Black-Box On-Policy Distillation of Large Language Models
Abstract: Black-box distillation creates student LLMs by learning from a proprietary teacher model's text outputs alone, without access to its internal logits or parameters. In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation. GAD frames the student LLM as a generator and trains a discriminator to distinguish its responses from the teacher LLM's, creating a minimax game. The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback. Experimental results show that GAD consistently surpasses the commonly used sequence-level knowledge distillation. In particular, Qwen2.5-14B-Instruct (student) trained with GAD becomes comparable to its teacher, GPT-5-Chat, on the LMSYS-Chat automatic evaluation. The results establish GAD as a promising and effective paradigm for black-box LLM distillation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Guide to “Black-Box On-Policy Distillation of LLMs”
What this paper is about
The paper explains a new way to train a smaller, faster AI model (the “student”) to act like a bigger, more powerful one (the “teacher”), even when the teacher is a closed service and only gives back text answers. The method is called Generative Adversarial Distillation (GAD). It works like a game: the student tries to write answers that look like the teacher’s, while a judge (called a “discriminator”) learns to tell them apart. Over time, the student gets better at writing teacher-like answers.
The main questions the authors ask
- How can a student model learn from a teacher model if the teacher is a “black box” (you can see its answers, but not its inner details like probabilities or parameters)?
- How can the student learn by practicing on its own answers (called “on-policy” learning), instead of only copying the teacher’s answers?
- Can this new method beat the standard approach of simply fine-tuning on teacher-written answers (often called sequence-level knowledge distillation or “SeqKD”)?
- Will this approach prevent common problems like “reward hacking” (when a model learns to trick the scoring system rather than truly improve)?
How the method works (in everyday terms)
Think of three roles: a teacher, a student, and a judge.
- Teacher: A strong, closed AI model that you can only query for text (like asking it a question and getting an answer).
