- The paper introduces a hypothesis-driven pipeline that identifies LLM weaknesses through error analysis and generates challenging math problems.
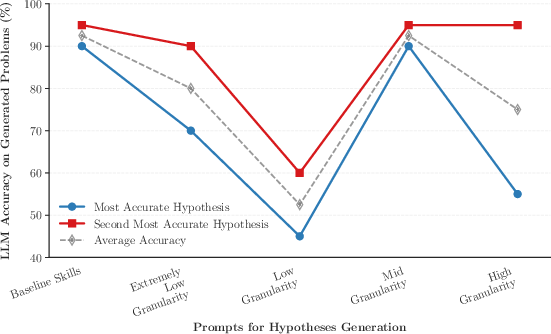
- The methodology leverages failing problem filtering and hypothesis granularity, reducing solve rates from 77% to 45% for generated problems.
- The approach provides a scalable framework for automated benchmarking of LLMs, with potential applications beyond mathematics.
Automatically Generating Hard Math Problems from Hypothesis-Driven Error Analysis
Introduction
This paper introduces a hypothesis-driven, fully automatic pipeline for generating challenging mathematics benchmark items targeting LLM weaknesses. The approach leverages the Hypogenic framework for natural-language hypothesis generation to systematically identify mathematical concept areas where a specific LLM consistently fails, then prompts new problem generation conditioned on these high-accuracy hypotheses. This process is motivated by fundamental limitations in the scalability and adaptability of traditional, human-authored benchmarks and the unsuitability of existing automatic generation techniques for fine-grained error analysis.
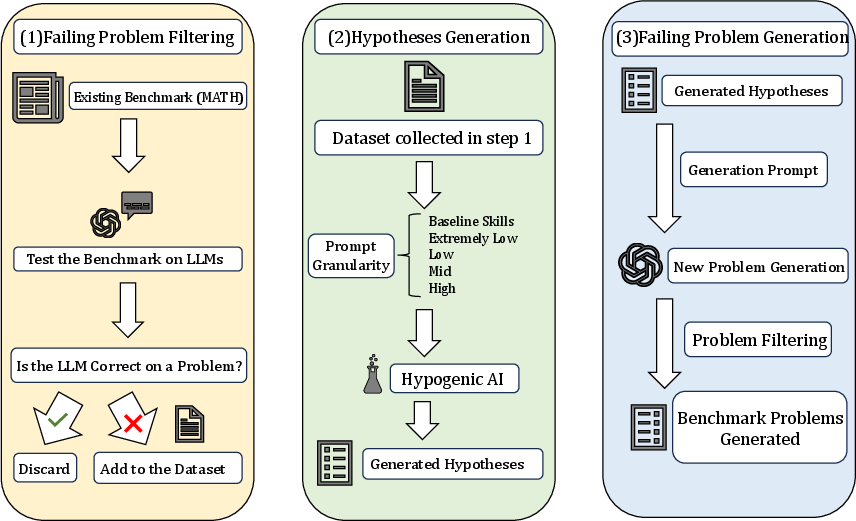
Figure 1: Overview of the three-stage generation pipeline: (1) filter problems consistently failed by the target LLM, (2) generate hypotheses about underlying failure concepts, (3) generate new problems targeting those weaknesses.
Methodology
The pipeline executes three sequential stages:
Failing Problem Filtering. The target LLM is evaluated on a math benchmark (e.g., MATH), and items with consistent failure (missed in all attempts) are selected. This procedure controls for sampling noise and identifies domains of persistent deficiency.
Hypothesis Generation. Adopting Hypogenic, the pipeline generates natural-language hypotheses about concepts/skills linked to observed errors. Multiple taxonomies of mathematical concepts are used to probe the impact of hypothesis granularity. Hypotheses are scored by their predictive accuracy on the observed label distribution.
Challenging Problem Generation. High-accuracy hypotheses condition LLM-guided creation of new problems specifically intended to stress the target model. Model answers are validated by cross-verification with multiple top LLMs and filtered for well-posedness.
This architecture minimizes human oversight and decouples the process from human-written seed questions, differing from copy-perturb approaches or prompt-based generation that typically fail to target specific weaknesses or require extensive human input.
