- The paper demonstrates that COBOLAssist leverages iterative compiler feedback to repair LLM-generated COBOL code, boosting compilation success rates (e.g., GPT-4o CSR from 41.8% to 95.89%).
- The methodology establishes a detailed error taxonomy categorizing issues into incomplete code, syntax, and type-related errors in COBOL programs.
- Empirical evaluation shows that COBOLAssist typically resolves errors within two iterations, making it effective for modernizing legacy COBOL systems.
An Expert Summary of "COBOLAssist: Analyzing and Fixing Compilation Errors for LLM-Powered COBOL Code Generation"
Introduction
This paper systematically addresses the acute reliability issues of LLM-generated COBOL code, which arises both from the syntactic intricacies and the domain scarcity of COBOL, a legacy language still central to core business and governmental computation. It introduces COBOLAssist, an LLM-in-the-loop self-debugging framework that leverages iterative compilation feedback to repair and enhance the syntactic and functional correctness of code generated by general and COBOL-specialized LLMs. The empirical analysis elucidates error taxonomies specific to LLM-generated COBOL and positions COBOLAssist as an effective repair pipeline for these errors.
COBOL Code Structure and Generation Challenges
COBOL’s rigid, English-like, multi-division architecture and its verbose, redundant constructs present substantial parsing and generation demands, especially for LLMs that are not specifically fine-tuned for COBOL. A COBOL program comprises four required divisions (Identification, Environment, Data, Procedure) in strict sequential order, with further sectioning for data and logic encapsulation.
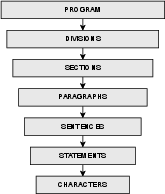
Figure 1: Structure of a standard COBOL program illustrating division and section hierarchy.
LLMs frequently mismanage these structures, particularly DATA and PROCEDURE DIVISION boundaries, and often mishandle scoping between WORKING-STORAGE, FILE, and LINKAGE SECTIONS. Deviation from these conventions typically results in non-trivial syntactic failures, as observed in incorrectly duplicated LINKAGE SECTION declarations.

Figure 2: Error-inducing COBOL example—duplicate LINKAGE SECTION declarations resulting in syntax violation.
Compilation Error Analysis in LLM-Generated COBOL
Categorization Process
The paper introduces a grounded taxonomy for compilation errors in LLM-generated COBOL. Using COBOLEval, human annotators classified errors from 876 generated programs spanning leading generalist (GPT-3.5, GPT-4, GPT-4o/mini) and COBOL-specialized (mAInframer) LLMs. The error annotation was robust (Cohen’s κ=0.9), resulting in three core error superclasses: incomplete code, syntax, and type-related errors.
Error Types and Prevalence
Statistically, LLM-produced errors are highly concentrated (most notably, 35.1% in program structure misuse, nearly double human baseline).
COBOLAssist: Compiler-in-the-Loop Self-Debugging
COBOLAssist implements an iterative repair loop driven by real-time GnuCOBOL compilation feedback. The LLM is prompted as a “COBOL software engineer,” receiving both the error context and complete failed code, and is tasked with applying corrections. Iterations continue up to a defined cap or until the program compiles.
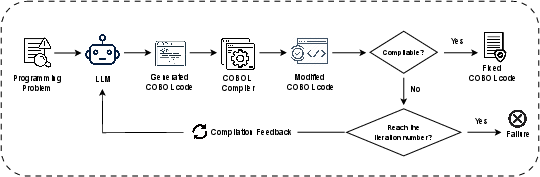
Figure 4: COBOLAssist pipeline—showing iterative compilation, error extraction, code revision, and re-compilation cycle.
COBOLAssist’s compiler-guided prompt engineering outperforms zero-shot refinements: inclusion of structured compiler error feedback catalyzes the LLM’s ability to disambiguate complex COBOL syntactic issues, especially those it failed to resolve in a pure “self-improvement” context.
Empirical Evaluation
Benchmark and Models
Evaluation leverages COBOLEval (146 tasks derived from HumanEval-Python, with multiple test cases per task). The models tested include GPT-3.5, GPT-4, GPT-4o-mini, GPT-4o, and mAInframer-7B/13B/34B.

Figure 5: Representative input task from COBOLEval, demonstrating the style and complexity spectrum of evaluation problems.
Compilation Success and Functional Correctness
Significant increases in Compilation Success Rate (CSR) and pass@1 (functional correctness) are observed after applying COBOLAssist:
- GPT-4o: CSR from 41.8% → 95.89%; pass@1 from 16.4 → 29.45.
