- The paper presents VERT, an LLM-based metric that directly scores radiology reports and achieves up to 11.7% higher correlation with expert annotations than previous methods.
- It leverages multiple prompting strategies and few-shot learning via QLoRA fine-tuning on diverse datasets to deliver efficient, scalable performance across varied imaging modalities.
- The study reveals predictable error detection patterns of LLM judges, underlining challenges in handling rare error types and the need for further reference-free evaluation improvements.
VERT: Advancing LLM-Based Evaluation of Radiology Reports
Introduction
Radiology report evaluation is a critical component of medical imaging AI, both as an intrinsic challenge and as an enabling factor for robust generative medical language systems. Prior research has predominantly focused on the development of rule-based metrics, extraction-based methods, and metrics leveraging small, fine-tuned models, typically limited to chest X-ray datasets. However, these approaches exhibit suboptimal generalizability to other modalities and anatomies due to the high heterogeneity of medical imaging and reporting conventions. VERT addresses this gap through (1) a comprehensive evaluation of LLM-based scoring approaches across a wide spectrum of modalities, models, and prompting strategies, and (2) the introduction of the VERT metric, optimized for alignment with expert radiologist judgments and efficient lightweight adaptation.
Datasets for Robust Radiology Report Evaluation
The analysis is grounded in two expert-annotated datasets—RadEval and RaTE-Eval—which together span multiple modalities and anatomical regions beyond chest radiography. RadEval incorporates chest X-ray studies annotated for clinically significant and insignificant errors by category, while RaTE-Eval covers a diverse set of 9 imaging modalities and 22 anatomies, with paragraph-level scoring relevant to practical diagnostic workflows. The score and error distributions are represented in the following histograms:
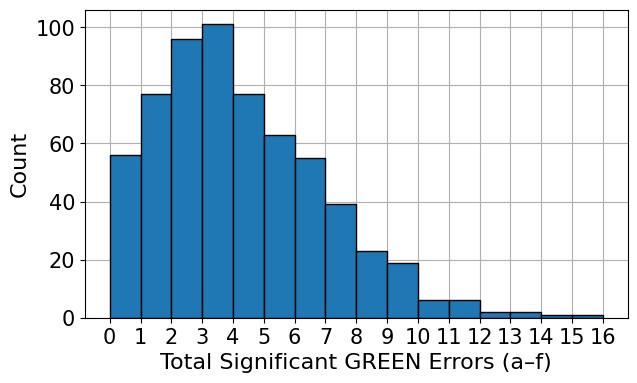
Figure 1: Histogram of error annotations in RadEval.
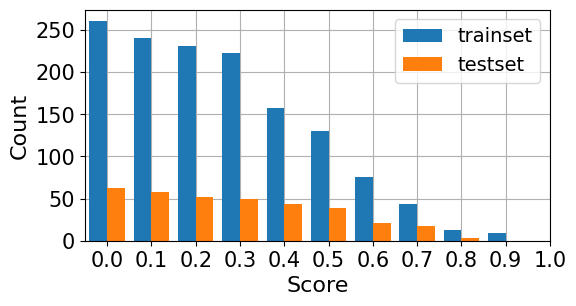
Figure 2: Histogram of normalized expert-annotated scores in RaTE-Eval.
The diversity and structure of these datasets enable a granular assessment of metric generalizability and error detection fidelity.
The core of the methodology involves a systematic comparison among established LLM-as-a-judge metrics—RadFact, GREEN, and FineRadScore—and the proposed VERT metric. Prompt design variants include zero-shot, few-shot, formula-based, and rubric-based instructions delivered across a range of closed- and open-source LLMs. The evaluation leverages Kendall’s τ correlation with expert annotations, facilitating comparability with prior literature.
VERT revises the prompt to elicit a direct accuracy score from the LLM, as opposed to calculation from intermediary error counts, with the target being a continuous value in [0,1] conditional on significant and insignificant error tallies.
