- The paper presents a novel RL-based framework, ConRad, that jointly generates radiology reports and calibrated confidence scores.
- Using Markov Decision Processes and proper scoring rule rewards, ConRad significantly reduces Expected Calibration Error and improves Pearson correlation metrics.
- The framework enables targeted clinical review and demonstrates robust out-of-distribution generalization on radiological datasets.
Calibrated Confidence Expression in Radiology Report Generation via ConRad
Introduction
Reliable deployment of Large Vision-LLMs (LVLMs) in radiology necessitates not only high-fidelity report generation but also systematically trustworthy expressions of model confidence to guide clinical oversight. The tendency of LVLMs to produce coherent yet overconfident text, including hallucinations, elevates risks in clinical workflows that depend on automated reporting. Existing approaches to uncertainty estimation—including post-hoc black-box and white-box confidence scoring, stochastic sampling, and external auditing—exhibit inefficiencies or lack direct calibration, especially in the context of multimodal, long-form radiology reports.
This paper proposes ConRad, a reinforcement learning (RL) framework focused on calibrating confidence expression jointly with factual report generation. ConRad learns to output not only structured diagnostic text but also verbalized scalar confidence estimates at both global (report) and local (sentence) levels, leveraging policy optimization with a proper scoring rule as reward. The approach is designed for practical integration, providing actionable cues for targeted human review and thereby aiming to enable more robust and interpretable AI assistance in radiological workflows.
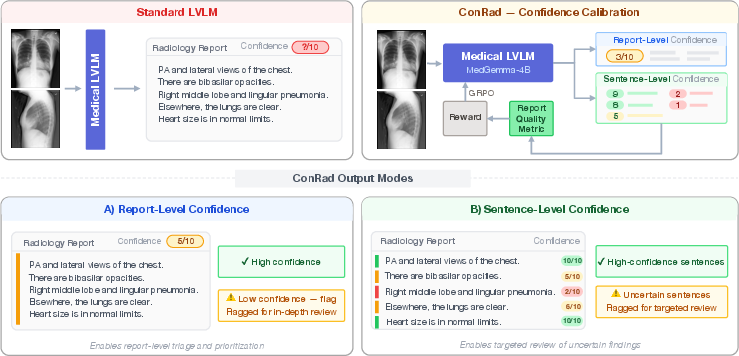
Figure 1: ConRad overview, illustrating conversion of standard LVLM output to confidence-calibrated reports suitable for selective verification.
Methodology
ConRad treats the joint generation of reports and confidence scores as a Markov Decision Process. LVLMs are fine-tuned via RL to maximize calibration of confidence, operationalized as the alignment between the model's verbalized confidence and an external, automated correctness assessment. The core design supports two granularity settings:
- Report-level confidence: A single scalar confidence follows the entire report, calibrated against a continuous semantic correctness score (GREEN metric).
- Sentence-level confidence: Each claim/sentence in the report is followed by a scalar confidence, calibrated against binary correctness at the sentence level.
The RL objective utilizes the logarithmic scoring rule, yielding strictly proper calibration incentives. The reward is applied only to confidence estimates, keeping report generation output otherwise fixed. Training employs Group Relative Policy Optimization (GRPO), optimizing the policy directly with ordinal structure preserved among confidence tokens.
Experimental Evaluation
Experiments are conducted on the MIMIC-CXR dataset, utilizing a 4-bit quantized MedGemma-4B-IT backbone, with LoRA-based adaptation of only the language component. Performance is evaluated primarily in terms of Expected Calibration Error (ECE), Pearson correlation to correctness, AUROC (for binary targets), and factual correctness (GREEN score).
At report level, ConRad outperforms all baselines by a substantial margin—reducing ECE from 0.642 (prompted baseline) and 0.121 (best non-RL probe baseline) to 0.106—with a concomitant increase in Pearson correlation to the correctness metric. Supervised Fine-Tuning (SFT), which treats confidence tokens as categorical, fails to match ConRad's performance due to disruption of ordinal structure. In both report- and sentence-level calibration, the factual content (GREEN) remains stable, confirming that RL-based fine-tuning does not degrade generation quality.
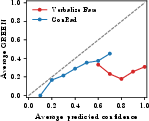
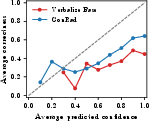
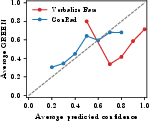
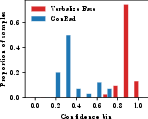
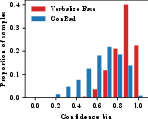
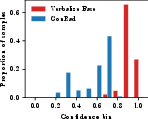
Figure 2: Calibration curves (top) and confidence distributions (bottom) for report-level, sentence-level, and OOD settings; ConRad tracks ideal calibration and yields spread distributions.
At the sentence level, ConRad achieves a drop in ECE from 0.438 to 0.239 and boosts AUROC from 0.558 to 0.633, demonstrating improved discriminative capacity for sentence correctness.
Confidence-Guided Review and OOD Generalization
Filtering sentences or reports based on ConRad's confidence threshold monotonically increases factual precision (Precision GREEN rises up to 0.642 for the highest confidence predictions) but necessarily lowers the coverage, as more uncertain statements are excluded. This operationalizes the model's confidence as a tool for targeted review rather than outright content suppression.
On the IU-Xray out-of-distribution dataset, ConRad maintains strong calibration, reducing ECE from 0.310 (baseline) to 0.034 without fine-tuning on this new domain, and without degradation in report quality.
Agreement with Clinician Judgement
A clinician-based evaluation on 50 reports with triple-rater sentence-wise Likert scoring demonstrates that ConRad better aligns with expert acceptability—correlation increases from 0.069 (base) to 0.268 (mean aggregation), and AUROC from 0.519 to 0.644—further evidence that calibrated confidence signals are more actionable in practice.
Implications and Future Work
The ConRad framework has immediate practical implications for scalable, safe AI integration in medical imaging diagnostics. By shifting from model-internal or post-hoc calibration to direct, interpretable verbalization, it supports triage pipelines where low-confidence outputs are flagged for human review, potentially reducing radiologist oversight burden without compromising safety. Furthermore, ConRad's direct optimization for calibration, support for fine-grained confidences, and strong OOD generalization are indicative of a robust and versatile framework.
Theoretically, ConRad's strict reliance on proper scoring rules for RL rewards suggests its approach may be extensible across domains where generation and actionable uncertainty must be tightly coupled. Future research directions include integrating alternative correctness metrics, exploring continuous confidence estimates beyond token discretization, and scaling evaluations to other modalities and clinical tasks. Assessing impact on long-term workflow efficiency and diagnostic safety in prospective clinical trials remains an open avenue.
Conclusion
ConRad demonstrates that reinforcement learning with proper scoring rule rewards enables calibrated, interpretable confidence expression in LVLM-generated radiology reports. Both report-level and sentence-level confidence outputs are strongly aligned with factual correctness and clinical judgement, outperforming both unsupervised and supervised calibration baselines without cost to generation quality. Confidence-based flagging facilitates targeted review, and calibration generalizes robustly to out-of-distribution data. These results highlight ConRad's potential as a practical foundation for trustworthy, AI-assisted clinical reporting systems.
References
For full references, see "Calibrated Confidence Expression for Radiology Report Generation" (2603.29492).