- The paper demonstrates that prolonged annotation improves annotator competence through efficiency gains and refined labeling techniques.
- Quantitative and qualitative analyses show enhanced inter-annotator agreement, semantic enrichment, and measurable LLM performance improvements.
- The study highlights annotation as an active learning process, suggesting its potential integration into educational interventions for AI literacy.
Competence Development Through Annotation in Social Influence Recognition
Study Overview and Research Framework
This paper systematically investigates how prolonged annotation tasks in social influence recognition impact annotator competence, data quality, and subsequent AI model performance (2604.02951). The annotation process involved 25 annotators from both expert and non-expert backgrounds annotating 1,021 AI-generated dialogues. Each dialogue required multi-dimensional labeling including degree and technique of social influence, intentions, consequences, reactions, certainty, and free-text comments.
To assess competence shifts, the study implemented quantitative and qualitative analyses: annotator agreement metrics, annotation time tracking, LLM performance on annotated data, and extensive self-assessment surveys. An initial subset of 150 texts was annotated before and after the main annotation process to provide a controlled basis for comparison.
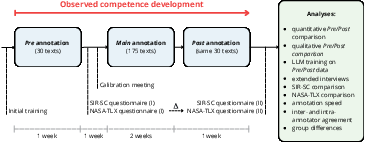
Figure 1: Overview of the studied annotation process with competence shift analyses.
Quantitative Analysis: Agreement, Efficiency, and Technique Stability
Annotator agreement, measured via Krippendorff's alpha on social influence technique identification, demonstrated a moderate increase in inter-annotator agreement for experts (α=0.383→0.405), but negligible change for non-experts (α=0.290→0.286). Intra-annotator agreement, while higher than inter-annotator values, remained modest, supporting the characterization of social influence as a highly subjective labeling task.
Annotation efficiency improved substantially, with mean annotation time decreasing from 6.56 to 5.86 minutes per text in repeated rounds (p=0.0009). A consistent negative temporal trend (β=−0.0084, R2=0.224, p<0.001) illustrates increasing speed across the main annotation phase.
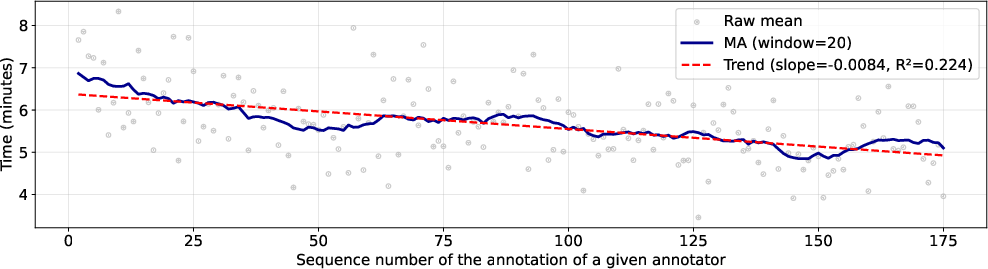
Figure 2: Annotation time change over the course of the process.
Technique assignment stability analysis uncovered substantive shifts, notably in experts—assignments to abstract affective techniques decreased, substituted by more behaviorally grounded categories, with Labeling showing the largest net increase (+46.4%) and Liking the largest decrease (−25.2%). These shifts signal progressive refinement of annotators' conceptual frameworks.
Qualitative Analysis: Semantic Enrichment and Thematic Breadth
Qualitative coding of free-text answers (RICs) indicated systematic broadening and increased detail post-annotation: 44.2% of consequence annotations and 46.7% of reaction annotations exhibited broadened thematic perspectives, with >50% showing increased specificity after repeated annotation. Experts exhibited a pronounced increase in thematic diversity and formal linguistic expression; non-experts showed comparable but attenuated effects.
