LoMa: Local Feature Matching Revisited
Abstract: Local feature matching has long been a fundamental component of 3D vision systems such as Structure-from-Motion (SfM), yet progress has lagged behind the rapid advances of modern data-driven approaches. The newer approaches, such as feed-forward reconstruction models, have benefited extensively from scaling dataset sizes, whereas local feature matching models are still only trained on a few mid-sized datasets. In this paper, we revisit local feature matching from a data-driven perspective. In our approach, which we call LoMa, we combine large and diverse data mixtures, modern training recipes, scaled model capacity, and scaled compute, resulting in remarkable gains in performance. Since current standard benchmarks mainly rely on collecting sparse views from successful 3D reconstructions, the evaluation of progress in feature matching has been limited to relatively easy image pairs. To address the resulting saturation of benchmarks, we collect 1000 highly challenging image pairs from internet data into a new dataset called HardMatch. Ground truth correspondences for HardMatch are obtained via manual annotation by the authors. In our extensive benchmarking suite, we find that LoMa makes outstanding progress across the board, outperforming the state-of-the-art method ALIKED+LightGlue by +18.6 mAA on HardMatch, +29.5 mAA on WxBS, +21.4 (1m, 10$\circ$) on InLoc, +24.2 AUC on RUBIK, and +12.4 mAA on IMC 2022. We release our code and models publicly at https://github.com/davnords/LoMa.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to find the same places in two different photos. Imagine you take a picture of a building during the day and your friend takes one at night from a different angle. The computer’s job is to spot points that are actually the same (like a window corner) in both photos. This skill is called “local feature matching,” and it’s a key part of building 3D models from photos, helping with things like mapping, robotics, and augmented reality.
The authors revisit this classic problem with a modern, data-heavy approach. They build a new system called LoMa and also create a tough new test set called HardMatch to measure real progress.
What questions are the researchers trying to answer?
- Can traditional “local feature” methods (find keypoints, describe them, then match them) get much better if we train them with far more and more varied data, and with bigger models?
- Are the usual tests for matching too easy now—and do we need a harder benchmark to see real differences between methods?
- If we scale up training in smart ways, can local feature methods catch up to or even beat newer “dense” or “detector-free” methods on hard cases?
How did they do it?
The team didn’t invent brand-new building blocks. Instead, they took strong existing parts and trained them better and bigger:
- Detector and descriptors: They detect interesting points in an image and describe each point with numbers that capture its appearance (think: a “fingerprint” for each pixel neighborhood). They use DaD (detector) and DeDoDe (descriptor).
- Matcher: They use a transformer-based matcher (LightGlue), which compares the point “fingerprints” across two images and decides which ones match.
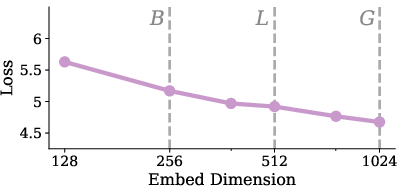
- LoMa: Their system (LoMa) is this detector + descriptor + matcher trained with modern recipes on much larger, more diverse data. They release three sizes: Base (B), Large (L), and Gigantic (G).
To train LoMa well, they:
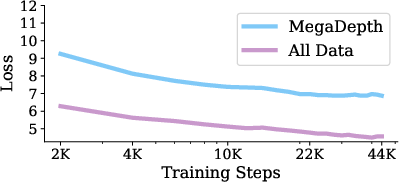
- Collected and mixed 17 different datasets (indoor, outdoor, aerial, synthetic, etc.), much more than typical methods use.
- Built “ground-truth” matches from 3D information (so the training knows which points truly correspond).
- Used a training strategy that gradually refines the features and encourages correct pairs to stand out.
