- The paper demonstrates that context engineering, especially recency-based (Last-K), significantly enhances ADR generation fidelity over baseline approaches.
- The methodology leverages a dataset of 4,500 records from 750 repositories and uses metrics such as BERTScore to compare LLM strategies.
- Results indicate that optimized context windows deliver near-optimal performance with reduced computational overhead, emphasizing documentation hygiene.
Authoritative Essay: Evaluating Context Strategies for Automated ADR Generation Using LLMs
Introduction
The necessity to capture architectural decision rationale through Architecture Decision Records (ADRs) has become central to sustainable software engineering, serving as a lightweight yet highly functional approach to Architectural Knowledge Management (AKM). The manual authoring of ADRs, however, is subject to incentive misalignment and frequently results in incomplete or outdated records, propagating documentation debt and hindering architectural traceability. This study investigates the potential of LLMs to automate ADR creation, emphasizing the critical impact of context engineering—specifically, strategies for selecting historical ADRs as prompt context—on generation fidelity.
Empirical Methodology
A curated and chronologically validated ADR dataset, drawn from 750 open-source repositories and comprising over 4,500 sequential records, forms the experimental foundation. Rigorous manual filtering ensured structural integrity and minimized artifact noise, establishing a simulation of realistic architectural evolution. The evaluation deploys multiple LLMs representing a spectrum of computational scale, accessibility, and underlying architecture: Gemini-2.5-Pro (proprietary SOTA), Qwen3-235B-A22B-Instruct, GLM-4.6, and Gemma-3-4B-it.
The study systematically investigates five context provisioning strategies:
- Baseline: No context, only the ADR title as a prompt.
- All-history: Full chronological context of all prior ADRs.
- First-K: Foundational early decisions.
- Last-K: Recent decisions, for recency emphasis.
- RAFG: Retrieval-Augmented Few-shot Generation, dynamically selecting semantically relevant prior ADRs through dense embedding similarity.
A comprehensive suite of evaluation metrics—BERTScore, BLEU, ROUGE, METEOR, token statistics—benchmark generated ADRs against human-authored ground truth.
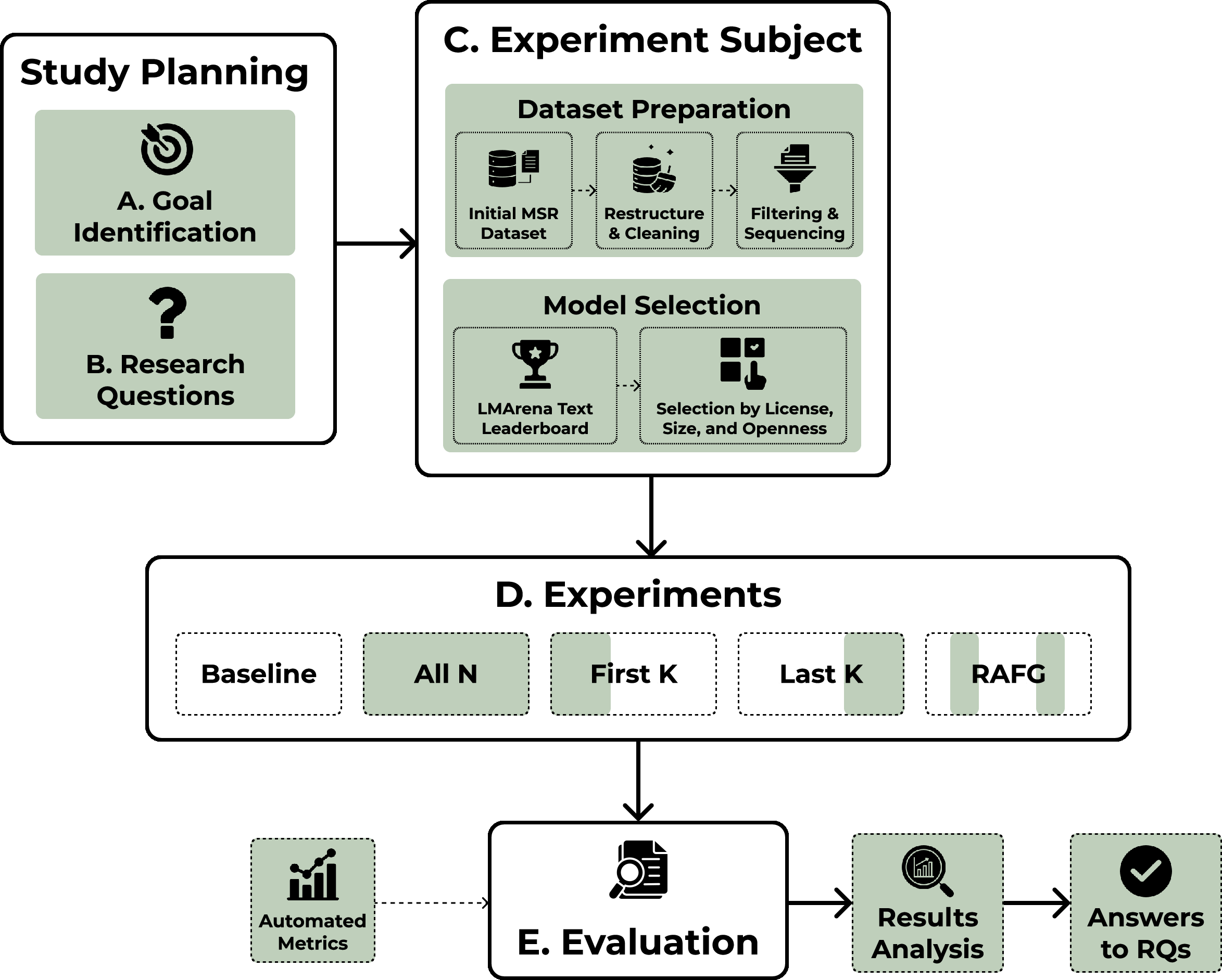
Figure 1: Study Design showing dataset curation, model selection, and evaluation workflow.
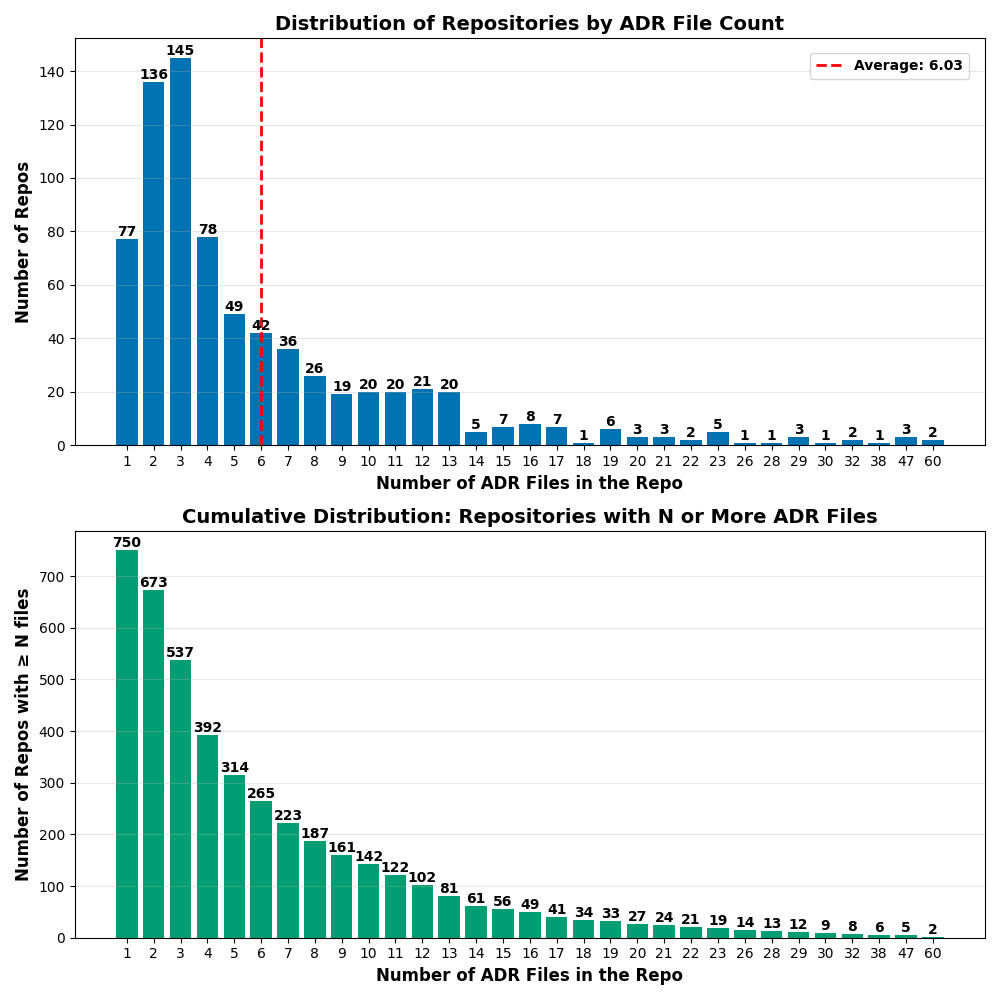
Figure 2: ADR Frequency Distribution revealing strong right-skew—majority of repositories contain 1-4 ADRs, only a minority maintain extensive decision histories.