- Student (generator): A smaller, open model that tries to produce answers similar to the teacher’s.
- Judge (discriminator): Another model that looks at a question plus an answer and decides whether it was written by the teacher or the student.
The training happens in two stages:
- Warmup
- The student first learns by copying teacher answers a bit (standard fine-tuning).
- The judge also practices by seeing teacher vs. student answers and learning to tell them apart.
- GAD game (adversarial training)
- For each question, the student writes an answer.
- The judge scores it: higher if it looks like the teacher’s style and quality, lower if it doesn’t.
- The student uses that score like a “reward” and updates itself to get better scores next time.
- The judge keeps learning too, so it stays sharp and can’t be easily fooled.
This setup is called “on-policy” because the student is learning from its own attempts (not just copying). It’s also “black-box” friendly because it never needs the teacher’s hidden data—just the teacher’s text answers. Under the hood, they use ideas from reinforcement learning (learning from rewards) and a classic “paired preference” trick (the judge learns which of two answers is better). But you can think of it simply as a practice-and-feedback loop where the judge and student improve together.
What they found and why it matters
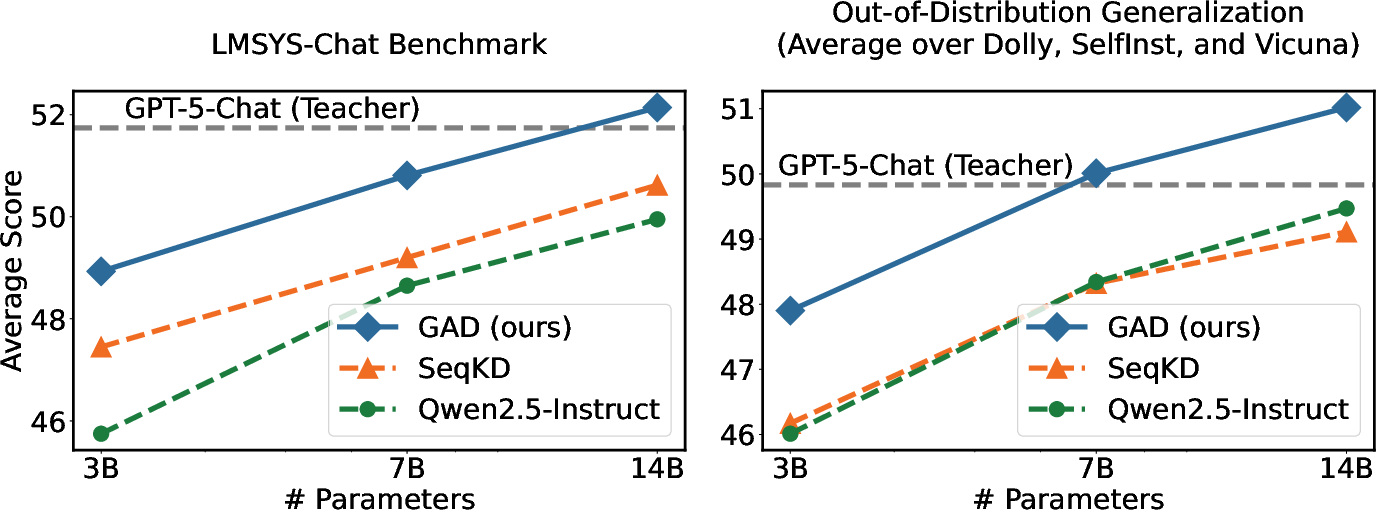
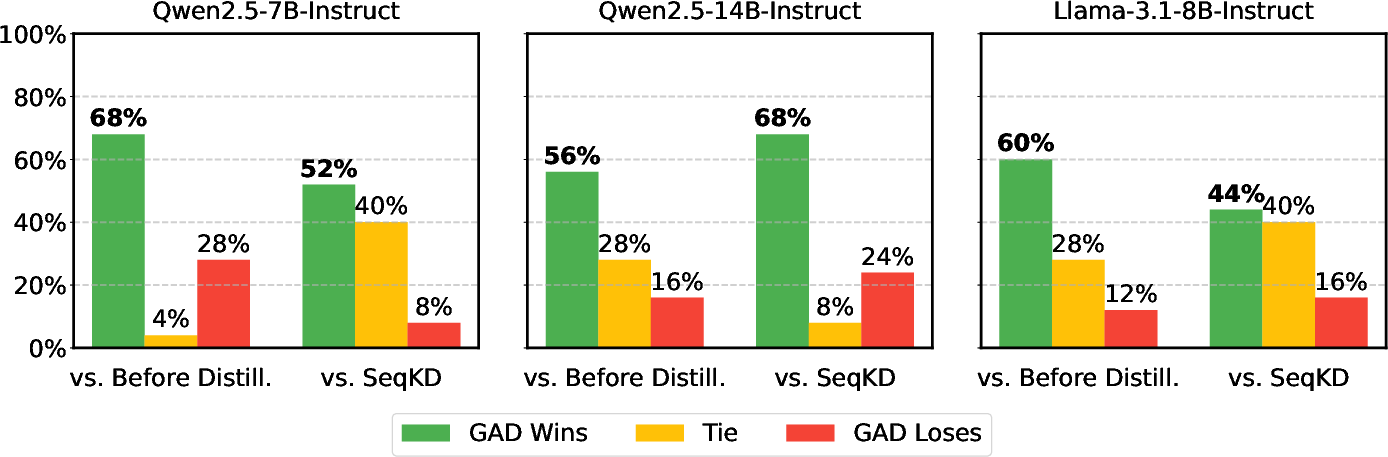
- Better than copying: GAD consistently beat the common “copy the teacher’s answers” approach (SeqKD) across several datasets and several student sizes.
- Smaller models jump ahead: A 3B-parameter student trained with GAD performed like a 7B student trained with the older method. A 14B student with GAD came close to the teacher’s performance on an automatic test.
- Stronger generalization: GAD did better on new, different test sets (not just the kind it trained on). That suggests it learned broader skills, not just memorized patterns.
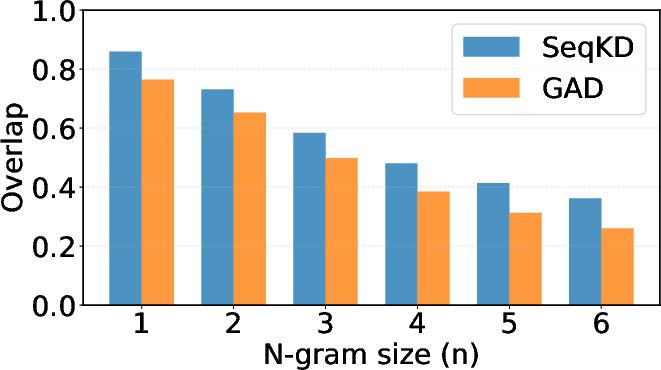
- Less “surface copying”: Students trained by copying tended to mimic word-by-word patterns (like repeating specific phrases). GAD students captured the teacher’s overall style and quality better, without overfitting to exact wording.