They also created a new benchmark:
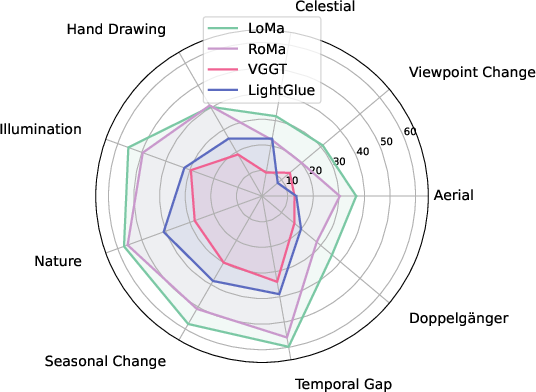
- HardMatch: 1,000 very challenging image pairs manually annotated by the authors. These include really tough cases: day vs. night, old vs. new photos, drawings vs. photos, very different viewpoints (even up to 180°), aerial vs. ground views, and look-alike scenes (“doppelgängers”). This helps measure real progress when easier tests are already “maxed out.”
What did they find?
LoMa made big jumps in accuracy across many tests, especially on hard ones. In several cases, it beats the latest methods that don’t rely on keypoints.
Here are a few highlights in simple terms:
- On the new HardMatch benchmark (the hard one), LoMa did much better than the previous best keypoint-based system—by about 19 percentage points on a key accuracy score.
- On WxBS (another tough, classic benchmark), LoMa set a new state of the art for sparse (keypoint) matchers and even rivaled the best dense methods.
- On visual localization tasks (figuring out exactly where a camera is in a place), LoMa often improved accuracy a lot—sometimes by more than 20 percentage points on strict tests.
- On the Image Matching Challenge 2022 (IMC 2022), LoMa reached a new top score for keypoint-based systems.
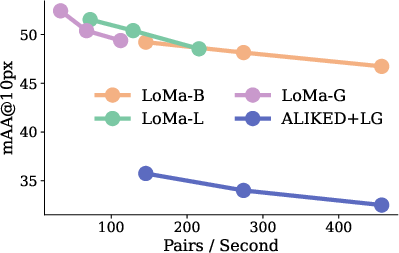
Even better, LoMa is fast: the design lets it “stop early” if you need speed over maximum accuracy, so it can handle hundreds of image pairs per second on a modern GPU.
Why is this important?
- It shows that “old-school” local feature matchers aren’t outdated—they just needed more data and bigger, better training. With the right training, they can match or beat many newer methods, especially on hard problems.
- The new HardMatch benchmark gives researchers a tougher, more realistic way to measure progress, so future improvements will actually matter in the real world.
- Better matching helps many applications:
- Building 3D models from photos (for heritage sites, games, or city planning)
- Accurate localization for robots and AR apps
- Aligning historical images with modern ones
- Handling extreme conditions (night, bad weather, weird angles)
In short, this paper brings a classic technique up to modern standards and proves it can still lead the pack when trained at scale. The authors also share their code, models, and the new HardMatch dataset to help others build on this progress.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper.
Data, supervision, and coverage
- Descriptor overfitting at scale: Identify causes (e.g., limited diversity, weak regularization) and test remedies such as stronger augmentations, curriculum sampling, label-smoothing, self-/multi-view supervision, and distillation to sustain longer descriptor training.
- Ground-truth quality from MVS: Quantify GT noise across the newly generated datasets (MegaDepth Re-MVS, MegaScenes, SpatialVID), measure training sensitivity to GT errors, and explore robust objectives (e.g., noise-aware losses, confidence-weighted supervision).
- Dataset mixture design: Systematically ablate sampling weights and mixing strategies; develop automated curricula or domain-balanced sampling to optimize generalization across broad appearance/viewpoint shifts.
- Training–test leakage control: Verify and publish deduplication checks (near-duplicate and near-duplicate-by-crop) to ensure no overlap between training data and HardMatch; report performance with and without de-duplication.
- Domain gaps not covered: Evaluate and/or extend training data for dynamic scenes, nonrigid motion, rolling shutter distortions, fisheye/omnidirectional cameras, extreme lens distortion, thermal/IR/SAR/underwater modalities, and mobile phone pipelines (intrinsic variability, noise).
- Monocular depth dependence in map-free localization: Measure LoMa’s sensitivity to depth quality (e.g., DA3 variants), and benchmark with multiple depth priors to isolate matcher vs. depth effects.
Architecture, objectives, and learning dynamics
- Joint detector–descriptor–matcher training: Assess whether end-to-end training (including DaD) improves repeatability and matchability under extreme conditions; compare to current decoupled training.