Lightweight adaptation is pursued via two axes:
- Few-shot learning: Increasing the number and specificity of in-context examples and error category illustrations
- Parameter-efficient fine-tuning: Adopting QLoRA to tune a 30B MoE model (Qwen3-30B-A3B-Instruct-2507) on 1,300 RaTE-Eval samples without updating full model weights
Prompt-based and fine-tuning approaches are further complemented with ensembling and regression techniques across model families.
Numerical Results: Correlation, Adaptation, and Efficiency
Alignment with Expert Judgments
The VERT metric achieves up to an 11.7% higher correlation (τ) with human scores relative to GREEN, establishing superior alignment across both RadEval and RaTE-Eval. Notably, VERT outperforms on datasets where reference scores are provided, while GREEN derivatives perform better where explicit error annotations are available.
Model and Prompt Analysis
Across model-prompt combinations, proprietary Claude and GPT-4.1 variants yield the highest τ scores, demonstrating that LLM scale and model family significantly influence zero-shot metric performance. Model "reasoning" level (explicit chain-of-thought traces or "thinking") does not consistently improve correlation, with best results observed at low to medium levels for select configurations.
Few-shot and Ensembling Gains
Few-shot prompting offers marginal gains, especially with carefully curated, error-type-specific examples. Ensembling via linear regression—integrating multi-model outputs—yields a further 22.7% increase in correlation over the best single-model result, albeit at the expense of increased inference cost due to multi-model querying.
Efficient Fine-tuning
Parameter-efficient fine-tuning (QLoRA) on Qwen3-30B achieves up to 25% improvement over the zero-shot baseline, converging within 1,300 training samples. The time cost for inference is reduced by a factor of 37.2 compared to API-based LLM use, enabling practical deployment for large-scale evaluation.
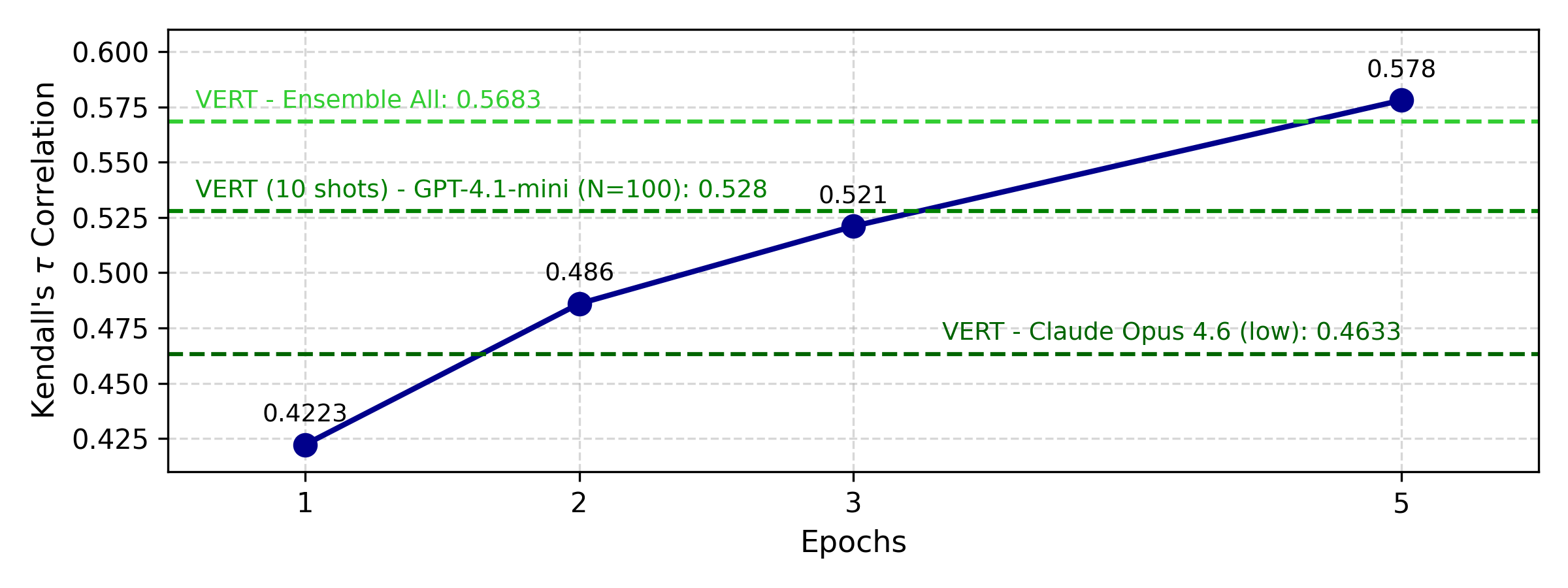
Figure 3: Fine-tuning of Qwen3-30B-A3B-Instruct-2507 on RaTE-Eval trainset.