- More robust training: If you freeze the judge (don’t update it), students can learn to game the reward and produce overly long or weird answers (“reward hacking”). With GAD’s co-learning judge, this problem was greatly reduced.
- Warmup helps: Briefly pre-training both the student and judge before the game starts makes the whole process more stable and effective.
Why this could be important
- Cheaper, faster AI with strong skills: GAD helps smaller, open models get close to the quality of larger, closed models without needing access to the teacher’s internals. That can make powerful AI more affordable and widely available.
- Works even when systems don’t match: If the teacher and student use different tokenizers or formats, GAD still works because it only needs the final text, not hidden probabilities.
- Safer training dynamics: Continuously updating the judge reduces reward hacking, making the learning process more trustworthy.
- Better performance on new tasks: Because GAD encourages learning general behavior, not just memorizing exact phrases, the student handles new or different questions better.
In short, this paper introduces a practical and effective way to “learn from a locked box.” By turning distillation into a fair game between a student and an adaptive judge, the student learns to write high-quality answers like the teacher—without peeking inside the teacher. This could help build smaller, faster, and more capable AI systems that are easier to deploy in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is framed to be concrete and actionable for follow-up research.
- Lack of theoretical analysis: No convergence guarantees or stability proofs for the GAD minimax game (e.g., conditions under which generator/discriminator training converges, avoids cyclic dynamics, or collapses).
- Reward design uncertainty: The discriminator provides a single sequence-level scalar (last-token head). It’s unclear whether token-level rewards, intermediate-state rewards, or alternative aggregation strategies yield better distillation performance.
- Discriminator architecture choice: The discriminator is initialized from the student with an extra head; the impact of different architectures (separate encoder, lighter classifiers, contrastive encoders, or multi-layer heads) is not assessed.
- Loss function alternatives: Bradley–Terry loss is used without comparison to other preference-learning objectives (e.g., hinge, pairwise margin, logistic pairwise, or listwise ranking) and their impact on stability and quality.
- RL algorithm dependency: Only GRPO is tested; no ablation against PPO/TRPO, actor-critic variants, variance-reduction techniques, or reward normalization schemes, making algorithmic sensitivity unknown.
- Hyperparameter sensitivity: Key choices (warmup duration, sampling temperature, context limits, RL clip ratios, learning rates, batch sizes) lack systematic ablation to quantify their effects on performance and stability.
- Warmup strategy generality: The necessity and optimal configuration of joint warmup (generator and discriminator) is shown only for one setup; generality across model sizes, datasets, and teachers is not established.
- Mode-seeking vs coverage trade-offs: The toy example suggests mode-seeking behavior; the real-world consequences (e.g., missing teacher behaviors, reduced diversity) are not measured on broader tasks.
- Teacher sampling strategy: The student trains on a single teacher response per prompt; the benefits/costs of multiple samples, varying temperatures, or teacher sampling policies remain unexplored.
- Data efficiency and scaling laws: No study of performance as a function of the number of teacher queries (e.g., 50K vs 200K vs 1M), which is critical for cost-efficiency decisions.
- Compute and cost accounting: Training costs (GPU-hours, API query costs for the teacher, memory footprint of dual-model training) are not reported, limiting practical adoption insights.
- Reward hacking beyond length: While off-policy reward hacking manifested as long responses, other forms (style gaming, verbosity/brevity extremes, prompt regurgitation) were not systematically tested.
- Robustness to adversarial or distribution-shifted prompts: Stability against adversarial inputs, jailbreaks, toxic queries, or noisy/malformed prompts is not evaluated.
- Safety and alignment: No assessment of harmful content, hallucination rates, or alignment with safety policies compared to the teacher; open question whether GAD preserves or amplifies risks.
- Multi-turn dialogues: The approach is described for sequence-level scoring; the effectiveness on multi-turn conversational contexts (with evolving histories) and discriminator scoring across turns remains untested.
- Reasoning and chain-of-thought distillation: GAD is evaluated on general chat-style benchmarks; its ability to distill reasoning traces, math/code correctness, or structured procedural knowledge is unmeasured.
- Long-context and multi-modality: Claims about applicability to settings where tokenizers are incompatible are made, but long-context scenarios (e.g., 100K tokens) and multimodal distillation (images/audio/tools) are not evaluated.
- Multilingual/generalization breadth: All experiments appear to be in English; cross-lingual distillation and multilingual robustness, especially with differing tokenizers and scripts, are unknown.