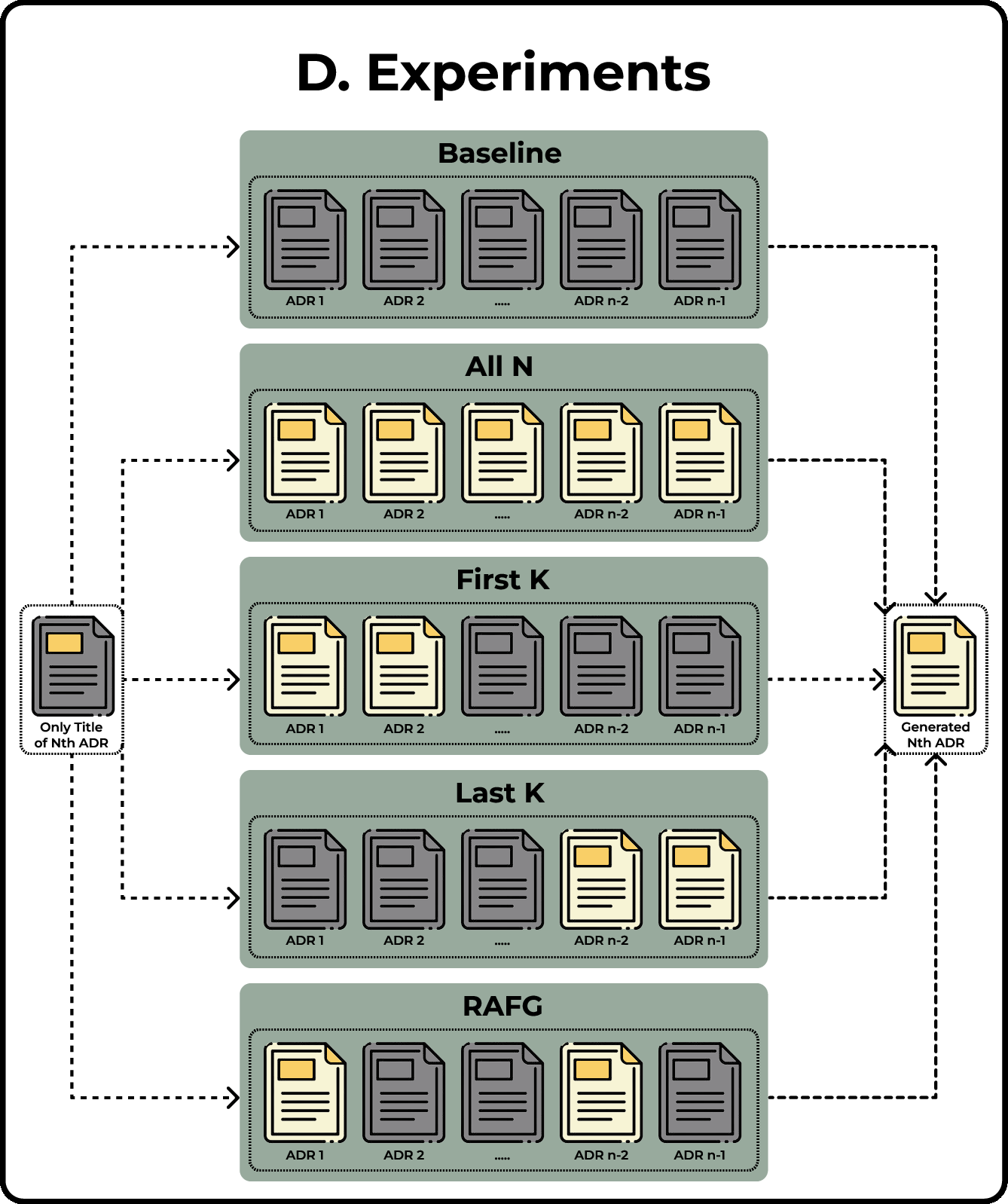
Figure 3: Visual illustration of Baseline, All-history, First-K, Last-K, and RAFG context strategies.