- GPT-4: CSR from 31.91% → 55.17%; pass@1 from 9.1 → 22.6.
- mAInframer-34B (COBOL-fine-tuned): highest CSR (97.94%) but weakest functional correctness improvement (pass@1 from 10.27 to 11.67), exposing a generalization gap.
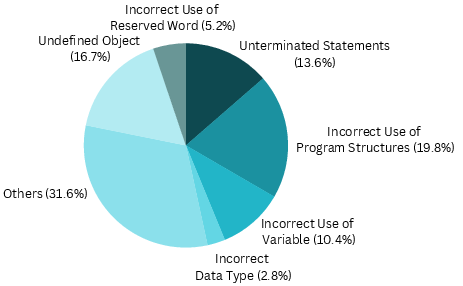
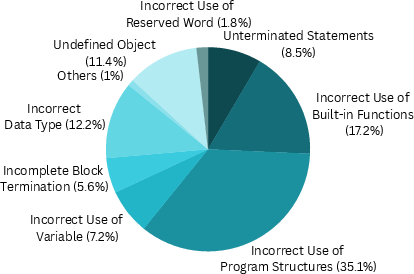
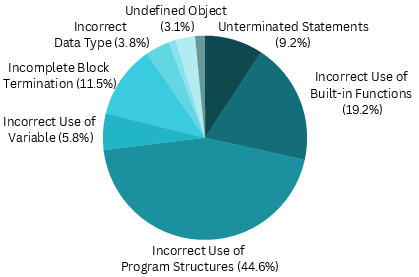
Figure 6: Error type distribution and reduction in human, pre- and post-COBOLAssist LLM-generated code, exhibiting strong contraction of error surface after repair.
Most error elimination occurs in variable/object naming and typing. However, LLMs—even with compiler feedback—remain challenged by deeply structural and multi-line errors (e.g., complex IF/END-IF nesting, consolidated block termination).
Efficiency and Repair Dynamics
COBOLAssist typically resolves failures within two iterations per code sample, indicating high local repair efficiency. Diminishing returns are reached beyond three iterations (experiments show pass@1 plateaus).
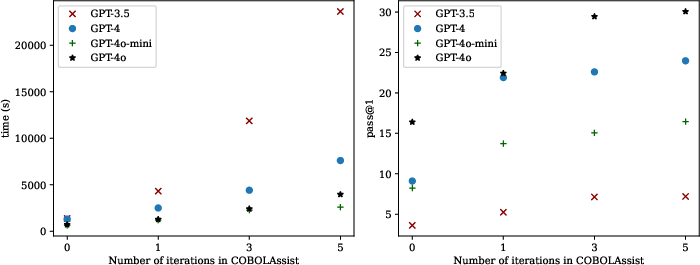
Figure 7: Effect of COBOLAssist repair iteration count on pass@1 and execution time, demonstrating optimality at three to five iterations per program.
Limitations and Open Challenges
Even after COBOLAssist, structural errors (duplication of program sections, block termination inconsistencies), and incorrect function usage persist, especially in cases where error context or structural flow exceeds the LLM’s context window or reasoning horizon. Functional errors (as opposed to purely syntactic ones) display only modest improvements. This underscores an ongoing need for hybrid program analysis/repair (e.g., syntax tree-based interventions) and semantic test-based validation.
Implications and Future Directions
- For Practitioners: Immediate application of COBOLAssist can substantially increase reliability of LLM-generated COBOL in legacy code modernization. Developers should anticipate and proactively check for function misuse and block alignment errors unique to LLM output.
- For Model Developers: The systemic taxonomy of error types in LLM-generated COBOL highlights precise directions for finetuning, especially in structural prompting and code pre/postprocessing.
- For Automated Program Repair: COBOLAssist demonstrates the necessity—and effectiveness—of integrating static compiler feedback within LLM-coding workflows for legacy DSLs. Further gains will likely require explicit syntax- and semantics-aware repair or fine-tuning on program structure transformation operations.
Conclusion
COBOLAssist delivers a practical, compiler-in-the-loop repair workflow for LLM-generated COBOL, nearly tripling syntactic correctness (CSR) and delivering measurable functional gains across both general-purpose and COBOL-specialized LLMs. The empirical breakdown provided offers an authoritative foundation for future research into reliable LLM-based code generation and legacy language maintenance, and sets the groundwork for more semantically competent LLM-powered repair and translation systems.