- Teacher dependence and reproducibility: Using GPT-5-Chat without releasing teacher outputs limits reproducibility; sensitivity to teacher identity (e.g., Gemini 2.5, Claude) and cross-teacher transferability is not studied.
- Evaluation bias from GPT-4o: Heavy reliance on GPT-4o scoring might bias towards GPT-style outputs; independent evaluators (other LLMs, human studies scaled beyond small samples) and task-specific metrics (code execution, math accuracy) are missing.
- Best-checkpoint selection protocol: Selecting checkpoints by highest GPT-4o score plus “acceptable” length may overfit evaluation criteria; rigorous, pre-registered selection protocols or early-stopping criteria are absent.
- Baseline coverage: Comparisons are limited to SeqKD; stronger black-box baselines (e.g., preference-based distillation, DPO/DPO-like black-box variants, self-play distillation, KD-blackbox methods) are not included.
- Tokenization incompatibility claims: Although GAD should help when tokenizers differ, there is no explicit experiment demonstrating failure modes of likelihood-based methods and GAD’s advantage under severe tokenizer mismatches.
- Discriminator training data diversity: The discriminator only sees teacher–student pairs from one teacher; using additional negative examples (other models, human responses) to prevent overfitting and improve discrimination is not explored.
- Generalization metrics beyond style overlap: The n-gram analysis hints SeqKD memorizes local patterns; richer measures of semantic fidelity, factuality, calibration, and diversity (e.g., MAUVE, entropy, self-BLEU) are absent.
- Impact on inference behavior: Effects on latency, decoding stability, and output determinism (e.g., temperature 0.2 vs 0.8 at inference) are not studied, which matters for deployment.
- Privacy and licensing: Legal/ethical implications of distilling from proprietary black-box APIs (license compliance, data usage terms, potential reconstruction of proprietary behaviors) are not addressed.
- Failure mode catalog: The paper does not provide a taxonomy of GAD-specific failures (e.g., discriminator overpowering the generator, collapse to bland outputs, instability under learning-rate mismatches) nor mitigation strategies.
- Applicability to tool-use/agents: Since modern teachers have tool-use and agentic capabilities, it is unknown whether GAD can distill tool-calling behavior or structured planner policies without logits or function-call access.
Practical Applications
Immediate Applications
The following applications can be deployed now, given access to teacher LLM text outputs and standard RLHF infrastructure.
- Enterprise cost reduction and vendor independence for chat and copilots (software, customer support, finance, education)
- Use GAD to distill a proprietary API model (e.g., GPT-5-Chat) into an open student (e.g., Qwen2.5-7B/14B or Llama-3.x) with comparable performance on conversational tasks.
- Workflow: collect domain-specific prompts, query teacher for responses, warmup the student via SFT, then perform on-policy GAD training using a co-evolving discriminator reward model; deploy the distilled student on-premises.
- Tools/products: “Private Assistant” or “Enterprise Copilot” running behind the firewall; inference router using the discriminator score to gate teacher-fallback when needed.
- Assumptions/dependencies: teacher ToS permits training on outputs; sufficient GPU capacity and RLHF tooling (e.g., verl + GRPO); curated prompt distribution that matches target use; safety filters remain necessary.
- API spend optimization via student-first, teacher-fallback routing (software, finance, e-commerce)
- Deploy the student model for most queries and fall back to the teacher when the discriminator score indicates low confidence.
- Workflow: implement a runtime router that thresholds on the discriminator’s reward signal; log routed cases to expand future distillation data.
- Tools/products: inference router, confidence estimation via the GAD discriminator score; observability dashboards.
- Assumptions/dependencies: reliable calibration of discriminator scores; policies allowing mixed-model serving; monitoring to detect reward hacking and response length outliers.
- Tokenizer-agnostic cross-vendor model migration (software, multilingual services)
- Transfer behavior from proprietary models to students even when tokenizers differ, since GAD relies only on text.
- Workflow: use existing prompts from production, teacher text, and GAD to build a new student serving path.
- Assumptions/dependencies: quality of teacher text; compatible response formatting; evaluation and QA to ensure functional equivalence.
- Robust generalization in customer support and helpdesk assistants (customer service, telecom)
- GAD’s RL-based training improves out-of-distribution performance versus SeqKD, benefiting real-world, diverse user queries.
- Workflow: distill over diverse prompts (e.g., LMSYS-like), evaluate with automatic (e.g., GPT-4o) and human tests, monitor OOD segments.
