stationary objects
- Sectors: robotics (manipulation)
- Tools/Workflows: use 3DBB center, size, and yaw as priors for coarse grasp planning or region-of-interest cropping before fine pose estimation
- Assumptions/Dependencies: static-object constraint; non-cuboidal objects may need a downstream shape/pose refinement module
- Warehousing/bin occupancy and slotting
- Sectors: logistics, warehousing
- Tools/Workflows: overhead or forklift cameras detect pallets/boxes and lift to 3D for bin occupancy estimation and slot validation
- Assumptions/Dependencies: clear view of bins; calibration across multi-camera setups; item categories covered by 2D detector
- Software integrations and developer tools
- Sectors: software, robotics, AR/VR
- Tools/Workflows: release as an SDK/ROS2 package; plugins for SLAM stacks (ORB-SLAM, NVBlox) and AR engines; pipeline templates: video-to-3D-Boxes-to-USD
- Assumptions/Dependencies: GPU availability for real-time throughput; on-device performance may require model distillation/quantization
Long-Term Applications
These require further research, engineering, or scaling (e.g., dynamic objects, on-device optimization, standardization).
- Dynamic and articulated object understanding
- Sectors: robotics, autonomous systems, AR
- Tools/Workflows: extend Boxer to track and lift moving objects (hands, carts, robots) and model articulation; integrate motion segmentation and dynamic fusion
- Assumptions/Dependencies: new training data for dynamics; tracker redesign beyond static fusion
- Full-object reconstruction and digital-twin generation
- Sectors: AEC, manufacturing, retail, e-commerce, media
- Tools/Workflows: combine Boxer’s 3DBBs with open-world segmentation and shape recovery (e.g., SAM3D, NeRFs) to auto-generate textured meshes for inventory and virtual staging
- Assumptions/Dependencies: multi-view coverage, high-quality depth; consistent IDs across sessions
- Persistent, cross-session “object cloud” for AR
- Sectors: AR cloud providers, smart buildings
- Tools/Workflows: anchor 3DBBs to a global map across days/weeks; synchronize object updates among users/devices; serve spatial queries via APIs
- Assumptions/Dependencies: scalable cloud backends; stable localization across sessions; privacy controls
- Generalist home robots with open-world object search and fetch
- Sectors: consumer robotics, eldercare
- Tools/Workflows: couple Boxer with VLMs for natural-language goal specification and with grasp/pose estimators for manipulation; use 3DBBs for semantic planning
- Assumptions/Dependencies: robust dynamic handling and closed-loop manipulation; safety and reliability requirements
- Automated regulatory audits and building-code checks
- Sectors: public safety, compliance, insurance
- Tools/Workflows: verify placement and spacing of safety equipment (e.g., exit signage height, extinguisher distance); generate compliance reports from scans
- Assumptions/Dependencies: measurement accuracy, standardization of tolerances, certified workflows
- On-device (edge) AR glasses deployment
- Sectors: wearables, enterprise AR
- Tools/Workflows: compress/quantize BoxerNet and backbone; exploit depth sensors on headsets; stream poses from VIO and run online tracker for continuous object maps
- Assumptions/Dependencies: power and thermal budgets; optimized 2D detector (open-vocab) on-device or offloaded
- Multimodal agents with language-grounded 3D reasoning
- Sectors: software, robotics, education
- Tools/Workflows: integrate Boxer with VLMs (e.g., OWL-like grounding + 3D lifting) to support queries like “what’s on the third shelf left of the sink?” with metric answers and actions
- Assumptions/Dependencies: robust 3D grounding APIs and prompt engineering; mitigation of hallucinations
- Standardized 3D object descriptors and interoperability
- Sectors: standards bodies, industry consortia
- Tools/Workflows: define open formats/APIs for open-world 3DBBs (anchors, extents, confidence, category text) across AR/SLAM/robotics ecosystems
- Assumptions/Dependencies: consensus on schemas and evaluation protocols
- Construction progress monitoring and as-built verification
- Sectors: AEC
- Tools/Workflows: detect and localize installed fixtures and MEP assets with 3DBBs; compare against BIM to flag missing or misplaced items
- Assumptions/Dependencies: robust detection of construction-specific categories; handling partial installs/occlusions
- Privacy-preserving mapping and analytics
- Sectors: policy, smart buildings, retail
- Tools/Workflows: store only 3DBBs (no images) to minimize PII while enabling spatial analytics; differential privacy on object counts/locations
- Assumptions/Dependencies: policy frameworks and auditability; acceptable accuracy with box-only representations
- Autonomous retail (self-checkout and restocking)
- Sectors: retail, robotics
- Tools/Workflows: leverage persistent 3D object maps for product presence checks, restock alerts, and cross-view reconciliation; inform robot pick paths
- Assumptions/Dependencies: scalability in crowded, dynamic environments; SKU-level disambiguation
- Hospital RTLS (vision-based real-time location of equipment)
- Sectors: healthcare
- Tools/Workflows: augment or replace tag-based systems with cameras that maintain 3DBBs for equipment (beds, pumps); support staff queries in AR
- Assumptions/Dependencies: dynamic-object tracking and identity persistence; strict privacy/security requirements
- Safety-critical robotics and autonomous systems
- Sectors: manufacturing, logistics
- Tools/Workflows: use 3DBBs as a redundant perception layer for collision avoidance and safety envelopes; verify minimum distances to hazards
- Assumptions/Dependencies: certified performance in edge cases; deterministic behavior and logging
Cross-Cutting Assumptions and Dependencies (affecting most applications)
- Posed, calibrated images and gravity alignment are required; typically obtained from VIO/SLAM or headset/device SDKs; performance improves with dense or high-quality depth.
