- The paper presents a novel evaluation method that integrates fuzzy AHP with a DualJudge hybrid framework to improve scoring accuracy for less capable LLMs.
- It decomposes complex judgments into multi-criteria pairwise comparisons using both crisp and fuzzy scales, enhancing reliability in logic-intensive tasks.
- Empirical results show that the hybrid approach delivers significant accuracy improvements over direct scoring, particularly in challenging evaluation scenarios.
Structured Multi-Criteria LLM Evaluation with Fuzzy Analytic Hierarchy Process and DualJudge
Introduction
The evaluation of LLMs remains a significant methodological bottleneck, particularly as LLM-based judges supplant human annotators in both research and industrial quality control. Existing approaches are typically partitioned into direct (holistic) scoring—where LLMs produce a singular, intuitive preference—and structured multi-criteria decision-making (MCDM) frameworks. The investigated work proposes a hierarchical, uncertainty-aware evaluation pipeline, adapting the Analytic Hierarchy Process (AHP) and introducing an LLM-configured fuzzy variant (FAHP), culminating with a hybrid fusion strategy named DualJudge. Systematic experiments on the JudgeBench benchmark demonstrate the superiority of this structured, uncertainty-aware, and adaptive pipeline, especially when deployed with less capable evaluators and in logic-intensive domains.
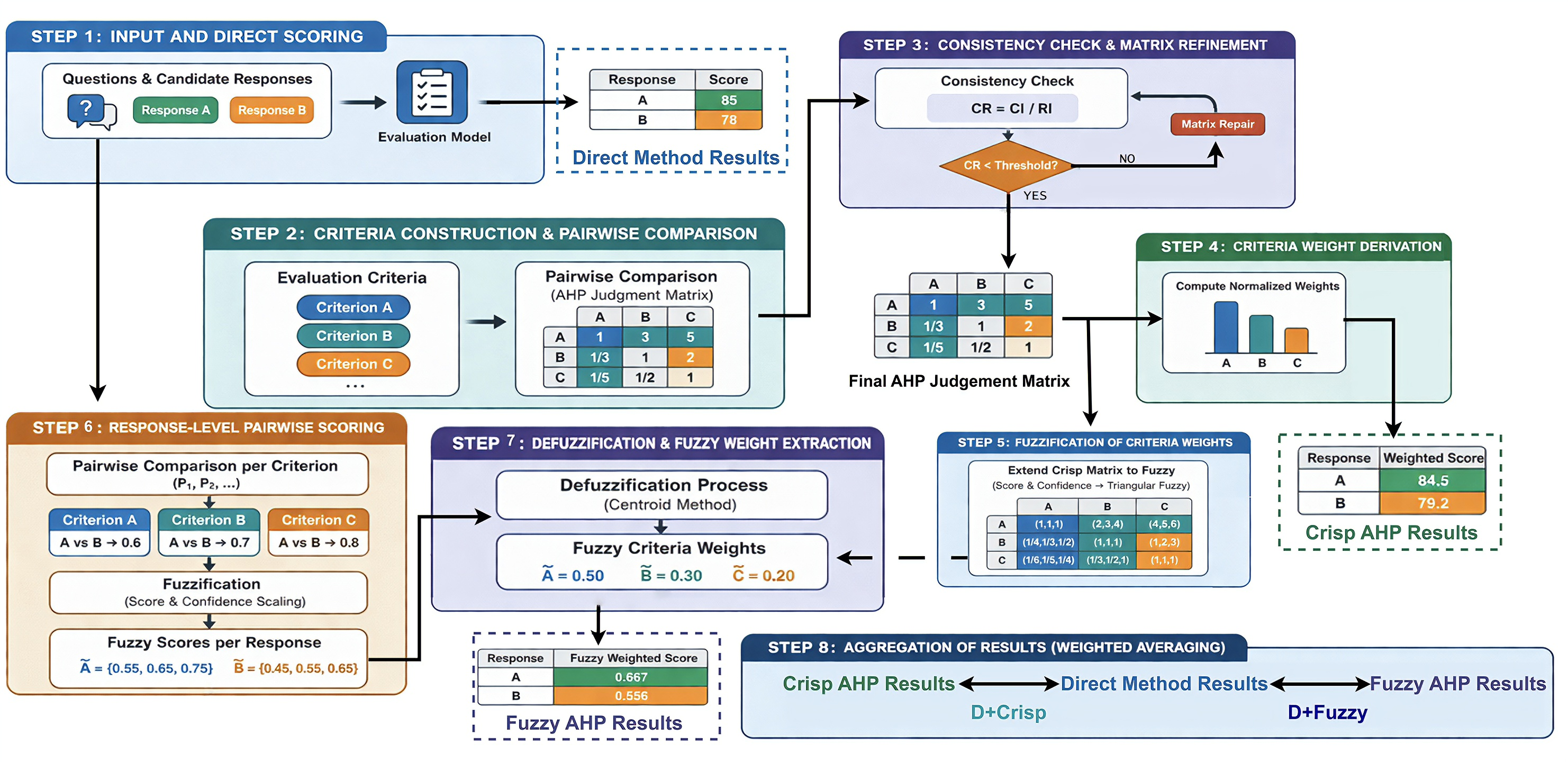
Figure 1: Overview of the proposed hybrid AHP-based evaluation framework, integrating direct scoring, crisp AHP, and fuzzy AHP via consistency checking, weight derivation, and adaptive aggregation.