Systematic Error Detection and Categorization
A comprehensive error detection analysis quantifies both the number of errors detected and error type categorization performance. LLM-based evaluators generally overestimate errors in reports with few errors and underestimate as error count increases. Error injection experiments on RaTE-Eval demonstrate that model-prompt combinations robustly identify false predictions but consistently underestimate omissions when their number exceeds one.
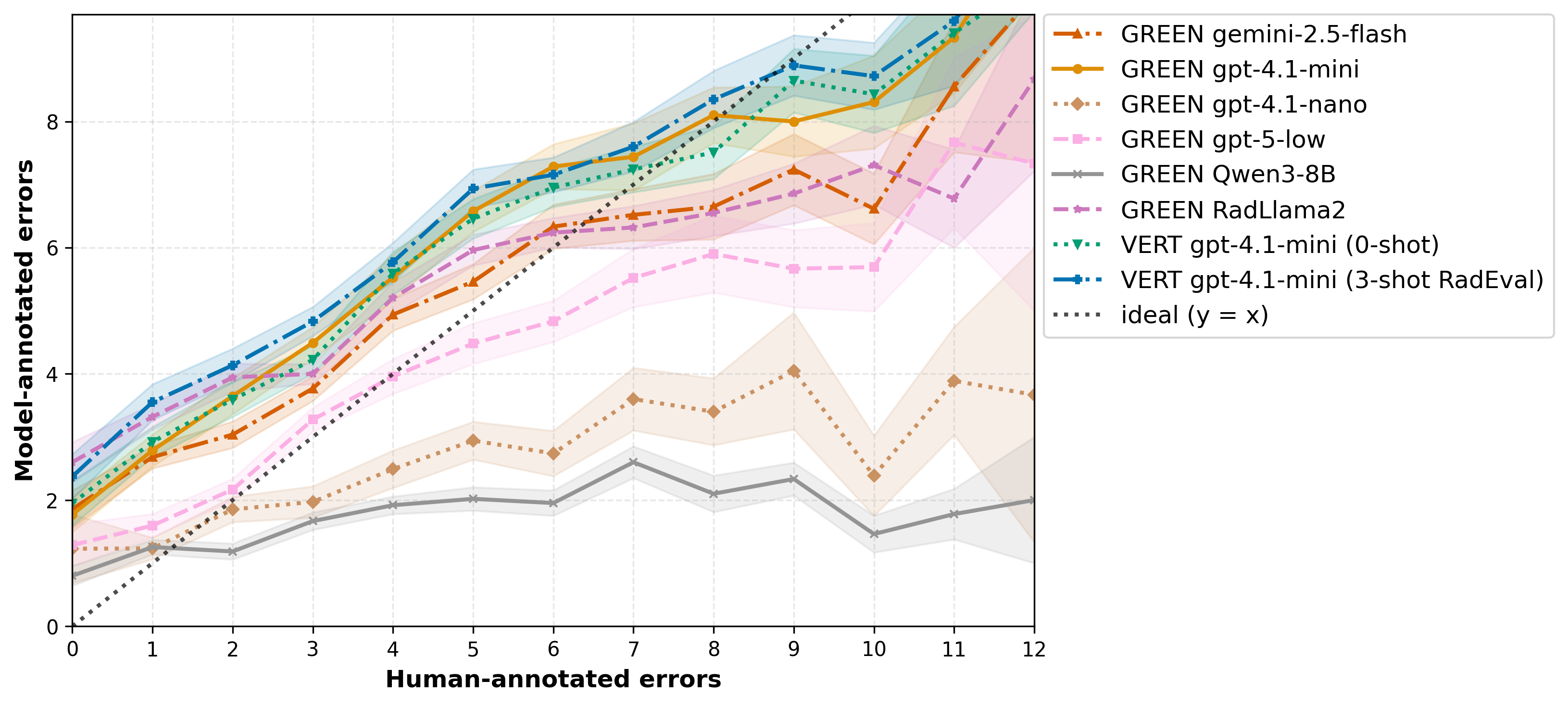
Figure 4: Mean number of clinically significant errors annotated by humans vs. those detected by model-prompt combinations on RadEval.