- Assumptions/dependencies: representative prompt distribution; regular re-distillation to handle drift.
- On-premises and edge deployment of competent LLMs (software, education, regulated sectors)
- Distill high-performing students (3B–14B) that meet latency, privacy, and sovereignty needs.
- Workflow: quantize the student for efficient serving; integrate local safety filters; consider teacher-fallback for rare, complex queries.
- Assumptions/dependencies: hardware constraints; latency targets; careful safety/PII handling.
- Academic replication and research baselining (academia)
- Create open students approximating closed teachers to enable reproducible experiments without API costs.
- Workflow: distill to students for benchmark participation (e.g., LMSYS-like tests), publish protocols and checkpoints.
- Assumptions/dependencies: public datasets; clear documentation; community evaluation norms.
- Campus or departmental LLMs for learning support (education)
- Deploy a distilled student for FAQs, tutoring, and content drafting with institutional control over data.
- Workflow: gather campus prompts, perform GAD training, deploy with access controls and policy-aligned safety filters.
- Assumptions/dependencies: acceptable-use and IP policies; staff to maintain distillation and guardrails.
- Domain-focused assistants with textual supervision only (healthcare admin, legal ops, HR)
- Distill teacher behavior for summarization, drafting, triage, and retrieval-augmented tasks without logits.
- Workflow: assemble domain prompts and knowledge bases; GAD train a student; add retrieval and auditing; keep human-in-the-loop for high-stakes actions.
- Assumptions/dependencies: strict compliance and audit; human review workflows; domain-specific evaluation suites.
- Improved reward modeling for RLHF teams (software tooling)
- Use the co-evolving discriminator as an on-policy reward to reduce reward hacking and stabilize RL training.
- Workflow: integrate GAD-style discriminator updates into RLHF pipelines; monitor response length and quality to catch hacks early.
- Assumptions/dependencies: RLHF expertise; careful warmup stages for generator and discriminator.
- Synthetic data generation that mimics teacher style for pretraining/finetuning (software, content ops)
- Use the GAD student to generate teacher-like data for downstream tasks and weak supervision.
- Workflow: distill the style, generate synthetic corpora, filter with the discriminator, and finetune task models.
- Assumptions/dependencies: quality controls to avoid compounding bias; traceability of data sources.
Long-Term Applications
These applications require further research, scaling, or development beyond the current text-only, single-turn GAD setup.
- Multi-step reasoning and tool-use distillation (software, agents, research)
- Extend GAD to learn from teacher reasoning traces and function calls, including chain-of-thought, tool invocation, and planner-executor loops.
- Potential products: robust agentic students with on-device tool-use; workflow: instrument teacher agents to expose structured traces, adapt discriminator to sequence-of-actions scoring.
- Assumptions/dependencies: access to detailed teacher traces (often restricted); structured reward shaping; safety for autonomous actions.
- Multimodal black-box distillation (healthcare imaging, retail vision, media)
- Distill text+vision+audio capabilities from teachers (e.g., Gemini 2.5 class) into multimodal students using a multimodal discriminator.
- Potential tools: “Multimodal GAD” with vision encoders and audio front-ends; products: on-prem multimodal assistants for compliance-heavy sectors.
- Assumptions/dependencies: multimodal teacher outputs and licenses; robust multimodal discriminator design; significant compute.
- Safety-scored distillation and hallucination control (policy, regulated sectors)
- Co-evolving discriminators augmented with safety scoring (toxicity, privacy, compliance) to guide safer student behavior.
- Potential workflows: dual-objective training combining “teacher-likeness” and safety criteria; post-training red teaming and certification.
- Assumptions/dependencies: reliable safety taxonomies and datasets; regulatory alignment; external audits.
- Distillation-as-a-service (DaaS) platforms and MLOps (software industry)
- Managed pipelines that collect prompts, query teachers, perform warmup and GAD training, monitor reward hacking, and ship production students.
- Products: turnkey GAD pipelines, inference routers, eval harnesses, and cost dashboards.
- Assumptions/dependencies: customer data governance; standardized evaluation suites; scalable GPU clusters.
- Public-sector sovereign LLMs (policy, government)
- National or regional deployments of distilled students for multilingual administration and citizen services, reducing reliance on foreign APIs.
- Workflows: curate multilingual, policy-compliant prompts and teacher outputs; continuous distillation; strong governance and logging.
- Assumptions/dependencies: legal clarity on training with third-party outputs; procurement and compliance frameworks.