Methodological Framework
JudgeBench Evaluation Protocol
The empirical platform, JudgeBench, provides challenging pairwise comparison tasks spanning 17 categories (STEM to humanities) and two response splits (GPT-class, Claude-class). Each query contains two model outputs of minimal quality disparity alongside reference preferences, enforcing fine-grained, attribute-based judgment.
Analytic Hierarchy Process (AHP) for LLM Judgment
AHP is deployed to decompose complex judgment tasks into explicit criteria and aggregate them using pairwise comparisons, translated into Saaty’s 1–9 scale and organized as reciprocal matrices. Consistency is ensured via the consistency ratio (CR), with automatic repair procedures for inconsistent matrices. The resulting principal eigenvector provides interpretable criterion weights for final score computation.
Fuzzy Analytic Hierarchy Process (FAHP)
Recognizing the epistemic uncertainty inherent in LLM outputs, this work employs triangular fuzzy numbers (TFNs) as pairwise comparison scores, modulated dynamically by LLM-generated confidence metrics. The fuzzy representation enables direct modeling of ambiguity, and subsequent weight derivations proceed via the geometric mean method and centroid defuzzification:
- Confidence modulation: Defined by γij, constricting the TFN as confidence increases.
- Reciprocity: All fuzzy matrices respect multiplicative inverse symmetry.
This mechanism creates a continuous, uncertainty-aware alternative to rigid discrete scoring in classic AHP.
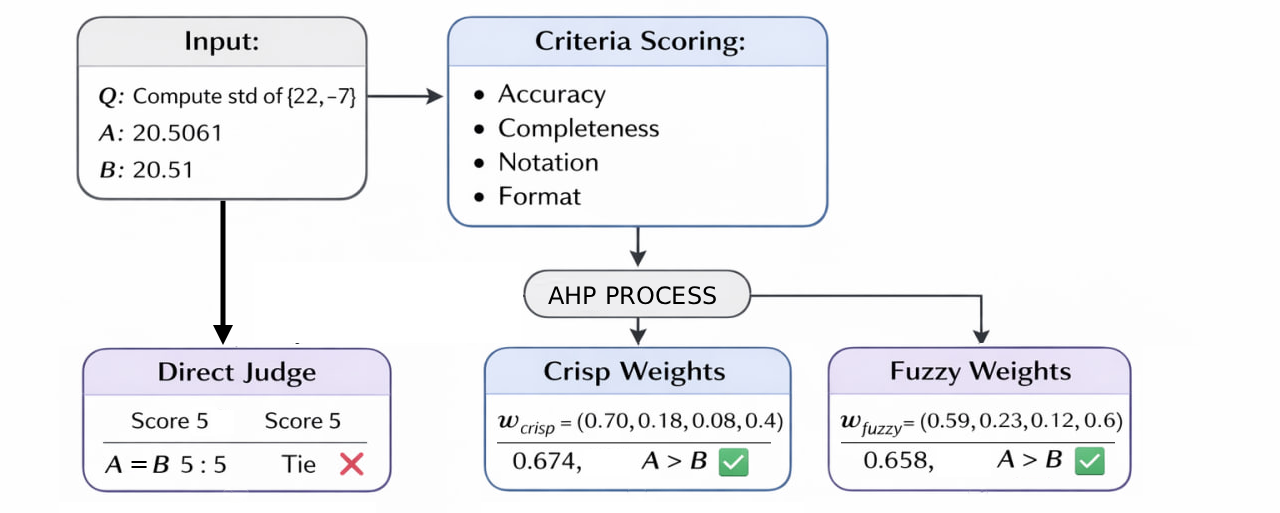
Figure 2: Illustration where holistic direct scoring produces a tie, but both crisp and fuzzy AHP favor Response A, highlighting the benefit of explicit multi-criteria decomposition.