- Scenes should be mostly static during capture; dynamic-object handling is not yet robust.
- Open-world 2D detector quality (prompt design, domain coverage) strongly affects recall and precision; misdetections propagate to 3D.
- Non-cuboidal/thin objects may be poorly represented by 3DBBs and could require downstream shape/pose refinement.
- Real-time throughput is demonstrated on desktop GPUs; mobile/edge use may need model distillation/quantization and code optimization.
- Domain gaps exist (e.g., egocentric vs. tripod rigs); additional training or fine-tuning may be needed for niche environments.
Glossary
- 2D bounding box (2DBB): A rectangle in image coordinates that localizes an object in 2D. "lifts 2D bounding box (2DBB) proposals into 3D"
- 3D bounding box (3DBB): A box in 3D space that approximates an object’s location, size, and orientation. "static, global 3D bounding boxes"
- 6-DoF: Six degrees of freedom (3 for position, 3 for rotation) describing a rigid body’s pose. "If 6-DoF pose is not available, the 2-DoF gravity direction … could be used"
- 7-DoF: Seven degrees of freedom, here a 3D box with position (3), size (3), and a single yaw angle (1). "a 7-DoF 3DBB"
- 9-DoF: Nine degrees of freedom, typically position (3), size (3), and full 3D rotation (3 or quaternion). "extend this to a 9-DoF 3DBB representation"
- AdamW: An optimization algorithm combining Adam with decoupled weight decay regularization. "using the AdamW optimizer"
- Aleatoric uncertainty: Uncertainty arising from inherent noise in observations; modeled to make predictions robust. "we incorporate an aleatoric uncertainty for robust regression"
- Autoregressive: A modeling approach that predicts outputs sequentially, conditioned on previous outputs. "formulates 3DBB estimation in an autoregressive way"
- bfloat16: A 16-bit floating-point format with a wider exponent for efficient training/inference. "using bfloat16 on an NVIDIA RTX 4090"
- Camera intrinsics: Parameters of the camera (e.g., focal length, principal point) that define projection. "using known camera intrinsics"
- Chamfer loss: A distance measure between two point sets, used here to align box corners. "using a Chamfer loss"
- Chain-of-Sight (CoS): A decoding strategy that grounds 2D before predicting 3D, mimicking human reasoning. "introduced a Chain-of-Sight (CoS) decoding strategy"
- Circular mean: A way to average angles on a circle, avoiding wrap-around artifacts. "yaw (using a circular mean)"
- Connected components analysis (CCA): A graph-based method to find groups of connected elements. "Connected components analysis (CCA) on G yields a set of clusters"
- Cosine-decaying learning rate: A schedule where the learning rate decreases following a cosine curve. "with a cosine-decaying learning rate that starts at 1e-4 and decays to 1e-5"
- Cross-attention: A transformer mechanism where one set of tokens attends to another set. "via cross-attention"
- DINOv3: A self-supervised vision backbone used for dense visual features. "using a pretrained DINOv3 … backbone"
- DETR: A transformer-based detection framework treating detection as set prediction. "trains a DETR-style 3DBB detector"
- Egocentric: First-person viewpoint, often from head-worn or body-worn cameras. "in egocentric settings without dense depth"
- Gravity-aligned camera coordinate frame: A coordinate frame whose vertical axis aligns with gravity. "in the gravity-aligned camera coordinate frame"
- Intersection-over-Union (IoU): Overlap metric between predicted and ground-truth regions/volumes. "3D intersection-over-union (IoU)"
- Mean Average Precision (mAP): An evaluation metric averaging precision over recall thresholds. "0.532 vs. 0.010 mAP"
- Monocular: Using a single camera/image (no stereo) for perception. "detect objects from monocular images"
- Non-maximum suppression (NMS): A post-processing step that removes redundant overlapping detections. "Finally, 3D non-maximum suppression is applied"
- Open-vocabulary: Ability to handle arbitrary text categories not seen during training. "from 2D open-vocabulary object detections"
- Open-world: A setting where categories are not fixed and can be unconstrained or long-tailed. "open-world 3DBB lifting"
- Precision–recall (PR) curves: Plots of precision versus recall across score thresholds, used for mAP. "generating the PR curves needed in the mAP computation"
- Point cloud (sparse point cloud): A set of 3D points, here sparse, often from SLAM/SfM or sensors. "optional sparse point clouds"
- Quaternion: A 4D representation of 3D rotations without gimbal lock. "estimate a quaternion instead of a single scalar"
- Ray encoding: Representation of per-pixel or per-patch 3D rays derived from camera intrinsics/pose. "ray features … where each ray encoding represents the normalized 3D ray"
- Self-attention encoder: A transformer module where tokens attend to each other within a sequence. "implemented as a self-attention encoder"
- Simultaneous Localization and Mapping (SLAM): Estimating camera pose while building a map from sensor data. "simultaneous localization and mapping (SLAM)"
- Structure-from-Motion (SfM): Recovering 3D structure and camera motion from multiple images. "structure-from-motion (SfM)"
- Transformer: A neural architecture based on attention mechanisms for sequence modeling. "a transformer-based network which lifts 2D bounding box … into 3D"
- Vision Transformer (ViT): A transformer architecture applied to images using patch embeddings. "requires a specialized ViT that processes dense depth only"
- Voxel grid: A 3D grid of volumetric pixels used to represent space/features. "lifts 2D features into a 3D voxel grid"
- Dense depth: Per-pixel depth maps providing depth for most image pixels. "with optional dense depth"
Collections
Sign up for free to add this paper to one or more collections.