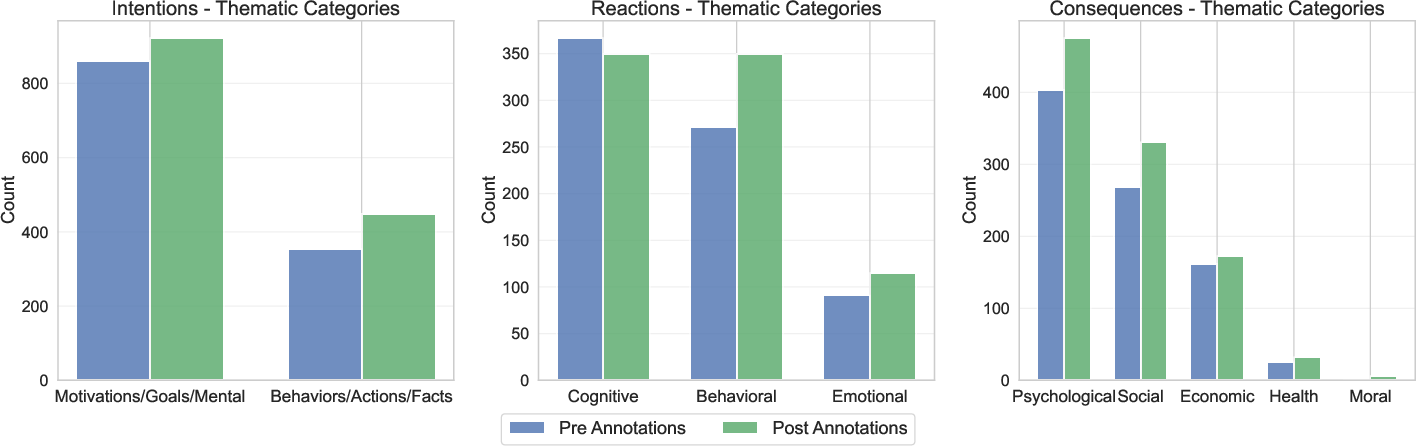
Figure 3: Shifts in the number of individual RICs by thematic categories.
Assessments of consequence annotations revealed a shift toward conditional phrasing and broader social reach. Intention annotations evolved from being predominantly motivation-based to a more balanced inclusion of behavioral objectives. Reaction descriptions became more concrete and casual, indicating improved fluency in behavioral characterization.
Impact on LLM Training and Data Quality
LLMs trained on Post-phase annotated data consistently outperformed those trained on Pre-phase data across all settings. DeepSeek-V3.2 (ICL, 30-shot) achieved a +0.0149 Jaccard improvement; Llama-3.1-8B-Instruct (SFT) improved by +0.0069 Jaccard index despite small sample size. Model performance gains scaled with increasing few-shot examples, reinforcing the hypothesis that annotator competence directly influences data informativeness.
Annotator Perception and Workload Dynamics
Self-perceived competence and confidence increased markedly (Cohen’s dcompetence=0.567, dconfidence=0.388). Surveyed confidence scores rose across all groups (p<0.001). Qualitative interview data highlighted advancements in recognition capacity, awareness of manipulative intent, and the ability to communicate social influence concepts. Annotators reported the emergence of deliberate learning strategies and spontaneous detection of manipulation outside the annotation context.
Workload assessments via NASA-TLX captured increased subjective workload and perceived performance deficit in later annotation rounds—consistent with a transition to “conscious incompetence” as annotators developed deeper awareness of task complexity.
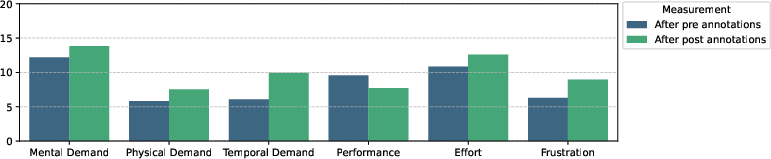
Figure 4: Comparison of mean scores of NASA-TLX dimensions between measurements.
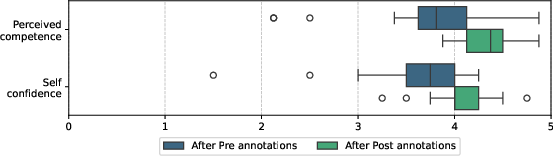
Figure 5: Box Plots of Perceived Competence and Self-confidence across measurements.
Discussion and Implications
The evidence supports the assertion that annotation is not merely a data collection process but also constitutes an active learning environment, especially for subjective tasks such as social influence detection. Increased annotator competence—observable through efficiency gains, semantic sophistication, convergence in expert labeling, and positive self-assessment—is localized predominantly among expert annotators, but is also evident, albeit to a lesser degree, among non-experts.
The positive impact of annotation-driven competence growth on LLM performance underscores the necessity of ongoing monitoring and possibly curricular intervention in annotation campaigns. These findings suggest practical opportunities for integrating annotation-based training into education, particularly for youth-oriented AI literacy programs targeting resilience against persuasive content.
Conclusion
The annotation of subjective phenomena such as social influence yields measurable gains in annotator competence and data quality, with pronounced effects in expert groups. These gains benefit downstream AI, as evidenced by improved LLM performance on refined annotations. Annotation-driven learning processes, if systematically harnessed, could form the basis for both robust dataset creation and scalable educational interventions. Future directions include broadening participant cohorts, extending analyses to additional subjective domains, and benchmarking against non-subjective tasks to clarify skill transferability and the interpretation of agreement metrics.