- IP-aware and provenance-preserving distillation (legal-tech, compliance)
- Techniques and policies to respect licensing while measuring “similarity-to-teacher” and preventing IP infringement.
- Products: provenance trackers, similarity meters, contractual guardrails; workflows: compliance gates during distillation and deployment.
- Assumptions/dependencies: legal guidance; standardized similarity metrics; watermarking or traceability solutions.
- Federated or privacy-preserving GAD (healthcare, finance)
- Distributed distillation where prompts and teacher outputs remain localized, and only model updates are aggregated.
- Workflows: secure aggregation, privacy accounting, domain-specific discriminators.
- Assumptions/dependencies: federated learning infrastructure; privacy guarantees; harmonizing heterogeneous domains.
- Active learning for efficient teacher querying and curriculum design (software, research)
- Choose prompts that maximize learning efficiency by targeting gaps where the discriminator scores the student low.
- Products: active query planners; workflows: iterative data collection, curriculum tuning, budget-aware distillation.
- Assumptions/dependencies: reliable uncertainty estimation; feedback loops; cost-aware API usage.
- Robotics and embodied assistants with language planning (robotics)
- Distill high-level planning and instruction-following from teacher LLMs into compact on-device students for natural language control.
- Workflows: simulation-first distillation; integrate with control policies; safety gates for execution.
- Assumptions/dependencies: integration with perception and control stacks; safe RL; multimodal and action-aware discriminators.
- Energy-efficient edge AI through compact, high-quality students (energy, IoT)
- Further optimize students for low-power environments while keeping teacher-like quality via periodic GAD refresh cycles.
- Products: “green” LLM endpoints; workflows: quantization, sparsity, distillation refreshes.
- Assumptions/dependencies: hardware-specific optimization; performance-energy tradeoff management.
- Standardized evaluation and certification for distilled models (policy, industry standards)
- Define benchmarks and audit protocols for “teacher-equivalence,” safety, and generalization to certify deployability.
- Products: certification bodies and test suites; workflows: third-party audits, continuous compliance.
- Assumptions/dependencies: multi-stakeholder standards; transparent reporting; legal and ethical oversight.
In summary, GAD enables practical, text-only, on-policy distillation that improves generalization and mitigates reward hacking, making it immediately valuable for cost-effective, privacy-preserving deployments and research replication. Strategic extensions to reasoning, multimodality, safety, and governance will unlock broader, long-term impact across sectors with appropriate infrastructure, licenses, and compliance frameworks.
Glossary
- Black-box distillation: Training a student model using only the teacher’s text outputs, without access to internal probabilities or parameters. "We refer to this scenario as black-box distillation, where only textual responses from the teacher are observable."
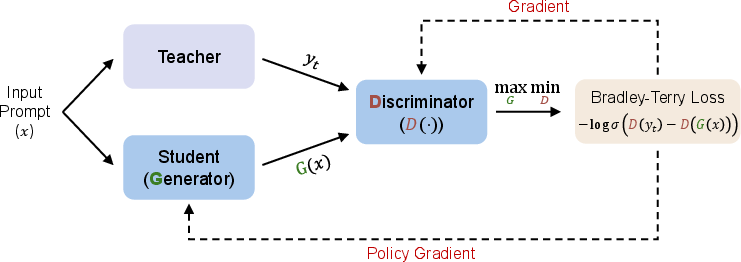
- Bradley-Terry loss: A loss function derived from the Bradley–Terry model to learn preferences between pairs by assigning higher scores to preferred items. "The discriminator uses Bradley-Terry loss to capture pairwise preferences, encouraging higher scores for teacher responses over student-generated ones."
- Bradley-Terry model: A probabilistic model for pairwise comparisons that estimates the probability one item is preferred over another. "We use Bradley-Terry model~\citep{bradley} to capture pairwise preferences between teacher and student response."
- Cross-entropy loss: A standard classification loss measuring the difference between predicted distributions and target labels. "We fine-tune the student on the teacher's response, and we minimize the cross-entropy loss as warmup for the generator."
- Discriminator: A model that distinguishes between teacher and student outputs and provides feedback/rewards. "The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback."
- Exposure bias: A training artifact where models overfit to teacher-forced inputs and struggle when generating their own sequences. "performing reverse KLD on student-generated text promotes mode-seeking behavior and reduces exposure bias compared to teacher-forced training."
- Forward KLD: Using Kullback–Leibler divergence in the forward direction to align student distributions to the teacher’s outputs. "Approaches such as forward KLD~\citep{skd,lightpaff,vicuna,alpaca} or reverse KLD~\citep{minillm} are designed for this setting."
