- The paper introduces a domain-adapted LLM fine-tuned with curated COBOL datasets, significantly enhancing code generation and translation tasks.
- The methodology employs an automated data augmentation pipeline with LLM-based repair and AST-based semantic filtering to generate high-quality training data.
- Empirical results show that the COBOL-Coder-14B model achieves superior Compilation Success Rate and Pass@1 metrics, outperforming general-purpose LLMs on COBOL tasks.
COBOL-Coder: Domain-Adapted LLMs for COBOL Code Generation and Translation
Introduction and Motivation
COBOL persists as a cornerstone technology in legacy systems for sectors such as finance, insurance, and government. Despite this centrality, general LLMs demonstrate poor performance in both code generation and translation tasks involving COBOL. The underlying factors include a severe scarcity of high-quality training corpora, lack of comprehensive benchmarks, and significant divergence between legacy and modern programming paradigms—each of which impedes LLM adaptation. The "COBOL-Coder" work systematically addresses this gap by providing a domain-adapted LLM, curated datasets, new evaluation benchmarks, and in-depth qualitative developer assessments, enabling robust automation of COBOL-centric software engineering tasks (2604.03986).
Automated Data Augmentation Pipeline
The primary bottleneck for LLM deployment on COBOL is the paucity of clean, representative training data. The proposed pipeline integrates static and dynamic validation, cross-language augmentation, and sophisticated filtering using LLM-in-the-loop and AST-based metrics. The process involves:
- Mining and deduplicating public COBOL code from GitHub,
- Validating code via compilation with iterative LLM-based repair,
- Generating synthetic instruction data via high-resource-to-COBOL translation,
- Filtering translation pairs through LLM-based scoring and AST-normalized semantic validation,
- Curating technical documentation as contextual QA pairs.
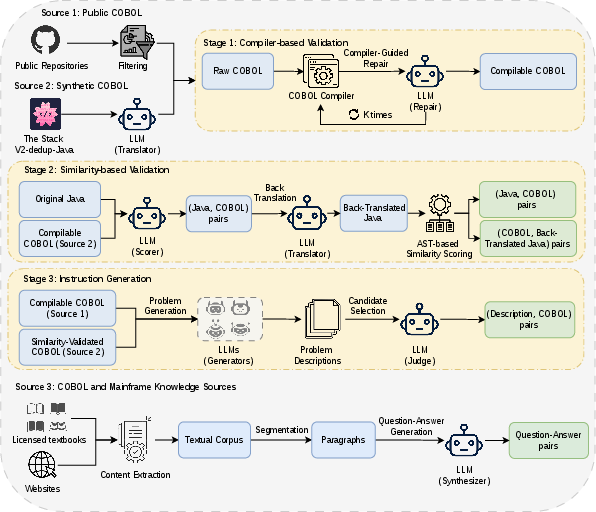
Figure 1: Automated data augmentation pipeline integrating compiler validation, LLM-based repair, semantic filtering, and instruction synthesis.
This pipeline produced a training corpus scaling from 38M tokens of cleaned COBOL code up to over 240M tokens when augmented with synthetic and knowledge resources.
Model Tuning and COBOL-Coder Architecture
COBOL-Coder utilizes Qwen2.5-Coder as its base—selected for architectural optimizations pertinent to code synthesis. No architectural modifications were introduced; domain specialization was achieved exclusively using fine-tuning on instructionally curated datasets targeting COBOL and mainframe semantics. Experimental variants included 7B and 14B parameter versions, optimized using large-batch AdamW, extended sequences (4096 tokens), and convergence criteria based on validation curves.
Evaluation Benchmarks and Experimental Setup
Evaluation spans three primary axes:
- Code Generation: COBOLEval and COBOLCodeBench, reflecting variations from function-level tasks to complex, industrial scenarios.
- Bidirectional Translation: COBOL-JavaTrans, a newly constructed benchmark supporting both COBOL-to-Java and Java-to-COBOL directions, each reflecting modernization and legacy restoration workflows.
- Developer Survey: Task-level and open-ended assessments by experienced COBOL practitioners on generated outputs from COBOL-Coder, GPT-4, and GPT-4o.
Metrics include Compilation Success Rate (CSR) and Pass@1—targeting not just syntactic validity but true functional correctness under test suites.
Strong Empirical Results
Code Generation
COBOL-Coder-14B achieves 73.95% CSR and 49.33 Pass@1 on COBOLEval, and 26.09%/4.35 (CSR/Pass@1) on the more challenging COBOLCodeBench. In contrast, even advanced baselines such as GPT-4o plateau at 41.8%/16.4, with other open-source LLMs and code-specific models largely failing to generate compilable COBOL at all.