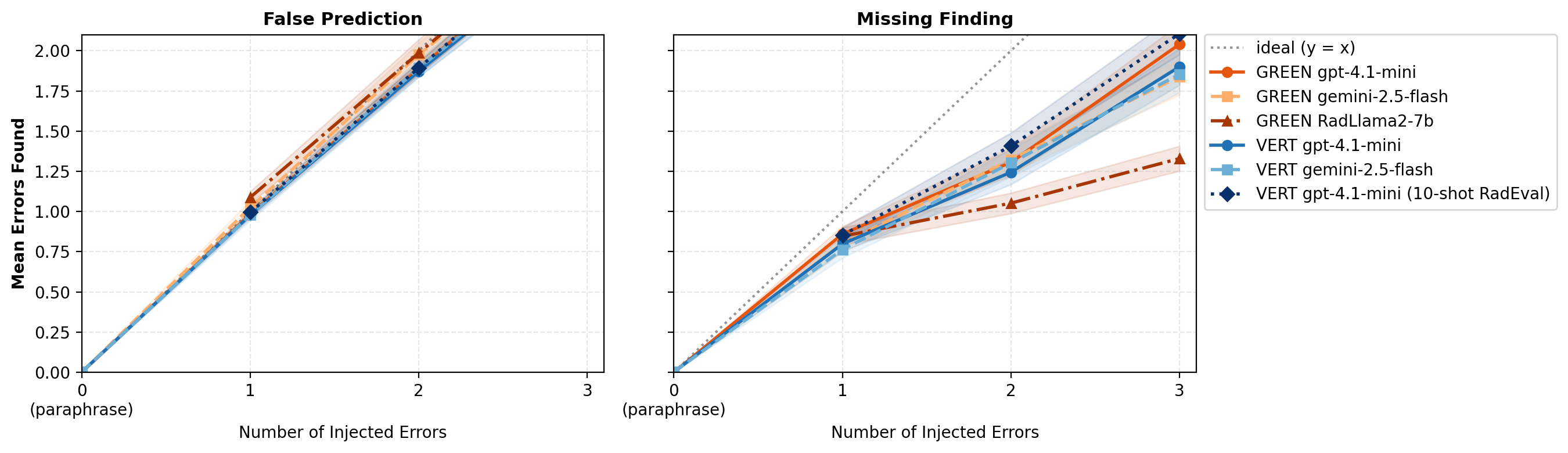
Figure 5: Mean number of clinically significant errors detected by model-prompt combinations vs. number of injected errors, for False Prediction and Omission error types.