Analysis of Hypothesis Granularity
Systematic experiments are performed across five granularities of mathematical taxonomy: from a small set of coarse categories to a redundant, highly fine-grained skill list. For each, the accuracy of generated hypotheses (with model variants such as GPT-4.1-mini, GPT-4o-mini, Qwen3-14B) is analyzed, with particular focus on how this affects the downstream difficulty of the generated benchmarks.
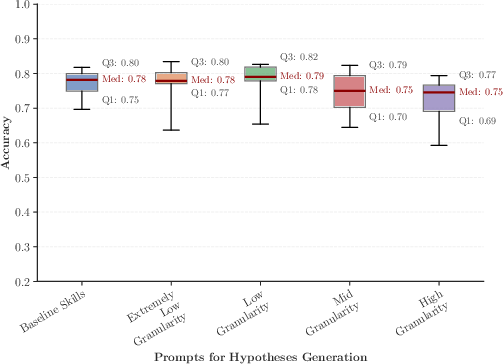
Figure 2: Hypothesis accuracy distributions across taxonomy granularity levels (GPT-4.1-mini backbone); low granularity yields the highest functional accuracy.
The number of high-accuracy hypotheses obtained at each granularity is also quantified, with results demonstrating a clear peak for low-granularity taxonomies.
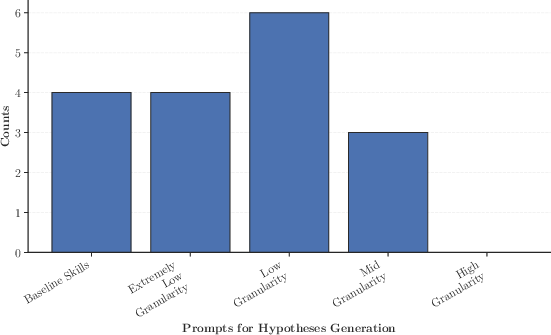
Figure 3: Number of hypotheses with accuracy above 0.8 (GPT-4.1-mini) for different taxonomy granularities.
Benchmark Generation and Difficulty Characterization
The effect of the hypothesis-driven procedure is evaluated by using the best hypotheses at each granularity to generate new math problems. The same LLM (Llama-3.3-70B-Instruct) is benchmarked on these new sets. Key quantitative observations include:
This validates that hypothesis accuracy serves as a robust proxy for the problem generation power and confirms a direct operational link between targeted error analysis and benchmark difficulty escalation.
Comparative Evaluation and Limitations
Compared with prior art, this method directly links observed error surfaces to generative control, surpassing both extension methods (which perturb existing items) and prompt-chaining approaches (which lack fine error targeting). Its main constraints are in sample efficiency (evaluation based on 20 items/hypothesis), which can lead to volatility in solve rate estimates, and the reliance on self-consistency filtering (potentially subject to generator model shortcomings, especially when probing its own weakest areas). The observed associations between failure patterns and concepts are also statistical, and may not fully resolve confounding factors such as prompt sensitivity or auxiliary skill requirements.
Application Scope and Implications
The pipeline is not constrained to mathematics; by adjusting the hypothesis prompt, it may detect and probe failures around language, multi-step reasoning, or other domains. The method provides an automatic tool for stress-testing LLMs on compositional and non-canonical skills. Theoretically, it enables more agile co-evolution of benchmarks with advancing models, addressing overfitting and evaluation staleness in benchmarks that are repeatedly exposed to new model iterations. Practically, it offers a template for scalable, systematic benchmarking in settings where manual expansion is infeasible.
Future Directions
Natural directions include scaling up evaluation set sizes, expanding to additional LLM architectures, decoupling the generator/target models, and using hypothesis prompts to explicitly control for non-content confounds (solution length, wording, step complexity). The causal link between predicted weaknesses and observed failures could be further interrogated, potentially via fine-grained cross-domain or adversarial hypothesis generation.
Conclusion
This paper presents and validates a scalable, hypothesis-driven system for automatic generation of math problems maximizing LLM failure exposure. It empirically demonstrates that high-accuracy hypotheses conditioned on low-granularity taxonomies yield items of maximal challenge to state-of-the-art models, with observed solve rates dropping to 45%. The general strategy applies to other domains, provided that a foundational benchmark and concept taxonomy are available, and offers a roadmap to evolving, fine-tuned evaluation as models advance.