- Positional encoding choices: Test cross-attention with positional encodings (absolute/relative, RoPE variants) and geometry-aware attention to improve wide-baseline and cross-view robustness.
- Matching objective alternatives: Compare dual-softmax to optimal-transport/hard assignment objectives, contrastive losses with harder negatives, or geometry-regularized losses (e.g., epipolar/triangulation consistency).
- Confidence calibration: Evaluate and calibrate matchability and match scores (e.g., ECE, reliability diagrams) to improve downstream robust estimation and adaptive thresholding.
- Assignment strategy and thresholds: Ablate mutual-consistency vs. Hungarian/OT assignment; study sensitivity to the dual-softmax temperature τ and the acceptance threshold μ; propose data-driven or adaptive thresholding.
- Multi-view and cycle consistency: Train with multi-image constraints (cycle consistency, track-level supervision) and measure gains on localization/SfM vs. pairwise-only training.
- Invariance and equivariance: Investigate rotation-, scale-, and viewpoint-equivariant designs (e.g., group-equivariant attention, canonical orientation) to address 180° viewpoint changes and aerial–ground pairs.
- Disambiguation of look-alikes (Doppelgängers): Explore integration of semantics (segmentations, CLIP/LMM features), priors (geo/time metadata), or scene graphs to reduce false correspondences in visually similar but distinct scenes.
Evaluation design and benchmarking
- HardMatch evaluation assumptions: Current F-based protocol assumes static scenes and perspective cameras; design alternative protocols for nonrigid/rolling-shutter/fisheye settings (e.g., homographies, essential matrix with known intrinsics, lens-distorted models, per-pixel warps).
- Annotation reliability: Expand and release multiple independent annotations per pair; quantify inter-annotator agreement and propagate GT uncertainty into evaluation (confidence-weighted PCK).
- Pair selection bias: HardMatch pairs were chosen using RoMa v2 uncertainty; assess selection bias by re-sampling with alternative selectors (e.g., sparse matchers, geometry heuristics) and report robustness of rankings.
- RANSAC and hyperparameter sensitivity: Standardize and publish verification settings; evaluate sensitivity to estimator choice, sampling budgets, and degeneracy handling to ensure fair and reproducible comparisons.
- Multi-view reconstruction metrics: Beyond pairwise pose/PCK, assess full SfM outcomes (track length, completeness, reprojection error, reconstruction accuracy/scale drift) at dataset scale to validate end-to-end impact.
Scalability, efficiency, and deployment
- Memory/latency on edge devices: Measure GPU/CPU/edge memory footprints and latency for 4096 keypoints and large embeddings; explore quantization, pruning, and distillation for mobile deployment.
- Data-dependent early exit: Develop and evaluate confidence-driven early-stopping policies per image pair to optimize the accuracy–throughput Pareto frontier across diverse hardware.
- Keypoint budgeting: Study dynamic keypoint selection (content- or difficulty-aware), per-image keypoint counts, and detector thresholds to optimize compute vs. accuracy in large-scale retrieval/localization pipelines.
Robustness and generalization
- Cross-sensor and cross-domain generalization: Benchmark across cameras with varying intrinsics, rolling shutter artifacts, and unconventional optics; test out-of-domain regimes (e.g., satellite-to-street, night/thermal, underwater).
- Star-field and highly symmetric patterns: Investigate orientation/group-equivariant features and global context cues to address rotational ambiguity and repetitive structures.
Reproducibility and release
- End-to-end reproducibility of GT generation: Release scripts, configs, and checksums for all custom SfM/MVS steps; provide cost estimates and alternatives for users without large compute.
- Hyperparameter exposure: Publish default and tuned values (e.g., τ, μ, RANSAC settings, keypoint counts) and their sensitivity curves to facilitate fair downstream use and comparisons.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage LoMa’s models, training recipes, and the HardMatch benchmark. For each, we indicate sectors, likely tools/workflows, and key assumptions or dependencies.
- Robust SfM and photogrammetry upgrades
- Sectors: software, GIS/surveying, construction, VFX/media
- What: Drop-in replacement of LightGlue/SuperGlue with LoMa-B/L/G in COLMAP- and HLoc-based pipelines to increase reconstruction success and accuracy in hard cases (day/night, seasonal, large view changes).