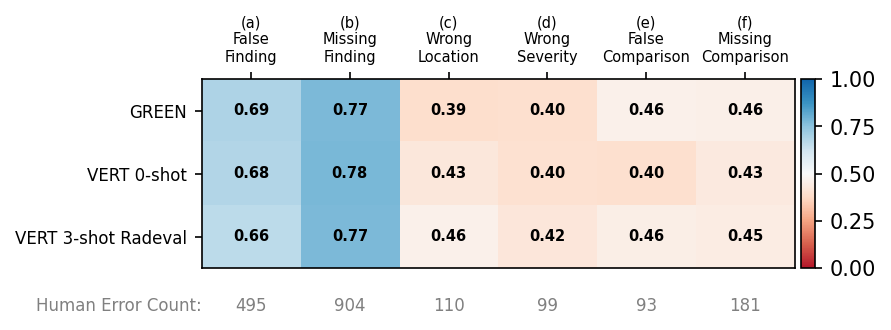
Figure 6: F1 scores for error type on RadEval.
For error categorization (RadEval), F1 scores are highest for types (a) "false prediction" and (b) "omission of finding" (0.66–0.78), with poor sensitivity to other error types. The performance is inverted for false prediction on error-injected RaTE-Eval (F1 up to 0.92 for (a)), indicating modality-dependent metric behavior.
Metric Simulation and Theoretical Properties
Simulation of the GREEN and F1 metrics demonstrates their differing sensitivities to matched findings (TP) and significant error count (S), with F1 less influenced by variation in sampling density for [0,1]0. This explains the higher empirical correlation of [0,1]1 with error annotation datasets and GREEN with clinical report scoring datasets.
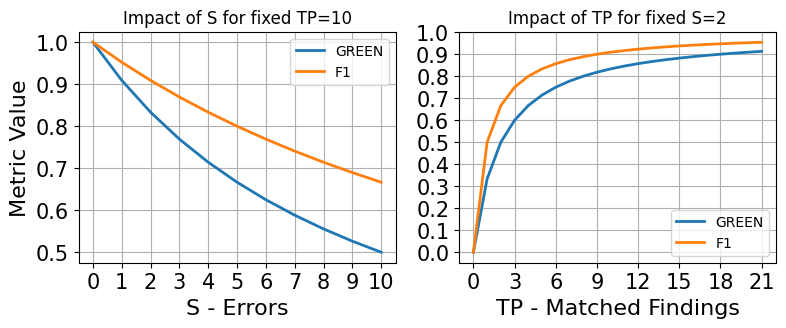
Figure 7: Simulations of the impact of sweeping [0,1]2 or [0,1]3 for GREEN and F1.
Practical and Theoretical Implications
This study establishes the following definitive findings and implications:
- Generalizability: VERT provides robust performance across varied imaging modalities and report complexity, overcoming prior metric limitations specific to chest X-rays.
- Adaptation pathways: Few-shot and fine-tuned open-source models can rival or exceed proprietary API-based LLMs, making deployment viable at scale and cost-efficient.
- Metric error modes: LLM judges display predictable failure modes—often underestimating error counts in high-annotation cases and showing poor discrimination for certain complex error types (c–f).
- Evaluation methodology: Direct prompting for scores improves alignment with human raters, but theoretical metric formulation must be tuned to the scoring paradigm (error-annotation versus overall scoring).
- Scalability: Efficient LoRA-based methods democratize high-quality automated radiology report evaluation, usable in retrospective or real-time generation pipelines.
- Limitations and extensions: Current LLM-based judges still show suboptimal recall for minority error types and do not yet obviate the need for reference-based evaluation, indicating key areas for future work, including reference-free metrics and improved categorical error detection.
Conclusion
VERT delivers a scalable, high-fidelity LLM-based metric for radiology report evaluation, demonstrating up to 25% improvement in expert correlation via efficient lightweight adaptation on diverse imaging datasets. While robust for overall scoring and specific error types, existing LLM evaluators remain challenged by rare error classes, motivating further research in structured error detection and reference-free evaluation frameworks. The study provides practical guidance and benchmarking for the next generation of medical generative model evaluation in multi-modal, real-world settings (2604.03376).