Empirical Results
Context-aware prompting yields substantial gains in ADR generation fidelity, with recency-based strategies (Last-K) providing the optimal balance between quality and computational efficiency. The no-context baseline consistently underperforms, producing verbose and generic outputs that deviate from the concise, rationale-focused human-authored ADRs.
Selective context windows, specifically Last-K (3–5 records), demonstrate near-optimal performance, with aggregate metrics (e.g., Gemini-2.5-Pro BERTScore F1 of 0.8440 with Last-K(3)) indistinguishable from exhaustive All-history strategies. RAFG achieves competitive outcomes, but its primary advantage is observed in non-sequential, cross-cutting decision scenarios demanding conceptual locality over temporal proximity. First-K, while outperforming baseline, is consistently inferior to Last-K and RAFG, indicating foundational decisions are less pertinent to current architectural tasks.
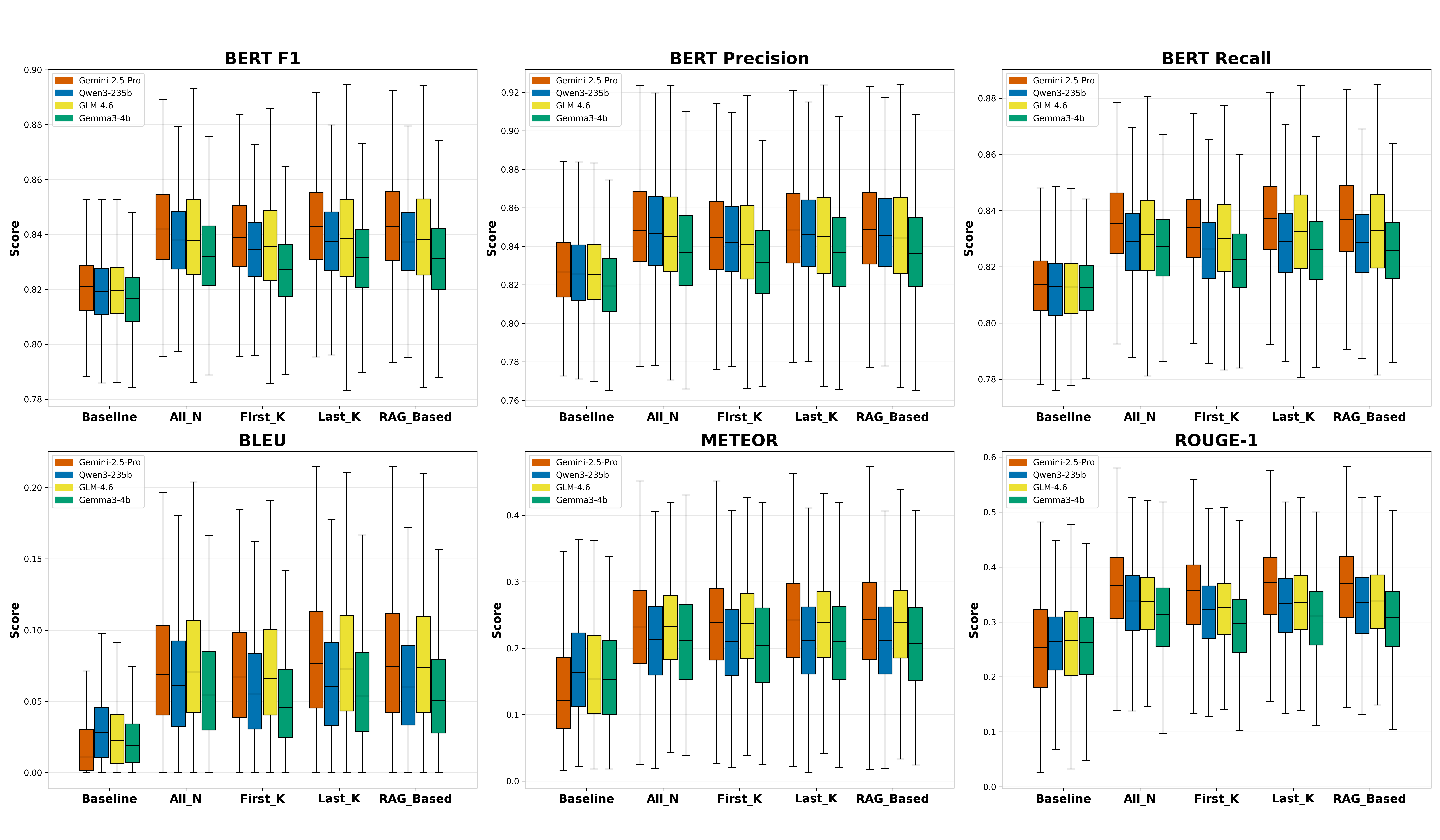
Figure 4: Comparison of model performance across context strategies (K=3); Last-K and RAFG show performance parity and significant improvement versus baseline and First-K.
Longitudinal analysis reinforces the principle of diminishing returns—generation quality plateaus beyond a modest context window. Additionally, context-aware strategies produce output token distributions congruent with ground truth, while baseline approaches result in uniformly verbose, less specialized text.