- Tools/workflows: HLoc+LoMa, COLMAP with DeDoDe descriptors and DaD keypoints; LoMa’s early-stop layers to tune speed vs. accuracy.
- Assumptions/dependencies: Static scenes, perspective cameras, adequate texture, GPU on server or desktop; best performance with DaD+DeDoDe; memory scales with keypoints (e.g., N≈4096).
- Visual localization in GPS-denied settings (map-free or map-light)
- Sectors: robotics, AR/VR, mobile
- What: Map-free relocalization (as in Map-free benchmark) using LoMa for matching and monocular metric depth (e.g., DepthAnything3) to return metric camera pose from a single reference.
- Tools/workflows: Retrieval → LoMa matching → PnP with metric depth → pose check; early stopping for latency budgets on-device.
- Assumptions/dependencies: Depth network quality affects accuracy; camera intrinsics and calibration required; static scenes.
- Day–Night and seasonal relocalization for mobile robots and AVs
- Sectors: robotics, automotive
- What: Improve success rates in challenging appearance changes (validated on InLoc and Oxford Night). Use LoMa for robust pairwise matches after image retrieval.
- Tools/workflows: Retrieval (e.g., NetVLAD/Transformers) → LoMa matching → RANSAC/PnP → local BA; deploy LoMa-B or -L with early exit on robot compute.
- Assumptions/dependencies: Good retrieval to avoid non-overlapping pairs; careful tuning of match thresholds; camera calibration.
- Drone and infrastructure inspection alignment across time
- Sectors: energy, civil infrastructure, insurance
- What: Align repeat flights/images for change detection on bridges, wind turbines, power lines, rooftops under lighting/seasonal differences.
- Tools/workflows: Multi-temporal alignment with LoMa → robust F/Essential matrix → 3D differencing; tie in to inspection platforms.
- Assumptions/dependencies: Sufficient static structure; consistent intrinsics or calibration; exposure/blur management.
- Cultural heritage and historical-photo alignment
- Sectors: cultural heritage, education, tourism
- What: Align century-apart images or sketches-to-photos (captured in HardMatch categories) for storytelling and documentation.
- Tools/workflows: Guided matching with LoMa → homography/F matrix estimation → overlay/AR visualization.
- Assumptions/dependencies: Shared persistent geometry; non-perspective and artwork modalities may still require manual QA.
- Aerial-to-ground image matching for mapping and map updates
- Sectors: GIS/surveying, mapping
- What: Align UAV or aerial images with ground-level photography for map anchoring, façade mapping, and urban digital twins.
- Tools/workflows: Candidate pairing (coarse geospatial heuristics/retrieval) → LoMa matching → multi-view geometry fusion.
- Assumptions/dependencies: Large viewpoint and scale differences may need careful RANSAC and normalization; relief displacement handling; static scenes.
- Film/VFX tracking under difficult lighting and viewpoints
- Sectors: media/entertainment
- What: More reliable match-moving/track solving when frames differ significantly (lighting, partial occlusions).
- Tools/workflows: Integrate LoMa into match-move tools (e.g., Nuke, PFTrack) as the matching backend; use early exit for interactive latency.
- Assumptions/dependencies: Scene elements must be relatively static between frames; camera metadata improves stability.
- Panorama stitching and consumer 3D scanning apps
- Sectors: software, mobile
- What: Fewer stitching failures in low-light/low-texture scenes and more robust feature tracks for phone-based 3D scanning.
- Tools/workflows: LoMa-B128 for on-device resource budgets; adjust stopping layers to meet latency targets (<30 ms per pair if needed).
- Assumptions/dependencies: Mobile optimization (quantization, NPU acceleration); proper feature density and overlap.
- Vendor evaluation and QA with HardMatch
- Sectors: industry R&D, academia, procurement/policy
- What: Use HardMatch’s 1000 hand-labeled pairs to stress-test feature matching for robustness claims and regressions.
- Tools/workflows: Integrate HardMatch into CI pipelines; track mAA@px and break down by subgroup (e.g., low-light, aerial-ground).