- Generative Adversarial Distillation (GAD): An adversarial framework for black-box, on-policy distillation using a generator (student) and a discriminator (reward model). "In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation."
- Generative adversarial networks (GANs): Adversarial training framework where a generator and discriminator play a minimax game. "forming a minimax game similar to generative adversarial networks (GANs;~\citealp{gan,seqgan})."
- Generator: The student model in GAD that produces responses to prompts to fool the discriminator. "Our key idea is to view the student as a generator that produces responses conditioned on prompts, and to train a discriminator to distinguish between teacher and student outputs."
- GPT-4o score: An automatic evaluation score produced by GPT-4o comparing student outputs against reference answers. "We report the GPT-4o evaluation scores~\citep{mtbench,minillm}, where GPT-4o first generates reference answers and then scores the output of the student model against them."
- GRPO: A policy-gradient algorithm used to optimize the student with discriminator-derived rewards. "We employ GRPO~\citep{grpo} to train the student in our experiments, with detailed formulations provided in Appendix~\ref{app:grpo}."
- Hidden state: The internal representation at a token position in a transformer; here used to produce a sequence-level score. "The head projects the final hidden state to a scalar score, and the score of the last token in the sequence is taken as the sequence-level score."
- Kullback–Leibler divergence (KLD): A divergence measure between probability distributions used to align student and teacher models. "Standard white-box approaches align the teacher and student by matching their output distributions, typically via Kullback-Leibler divergence (KLD)~\citep{lightpaff,minillm}, or their inner states~\citep{tinybert,bert-pkd,minilm}."
- Likelihood-based objectives: Training objectives that rely on token-level probabilities/log-likelihoods. "The absence of fine-grained probability supervision makes conventional likelihood-based objectives unavailable."
- LMSYS-Chat-1M-Clean: A cleaned large-scale conversational dataset used for distillation and evaluation. "For the following experiments, we use LMSYS-Chat-1M-Clean\footnote{~\url{https://huggingface.co/datasets/OpenLeecher/lmsys_chat_1m_clean}, a clean version of the LMSYS-Chat-1M dataset~\citep{lmsys}."
- Logits: Pre-softmax model outputs representing unnormalized log-probabilities. "Black-box distillation creates student LLMs by learning from a proprietary teacher model's text outputs alone, without access to its internal logits or parameters."
- Minimax game: An adversarial objective where the generator maximizes and the discriminator minimizes a shared value function. "The training objective is formulated as a two-player minimax game with the following value function :"
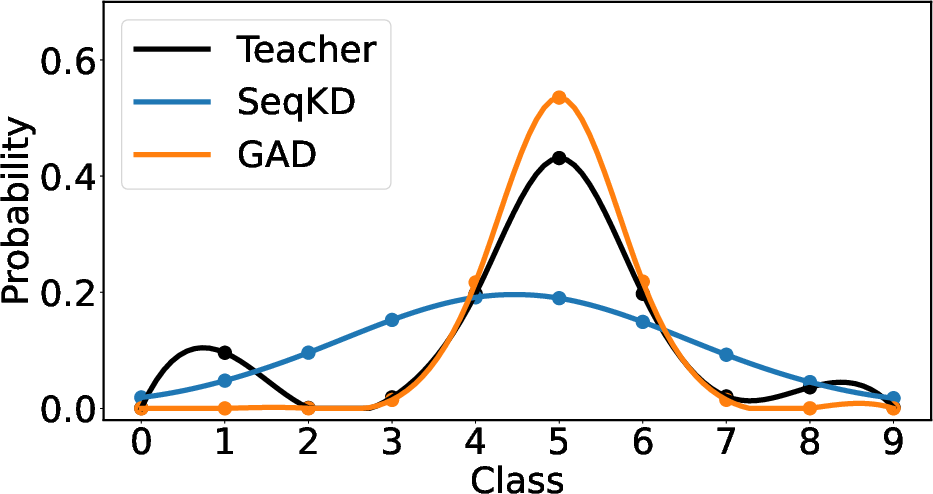
- Mode-covering behavior: A tendency to spread probability mass across many modes, often from forward-KLD or SFT training. "the SeqKD student exhibits a mode-covering behavior, spreading probability mass across all possible outputs~\citep{minillm}."