DualJudge Hybrid Fusion
DualJudge integrates direct (holistic) and structured (AHP/FAHP-based) assessments using a CR-based adaptive weighting. The design is inspired by dual-process theories from cognitive science:
- Scoring branches: Sabs (absolute) and Sahp (structured).
- Fusion weight: α(CR)=exp(−βCR), with β=7.
- Final score: Sfinal=α(CR)Sahp+(1−α(CR))Sabs.
Structured scores are suppressed if judged inconsistent, enabling context-sensitive reliance on decompositional versus holistic judgment. This mechanism realizes adaptive trust in AHP depending on the reliability of the underlying pairwise comparisons.
Empirical Results
Across two LLM families (gpt-oss, Qwen3.5), two model scales, and two scoring granularities (1–10, 1–5), structured methods (AHP/FAHP) consistently exceed direct scoring accuracy, particularly for weaker backbones. For instance, gpt-oss-20b achieves +5.5–6.6 percentage points with FAHP, while DualJudge hybridization peaks at a +7.77 point improvement in the 1–10 setting. The trend is inverted or neutral for strong evaluators (Qwen3.5-35B), indicating diminishing returns as models become more reliable.
FAHP almost always outperforms Crisp AHP, highlighting the empirical value of explicit uncertainty modeling—especially for mid-tier and less stable models—manifesting up to +2 percentage points gain over Crisp AHP. Notably, for harder response splits (Claude-class), DualJudge delivers robust and often maximal accuracy in nearly all conditions.
Task and Scale Sensitivity
The 1–5 scale typically yields slightly higher accuracy, likely due to lower granularity burden. The largest structured-evaluation gains are isolated in logic-intensive domains—mathematics, programming, and science—where multi-attribute deliberation is non-negotiable. On factual or recall tasks, direct scoring is frequently sufficient.
Discussion
Implications for LLM Evaluation
The results establish that for less capable LLM evaluators, rigid multi-criteria scaffolding (AHP/FAHP) provides substantial robustness, especially in high-uncertainty or logic-intensive categories. The explicit modeling of uncertainty further improves calibration, supporting a more faithful mapping of LLM’s non-deterministic output distributions. DualJudge’s adaptive hybridization yields stability across generator splits and domains without requiring complex meta-estimators, leveraging fast holistic intuition where justified and slow, deliberative structure where error rates spike.
Limitations and Directions
- Computational overhead: The requirement for pairwise comparisons scales quadratically with criterion count. Efficient subset selection or confidence-thresholded routing is a promising mitigation.
- Criteria dependence: Fixed category-level criteria can bottleneck structuring’s generality. Dynamically generated or adaptive criterion sets may significantly increase domain transfer and reliability.
- Fusion hyperparameters: Fixed β may not suit all tasks. Learnable fusion modules, leveraging meta-task characteristics, could deliver further gains.
Future work should extend this architecture to single-response scoring pipelines, RLHF reward modeling, and open-source LLMs outside the gpt-oss or Qwen3.5 paradigms, testing adaptive criterion generation and real-time hybrid routing.
Conclusion
This work systematically demonstrates that structured, uncertainty-aware multi-criteria evaluation—concretely, AHP and especially FAHP—consistently surpasses holistic direct LLM scoring in reliability and calibration when base performance is imperfect. The DualJudge framework, fusing both paradigms via adaptive CR-based weighting, achieves state-of-the-art results on JudgeBench. These findings indicate that progress in automated LLM assessment will increasingly hinge on hybrid architectures that leverage transparent decomposition, dynamic uncertainty modeling, and cross-paradigm fusion, particularly for high-stakes and ambiguous evaluation settings.