- Assumptions/dependencies: Benchmark focuses on static, perspective imagery; not a substitute for domain-specific data.
- In-house training data curation with LoMa’s MVS recipe
- Sectors: software, academia, robotics
- What: Reuse their pipeline to generate high-quality GT correspondences from internal collections (e.g., for factories, campuses).
- Tools/workflows: COLMAP SfM/MVS or custom PatchMatch; RoMa v2 correspondences for MVS depth bootstrapping; then LoMa training/fine-tuning.
- Assumptions/dependencies: Compute resources for MVS; data licensing; static scenes; careful reconstruction filtering.
- On-device AR anchoring with latency–accuracy tuning
- Sectors: AR/VR, mobile
- What: Use LoMa’s early-stopping layers to meet tight latency budgets for AR anchors and relocalization on phones/glasses.
- Tools/workflows: LoMa-B128 at L=3–5 layers; pair with IMU/VIO; fallback to server-side for re-anchoring when necessary.
- Assumptions/dependencies: Mobile inference optimization; platform SDK integration (ARCore/ARKit); power constraints.
- Academic teaching and benchmarking
- Sectors: education, research
- What: Teach modern local feature matching and evaluation, using the released code/models and HardMatch to compare sparse/dense approaches.
- Tools/workflows: Course labs with LoMa vs. LightGlue/SuperGlue; ablations on data scale and model size.
- Assumptions/dependencies: GPU access; dataset licenses.
Long-Term Applications
These use cases require additional research, scaling, domain adaptation, or engineering before broad deployment.
- City-scale, 24/7 Visual Positioning Services (VPS)
- Sectors: AR/VR, mapping, navigation
- What: Global AR geolocation reliable across day/night, seasons, and years by combining retrieval with LoMa-class matching at scale.
- Dependencies: City-scale maps and indexing, privacy-preserving storage, continuous updates, mobile inference accelerators.
- Cross-modal and non-perspective matching (e.g., thermal↔RGB, sketch↔photo, fisheye)
- Sectors: defense/public safety, cultural heritage, robotics
- What: Extend LoMa training to multi-sensor and non-perspective cameras for broader deployments.
- Dependencies: New datasets and labels (beyond HardMatch), adaptations of positional encoding/geometry, evaluation beyond F-matrix.
- Hybrid feed-forward reconstruction with sparse–dense fusion
- Sectors: software, robotics, VFX
- What: Use LoMa to seed or refine dense feed-forward reconstructions (e.g., MASt3R/VGGT hybrids) for faster and more reliable recon under extremes.
- Dependencies: Joint training objectives, system-level latencies, cross-component calibration.
- 4D digital twins and persistent change detection
- Sectors: construction, smart cities, energy, insurance
- What: Long-term monitoring with robust alignment across months/years for maintenance and compliance audits.
- Dependencies: Temporal modeling, dynamic object handling, scalable storage and versioning, robust outlier rejection.
- Low-power embedded matchers for micro-drones and wearables
- Sectors: robotics, consumer electronics
- What: Pruned/quantized LoMa variants with hardware acceleration for resource-constrained devices.
- Dependencies: Co-design with NPUs/ASICs, quantization-aware training, maintaining robustness after compression.
- Standardized procurement benchmarks and policy guidelines
- Sectors: policy, public procurement, standards bodies
- What: Evolve HardMatch-like suites into standardized acceptance tests for vision components in public infrastructure or defense.
- Dependencies: Broader domain coverage (non-static/rolling shutter), auditing/oversight processes, dataset governance.
- Ground–satellite and UAV–satellite cross-view matching
- Sectors: GIS, disaster response, defense
- What: Align ground imagery with satellite maps for rapid situational awareness and map updates.
- Dependencies: Training on cross-view datasets, handling relief, scale, and spectral differences; specialized geometric models.
- Reliable localization in adverse weather (rain/snow/fog)
- Sectors: robotics, automotive
- What: Robust matching under scattering/blur and sensor soiling, integrated with multi-sensor fusion.
- Dependencies: Adverse-weather training data, multi-sensor alignment (LiDAR, radar), safety certification.
- Privacy-preserving on-device mapping and relocalization
- Sectors: mobile, policy
- What: Keep feature matching and relocalization on-device to reduce data exfiltration.