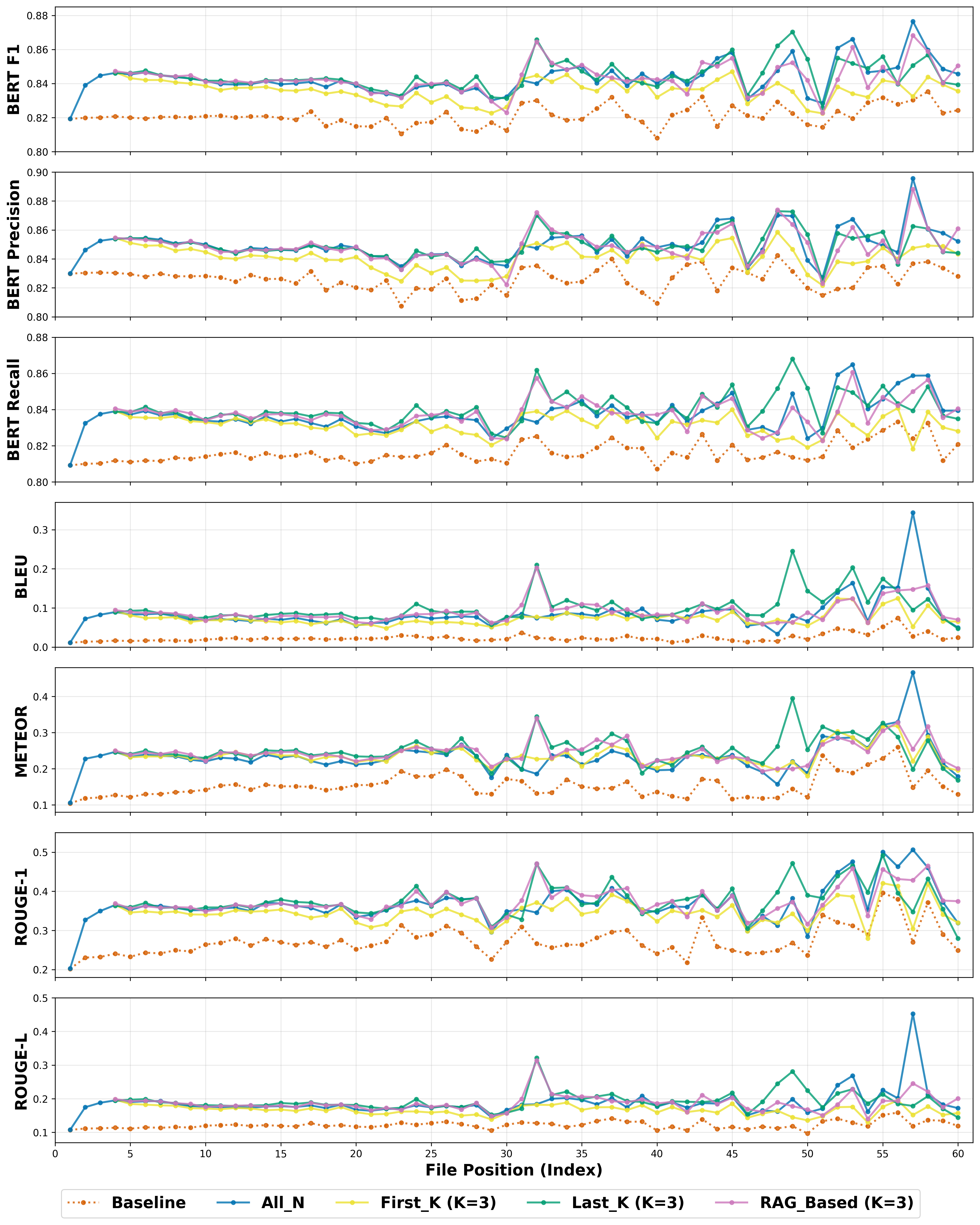
Figure 5: Longitudinal analysis of generation fidelity across ADR positions; context-aware strategies maintain high fidelity throughout repository evolution, baseline remains suboptimal.
Discussion
Interpretation
The study evidences that context selection—not model scale—is the dominant factor in ADR generation quality. Temporal locality dominates most architectural decision workflows, with immediate predecessors being highly predictive of rationale. However, conceptual locality, as provided via RAFG, is vital for decisions traversing boundaries or revisiting dormant patterns. Failures in generation fidelity are frequently attributable to poor documentation hygiene (external references, knowledge vaporization) in ground truth, not model inadequacies.
Implications
For practitioners, recency-based context selection (Last-K) affords a pragmatic, low-complexity default, enabling deployment with compact, locally executable models. Maintenance of self-contained ADRs is essential for both automated tools and human comprehension. For researchers, future directions include adaptive, hybrid context strategies based on decision scope, graph-based dependency modeling, and integration of code artifacts to enable bi-directional traceability. Improved, self-contained datasets are imperative for robust evaluation.
Strong Numerical Results and Claims
- Context-aware prompting improves BERTScore, BLEU, ROUGE, METEOR metrics across all models over baseline.
- Last-K (3–5) achieves performance indistinguishable from All-history, but with significantly reduced token usage and computational overhead.
- RAFG outperforms chronological strategies in cross-cutting, conceptually distant scenarios but offers no statistically significant advantage in linear, temporally dependent workflows.
Contradictory Claims
- Retrieval-based strategies (RAFG) frequently show only marginal gains, contradicting assumptions that semantic augmentation universally outperforms recency-based heuristics.
- Model scale is less critical than context selection—well-contextualized lightweight models rival large proprietary counterparts.
Conclusion
This study establishes that context engineering, particularly recency-based prompt selection, is pivotal for effective ADR automation with LLMs. Exhaustive history yields negligible gains over optimized context windows, and retrieval augmentation is specialized rather than universally advantageous. These results shift optimization from model scale to context strategy, informing practical defaults for tool builders and highlighting the necessity for documentation hygiene. Future research should target hybrid adaptive strategies, deeper integration with implementation artifacts, and curated datasets facilitating precise evaluation. The practical implication is that organizations can confidently deploy local, cost-effective LLMs for ADR automation provided rigorous context selection and robust documentation practices are maintained.