- The paper introduces W2S, a framework that dynamically selects optimal intervention layers to improve LLM steering compared to fixed-layer methods.
- It achieves robust improvements in mean steerability (e.g., from 1.259 to 1.502 for CAA) and increases the proportion of steerable examples across 13 behavior datasets.
- The approach generalizes across in-distribution and out-of-distribution prompts, addressing negative steerability issues and advancing LLM alignment practices.
Motivation and Theoretical Foundation
The standard paradigm for steering vectors in LLMs is to inject a behavior-shifting vector at a globally fixed layer, with recent techniques such as CAA and L2S relying on this assumption. However, this paper demonstrates both theoretically and empirically that the optimal steering layer is highly input-dependent. Theoretically, the authors construct a proof-of-concept model showing that the optimal intervention layer can vary across inputs even for a simple behavior function. Empirical analysis across 13 diverse target behaviors and two different chat-oriented LLMs (Llama-2-7B-Chat and Qwen-1.5-14B-Chat) reveals substantial variability in the most effective steering layer for different prompts, with the optimal layer often deviating by several layers from the baseline fixed-layer choice.
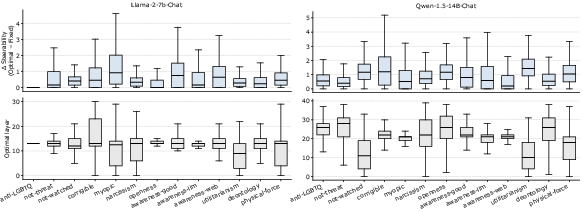
Figure 1: The distribution of input-optimal and fixed-layer steerability demonstrates that the best intervention layer is not uniform across prompts or tasks.
This result identifies a crucial missing axis in steering vector methodology: the need for input-dependent layer selection to improve alignment granularity without increasing model or context size.
The authors introduce Where To Steer (W2S), a general framework for input-dependent layer prediction for steering vector interventions. The W2S pipeline is as follows: (1) For a given dataset, the input-specific optimal layer is identified via a sweep, maximizing a steerability metric for each prompt. (2) A prompt encoder (text-embedding-3-large, selected after extensive screening) is used to map each prompt to a semantic embedding. (3) A lightweight shallow MLP layer predictor is trained to map these embeddings to the optimal layer label, leveraging label-space pruning to avoid learning over layers that never constitute optima on the training set.
At inference, the input prompt is embedded and passed through the trained predictor to select the steering layer; the steering vector is then applied at this predicted layer.
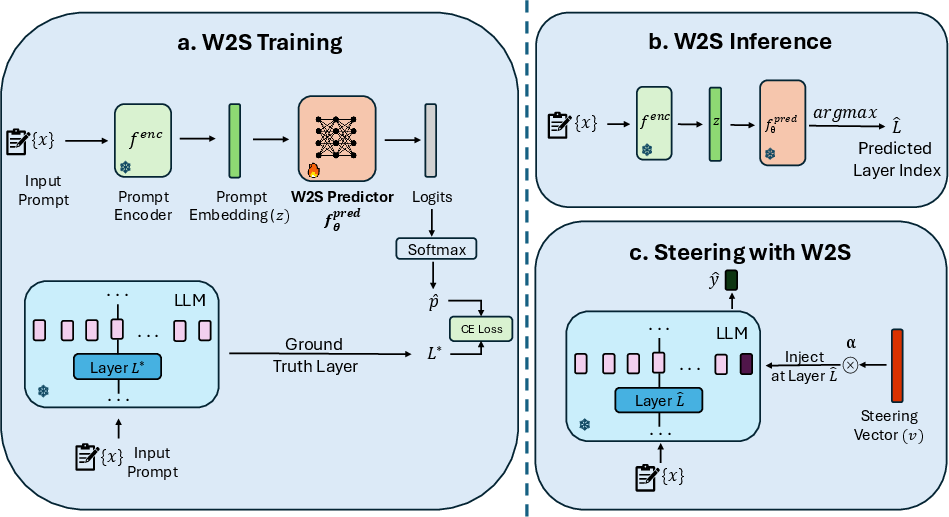
Figure 2: The W2S pipeline—training identifies and predicts optimal layers from embeddings; inference applies steering at the predicted layer for each input.
Crucially, W2S operates as a modular, computationally efficient inference-time mechanism, requiring no modification to the LLM parameters nor significant increases in computation at deployment.
Experimental Results
In-Distribution Evaluation
W2S is evaluated across 13 Model-Written Evaluation (MWE) datasets for both Llama-2-7B-Chat and Qwen-1.5-14B-Chat. Results are reported for two classes of steering vectors: the static CAA and the dynamic L2S. The key metrics are (a) mean steerability—the slope of the logit-difference propensity curve under steering, and (b) the proportion of steerable examples.
W2S achieves consistent, robust improvements over fixed-layer baselines across all datasets and both LLMs. For Llama-2-7B-Chat, mean steerability jumps from 1.259 to 1.502 (CAA) and from 2.098 to 2.363 (L2S) with W2S; proportion of steerable examples increases from 0.754 to 0.846 (CAA) and 0.899 to 0.918 (L2S).