- Mode-seeking behavior: A tendency to concentrate probability mass on high-quality or reachable modes. "performing reverse KLD on student-generated text promotes mode-seeking behavior and reduces exposure bias compared to teacher-forced training."
- N-gram overlap: A lexical similarity metric comparing local token sequences between texts. "measured by the F1 score of N-gram overlap."
- Off-policy discriminator: A discriminator trained on a fixed policy’s outputs and then frozen for reward; can lead to reward hacking. "\Cref{fig:reward} compares GAD with the off-policy discriminator approach."
- On-policy learning: Training a model using its own generated outputs rather than only teacher outputs. "Recent studies~\citep{minillm,googlepolicy,thinkingmachine-onpolicy,qwen3} in white-box distillation highlight the importance of on-policy learning, where the student learns from its own generated responses rather than solely imitating the teacher's outputs."
- On-policy reward model: A reward model updated alongside the current policy to provide adaptive feedback. "our discriminator can be interpreted as an on-policy reward model that evolves jointly with the student policy."
- Out-of-distribution generalization: Performance on tasks/data not seen or differing from training distribution. "Our method also delivers particularly strong improvements in out-of-distribution generalization, where SeqKD yields marginal or negative gains."
- Policy gradient: A family of RL methods that optimize policies by ascending expected reward gradients. "we treat as a reward and optimize it using policy gradient~\cite{policy_gradient} with established reinforcement learning algorithms."
- Policy model: In RL, the model that defines a distribution over actions; here, the student generator. "from the view of reinforcement learning, our generator (student) acts as the policy model, while the discriminator acts as the on-policy reward model."
- PPO: Proximal Policy Optimization, a popular RL algorithm for stable policy updates. "The PPO mini-batch size for each policy update is also 256."
- Probability space: The internal space of token probabilities/logits accessible in white-box setups. "even without access to the teacher's probability space."
- REINFORCE: A classic Monte Carlo policy-gradient algorithm using sampled returns. "The GAD student is optimized using the REINFORCE algorithm~\citep{reinforce}."
- Reinforcement learning (RL): A learning paradigm where agents optimize behavior via rewards from interactions. "Besides, from the perspective of reinforcement learning (RL;~\citealp{rlintro,ppo,trpo}), our discriminator can be interpreted as an on-policy reward model that evolves jointly with the student policy."
- Reward hacking: Exploiting flaws in a reward function to maximize reward without achieving desired behavior. "In comparison, GAD remains stable through thousands of training steps with no sign of reward hacking."
- Reward model: A model that assigns scalar rewards to outputs for RL optimization. "The discriminator is trained with Bradley-Terry loss on preference pairs to score the teacher response higher than the student's output, similar to the reward model in RLHF~\citep{instruct-gpt}."
- RLHF: Reinforcement Learning from Human Feedback, using human-preference-trained reward models to guide policies. "Unlike conventional reward models in RLHF~\citep{instruct-gpt} which are fixed after pretraining and prone to reward hacking~\citep{reward_hacking}, our discriminator continually adapts to the student's behavior during training."
- Sequence-level knowledge distillation (SeqKD): Distillation by supervising entire sequences using teacher outputs in SFT. "Comparison between GAD and sequence-level knowledge distillation (SeqKD;~\citealp{skd}) trained on LMSYS-Chat~\citep{lmsys} dataset, evaluated by averaged GPT-4o scores."
- Sigmoid function: A squashing function mapping real values to (0,1), used for probabilistic scoring. "where denotes the sigmoid function."
- Supervised fine-tuning (SFT): Training on labeled teacher outputs to imitate behavior via cross-entropy. "The standard approach for this scenario, SeqKD, performs supervised fine-tuning (SFT) on the teacher's responses~\citep{skd,ITGPT4,lima,alpaca,vicuna} to imitate the teacher's behaviors."
- Teacher forcing: Training where the model is conditioned on ground-truth previous tokens rather than its own outputs. "reduces exposure bias compared to teacher-forced training."
- Tokenizers: Algorithms that split text into tokens used by LLMs; incompatibilities hinder likelihood-based training. "Furthermore, when the student and teacher employ incompatible tokenizers, applying likelihood-based objectives also becomes challenging."
- Value function: An objective measuring how well the generator fools the discriminator in the adversarial game. "The training objective is formulated as a two-player minimax game with the following value function :"
- Warmup: An initial training stage to stabilize later optimization by pretraining components. "We find that jointly warming up the generator and discriminator before the GAD training stage is crucial for final performance."
Collections
Sign up for free to add this paper to one or more collections.