Bidirectional Translation
On COBOL-to-Java, COBOL-Coder-14B achieves 97.9% CSR and 83.91 Pass@1, reaching parity with 120B-parameter generalist models but with an order of magnitude fewer parameters. For the harder Java-to-COBOL task, COBOL-Coder-14B delivers 72.03% CSR and 34.93 Pass@1, while all general-purpose LLMs converge to zero or negligible scores.
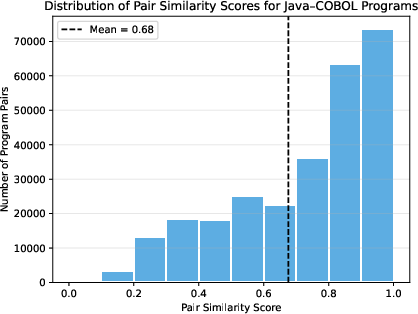
Figure 2: Distribution of pair similarity scores in LLM-based Java–COBOL pair scoring; validates cross-language semantic alignment.
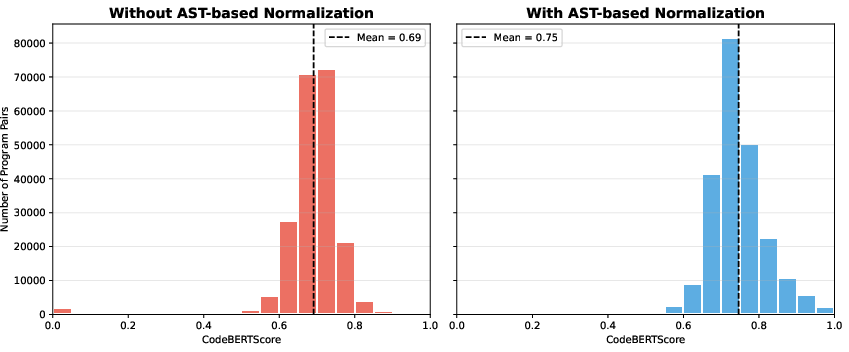
Figure 3: Comparison of CodeBERTScore similarity distributions with and without AST-based normalization in back-translation validation.
Developer Assessment and Usability
A practitioner survey was conducted with ten tasks spanning code generation, COBOL-to-Java, and Java-to-COBOL translation.
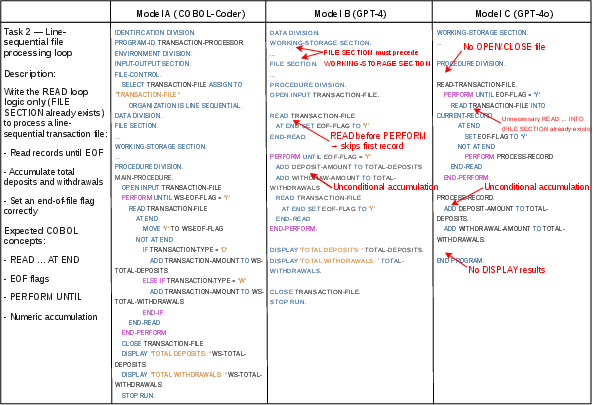
Figure 4: Example survey task with COBOL code generated by three models, annotated with error highlights.
COBOL-Coder was consistently ranked highest for the Java-to-COBOL direction and was either first or tied for first on most COBOL generation tasks. Qualitative findings affirm that COBOL-Coder exhibits stronger awareness of COBOL-specific idioms, pragmatic enterprise patterns (especially batch-style workflows), and produces code that requires significantly less post-processing prior to production deployment. Developers emphasized COBOL-Coder's advantages in structural fidelity, error-free compilation, and reduction of cognitive load, though human oversight remains indispensable for complex, system-level logic.
Implications and Future Directions
The work demonstrates that model scaling for LLMs must be matched by targeted domain-adaptive curation to achieve strong results in low-resource legacy languages. Cross-language transfer and careful semantic vetting are crucial to constructing trustworthy synthetic examples. The clear asymmetry between modern-to-legacy (more difficult) and legacy-to-modern translation indicates intrinsic complexity barriers that only domain-adapted models can address. While COBOL-Coder is validated at the file/program level, practical adoption for production modernization will require system-level context handling—repository-wide modeling, copybook support, handling of JCL, and vertical integration with mainframe development tools.
Conclusion
"COBOL-Coder" delivers a complete pipeline for domain specialization of LLMs applied to a critical legacy language. Numeric results demonstrate that both performance and pragmatic developer acceptance hinge on COBOL-adaptive training data and evaluation. While model-aware repair, similarity-based filtering, and innovative translation benchmarks provide immediate improvements, deeper system-level integration and workflow compatibility will dictate future developments.
The methodological and empirical findings lay a foundation for machine learning applications in mainframe modernization and automatic migration scenarios, extending beyond COBOL to other low-resource, high-stakes programming domains.