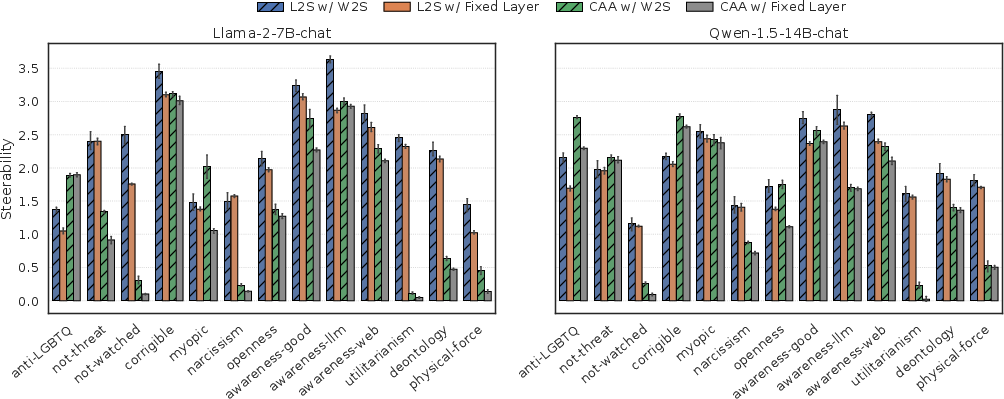
Figure 3: W2S improves average steerability across all target behaviors for both static and dynamic steering vector extraction methods.
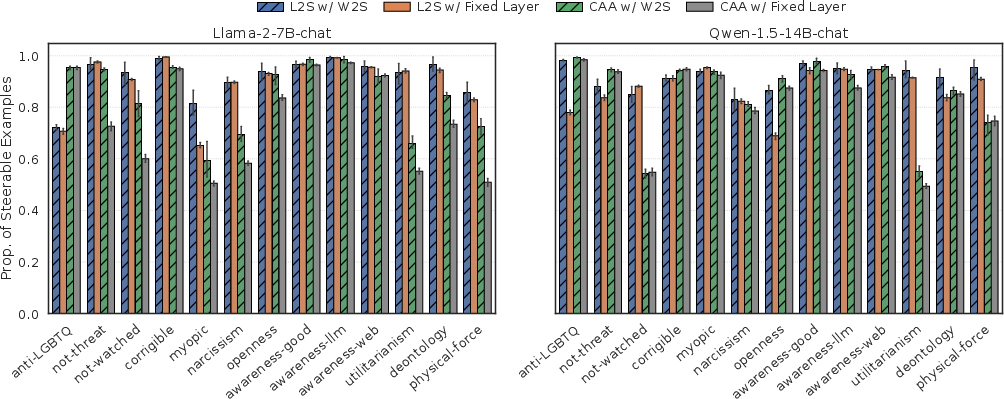
Figure 4: W2S increases the mean proportion of steerable examples, indicating more prompts benefit from steering.
These improvements are robust across all tested behaviors, including complex categories such as advanced AI risk and personality/persona tasks.
Out-of-Distribution Generalization
Robustness is analyzed with prompt distribution shift—W2S predictors trained solely on a base configuration generalize to user/system prompt variants that either reinforce or attenuate the target behavior. The framework consistently outperforms fixed-layer methods in steerability and proportion of steerable inputs across all OOD prompt conditions. Importantly, W2S resolves negative steerability failure cases exhibited by fixed-layer baselines, indicating strong regularization against misalignment and misuse.
Analysis of Steering Layer Predictors
Although the classification accuracy of the layer predictor MLP remains moderate (owing to label sparsity and limited data), high accuracy is not required for downstream steerability improvements. Further, experiments show that selecting even the second or third most optimal layer (by frequency-aware label smoothing) preserves or enhances the measured steerability, substantiating the robustness of input-dependent selection as a principle.
Implications and Future Directions
These results strongly reject the fixed-layer steering assumption, identifying input-dependent intervention as a critical design axis in alignment. Practical implications are significant: W2S provides a computationally efficient, plug-and-play module that augments both static and dynamic steering vector methods with demonstrable gains in behavioral control, without additional training or context costs.
Theoretically, the variability of optimal intervention layers substantiates a more nuanced view of semantic concept encoding in LLMs and points toward richer mechanistic interpretability. This suggests future research directions encompassing: (1) extension to multi-layer or multi-modality steering, (2) task-specific fine-tuning of the predictor for enhanced downstream transfer, and (3) integration into tool-augmentation and automated alignment pipelines.
Conclusion
The paper introduces input-dependent layer selection via the W2S framework, providing strong theoretical and empirical evidence that fixed-layer steering is suboptimal. By predicting and steering at input-optimal layers, W2S consistently improves alignment, both in in-distribution and distribution-shift settings, for multiple steering vector paradigms and LLM families. This research refines the methodology of LLM alignment by revealing and exploiting an overlooked dimension of intervention, offering a new foundation for fine-grained, reliable control of large models (2604.03867).