- Dependencies: Efficient on-device LoMa variants, encrypted maps, federated learning for updates.
- Large-scale consumer photo organization and deduplication with geometric verification
- Sectors: consumer software, cloud services
- What: Group photos/events across time and devices with robust geometric matches (not just global features) to avoid false positives.
- Dependencies: Scalable retrieval to prefilter candidates, cost control for pairwise matching at scale, privacy controls.
Notes on Assumptions and Dependencies (Cross-cutting)
- Scene assumptions: Most evaluations assume static scenes and perspective cameras; substantial dynamics, rolling shutters, or non-perspective optics may require method adaptations.
- Component coupling: Best results are with DaD keypoints and DeDoDe descriptors retrained under LoMa’s recipes; mixing components is possible but may reduce gains.
- Compute: Training uses significant GPU resources; inference can be tuned via LoMa’s layer-wise early stopping to meet latency/throughput targets.
- Data licensing: When adopting the training recipe, ensure rights to run SfM/MVS and redistribute derived annotations where applicable.
- Retrieval prerequisite: For large databases, robust image retrieval remains necessary to avoid non-overlapping pairs before running LoMa.
- Depth for map-free use: Metric relocalization hinges on high-quality monocular depth or alternative metric cues (e.g., stereo, LiDAR).
These applications follow directly from LoMa’s superior matching robustness in extreme conditions, the speed–accuracy dial provided by layer-wise early stopping, and the new HardMatch benchmark that enables more realistic QA and progress tracking.
Glossary
- AUC: Area Under the Curve; a threshold-aggregated performance metric commonly used for pose/matching accuracy. "outperforming the state-of-the-art method ALIKED+LightGlue by +18.6 mAA on HardMatch, +29.5 mAA on WxBS, +21.4 (1m, 10) on InLoc, +24.2 AUC on RUBIK, and +12.4 mAA on IMC 2022."
- AdamW: An optimizer that decouples weight decay from gradient updates for stable training. "For all training, we use the AdamW~\cite{loshchilov2018decoupled} optimizer"
- COLMAP: A popular Structure-from-Motion and Multi-View Stereo pipeline used to reconstruct scenes and compute depth. "We run COLMAP~\cite{schoenberger2016sfm} MVS (photometric+geometric, default settings) on all scenes"
- cosine annealing learning rate: A schedule that smoothly decays the learning rate following a cosine curve. "We use a cosine annealing learning rate with a peak learning rate of "
- cross-attention: An attention mechanism where tokens from one sequence attend to tokens in another sequence to exchange information. "consisting of transformer blocks that alternate between self-attention and cross-attention layers"
- descriptor: A vector representation of a local image patch used to compare keypoints across images. "The keypoints are assigned descriptions using a neural network called the descriptor "
- detector-free methods: Matching approaches that forgo explicit keypoint detection and match densely across images. "local feature matching has recently been overshadowed in the literature by the advent of detector-free methods such as LoFTR~\cite{sun2021loftr} and RoMa~\cite{edstedt2024roma}"
- dual-softmax: A matching formulation/loss that applies softmax across rows and columns to produce mutual assignment scores. "we follow DeDoDe~\cite{edstedt2024dedode} and use a dual-softmax based loss."
- epipolar error: The geometric error of correspondences relative to the epipolar constraint under a fundamental matrix. "they use the epipolar error of the GT correspondences under a Fundamental matrix"
- Exponential Moving Average (EMA): A technique that maintains a smoothed version of model parameters during training. "and use Exponential Moving Average (EMA) with a decay factor of ."
- feed-forward reconstruction: Methods that directly predict 3D/pose outputs in a single forward pass rather than via classical pipelines. "and feed-forward reconstruction models such as MASt3R~\cite{leroy2024grounding} and VGGT~\cite{wang2025vggt}"
- Fundamental matrix: A 3×3 matrix encoding the epipolar geometry between two uncalibrated views. "Following WxBS, we evaluate by estimating a Fundamental matrix using correspondences from the matcher"
- geometric verification: Post-processing that enforces geometric consistency (e.g., epipolar constraints) to filter matches. "encouraging overfitting to benchmark-specific artifacts, such as particular geometric verification settings,"
- graph attention network: A neural architecture using attention on graphs; here used to reason globally over keypoints. "SuperGlue~\cite{sarlin2020superglue} proposed replacing the nearest neighbor matcher with a graph attention network, allowing global reasoning on local keypoint descriptors."
- keypoint: A salient image location used for establishing correspondences between images. "The aim in two-view matching is to obtain correct keypoint correspondences between two images"
- matchability: A per-keypoint prediction indicating whether a keypoint has a valid match in the other image. "In each layer of , we use the dual-softmax loss \eqref{eq:desc_loss} on the refined features, passed through a linear head, along with a separate matchability loss."
- mAA: Mean Average Accuracy; here reported at pixel thresholds (e.g., mAA@10px) for correspondence accuracy. "LoMa-G achieves the best result of 54.3 mAA@10px, approximately 20 points below its performance on WxBS."
- Multi-View Stereo (MVS): A technique to estimate dense depth from multiple calibrated images. "We run COLMAP~\cite{schoenberger2016sfm} MVS (photometric+geometric, default settings) on all scenes"
- mutual nearest neighbor matching: A matching strategy that keeps pairs where each descriptor is the nearest neighbor of the other. "We compare LoMa to SotA matchers, detection+description with mutual nearest neighbor matching, and feed-forward reconstruction methods"
- PatchMatch: A randomized optimization algorithm for fast approximate patch correspondence used in stereo/MVS. "with a simple native PyTorch~\cite{paszke2019pytorch} PatchMatch implementation to compute depth maps."
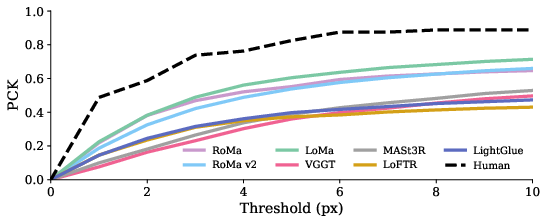
- Percentage of Correct Keypoints (PCK): The fraction of keypoints whose reprojection error falls below a given threshold. "We compute the percentage correct keypoints (PCK) under different pixel error thresholds."
- relative pose estimation: Computing the rotation and translation between two camera views from correspondences. "We compare LoMa to SotA matchers, detection+description with mutual nearest neighbor matching, and feed-forward reconstruction methods on relative pose estimation."
- Rotary Position Embeddings (RoPE): A positional encoding that injects relative position via rotations in attention. "Rotary position embeddings (RoPE)~\cite{rope} are used in the self-attention computation, making the attention scores dependent on the relative positions ."
- self-attention: An attention mechanism where tokens attend to others within the same sequence. "Self-attention is applied by each point attending to all points of the same image"
- soft assignment matrix: The matrix of mutual assignment probabilities produced by dual-softmax across rows and columns. "The loss encourages the dual-softmax matrix (also called soft assignment matrix)"
- sparse matching: Matching approaches that operate on a finite set of detected keypoints rather than all pixels. "and for sparse matching with models such as SuperGlue~\cite{sarlin2020superglue} and LightGlue~\cite{lindenberger2023lightglue}."
- Structure-from-Motion (SfM): The process of reconstructing 3D structure and camera poses from images. "Structure-from-Motion (SfM)~\cite{hartley2003multiple} aims to reconstruct the 3D world from unordered images"
- visual localization: Estimating a camera’s 6-DoF pose in a known scene using images. "Feature matchers are commonly evaluated through relative pose estimation on sparse views from successful 3D reconstructions, such as MegaDepth~\cite{li2018megadepth} and ScanNet~\cite{dai2017scannet}, or visual localization~\cite{taira2018inloc, sattler2018benchmarking, Jafarzadeh_2021_ICCV, arnold2022map}."
- Virtual Correspondence Reprojection Error (VCRE): A metric for map-free relocalization that evaluates consistency of virtual correspondences via reprojection error. "Following the benchmark, we use the Virtual Correspondence Reprojection Error (VCRE<90px) and report the results for the validation set in \cref{tab:visloc}."
Collections
Sign up for free to add this paper to one or more collections.

