- The paper introduces a quantized 1.7B SLM that, when fine-tuned with expert annotations and data augmentation, outperforms proprietary LLMs in reproducibility and bias reduction.
- It employs a hierarchical rubric across six axes and targeted techniques like paraphrasing, component permutation, and token dropout to enhance model generalization.
- The method achieves high inter-annotator agreement and superior classification performance, demonstrating its potential for transparent, cost-effective NLP annotation.
More Human, More Efficient: Task-Aligned Annotations via Quantized SLMs
Introduction and Motivation
The proliferation of LLMs has redefined the paradigms of evaluation and annotation in NLP, with the LLM-as-a-Judge (LaaJ) methodology becoming widespread for scalable label production. While effective, reliance on proprietary LLM APIs introduces reproducibility and transparency concerns, version drift, and exposes annotation pipelines to opaque biases. Most notably, these black-box LLMs demonstrably suffer from systemic biases—such as preference for input order, verbosity, or aesthetically pleasing responses—that frequently misalign with human expert consensus and lead to suboptimal training trajectories downstream.
This work addresses these foundational issues by advancing a pipeline built upon a quantized, open-source Small LLM (SLM) with only 1.7B parameters, supervised on a compact but high-quality human-annotated dataset. Through meticulous design of a hierarchical, multi-dimensional rubric, and the introduction of targeted data augmentation and regularization strategies, the authors empirically demonstrate that highly efficient, deterministic annotation can not only rival, but substantially outperform state-of-the-art proprietary LLMs in both agreement with human annotators and domain robustness.
Rubric Design and Dataset Protocol
Annotation and evaluation are structured according to a granular rubric inspired by best practices in NLG evaluation, decomposed along six axes: Completeness, Clarity, Interpretability, Conciseness, Accuracy, and Relevance. Each response is tagged on an ordinal scale from -2 (severe failure) to +2 (full satisfaction), capturing subtle gradient differences.
Expert annotators labeled a curated corpus derived from Singapore Prison Service (SPS) web content and corresponding questions, generating a multi-dimensional dataset of candidate answers from seven open-source SLMs for cross-model variability. Annotator disagreement was explicitly modeled and preserved, and inter-annotator reliability was quantified via Krippendorff’s alpha (α), which adjusts for rater disagreement and is robust to ordinal labeling.
Model Architecture and Training Procedure
The annotation model leverages Qwen3-1.7B, quantized to 4-bit precision, and finetuned using Unsloth for parameter-efficient adaptation. Annotator scores are appended directly to the prompt as completion targets, with the model treated as a sequence predictor rather than as an ordinal classifier, optimizing a completion-only objective.
Three augmentation/regularization mechanisms significantly improve generalization:
- Prompt paraphrasing introduces syntactic/instructional diversity.
- Component permutation disrupts position bias by shuffling question, context, and answer order.
- Token dropout masks non-critical prompt tokens stochastically, discouraging overfitting to lexical artifacts and promoting robust evaluation.
Baselines include major proprietary LLMs (GPT-4o, GPT-5-nano, GPT-5-mini, GPT-5.2-chat) in zero-shot and optimized few-shot modalities along with ablations of the SLM fine-tuning procedure (e.g., without augmentation and with LoRA dropout).
Empirical Findings and Analysis
The proposed SLM pipeline, despite its modest scale, achieves 0.5774 inter-annotator agreement (α) on the SPS dataset, exceeding the best-performing GPT-5-mini proprietary model by 0.3312 points. All proprietary model configurations, including those optimized via instruction selection and demonstration refinement, fail to reach moderate agreement with human annotators.
Training diagnostics reveal stark contrasts in generalization and overfitting dynamics, attributable to the proposed training strategies.
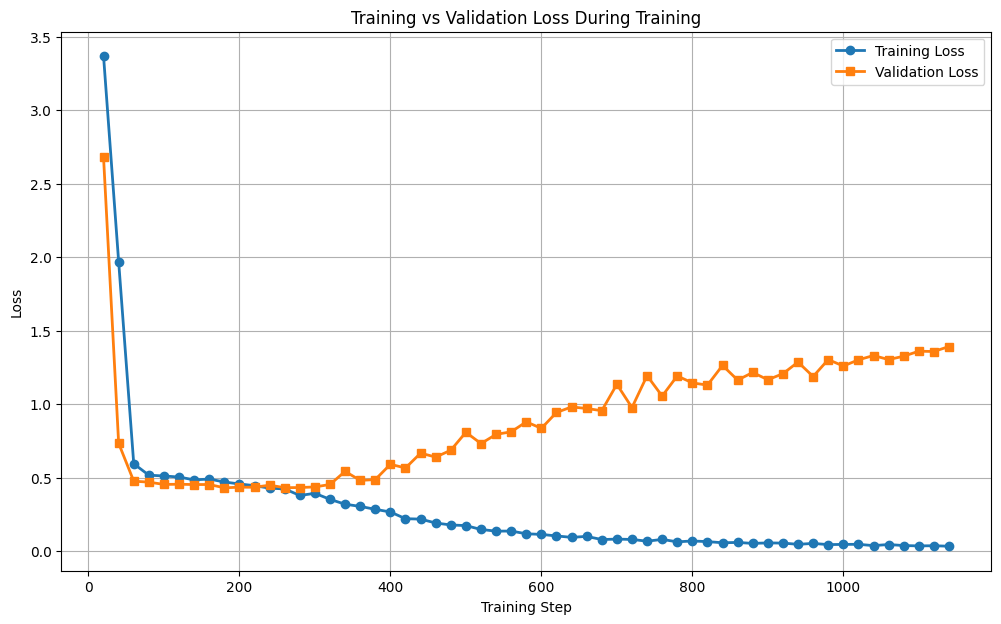
Figure 1: Training and validation loss curves without augmentation strategies reveal clear overfitting and poor generalization to held-out data.
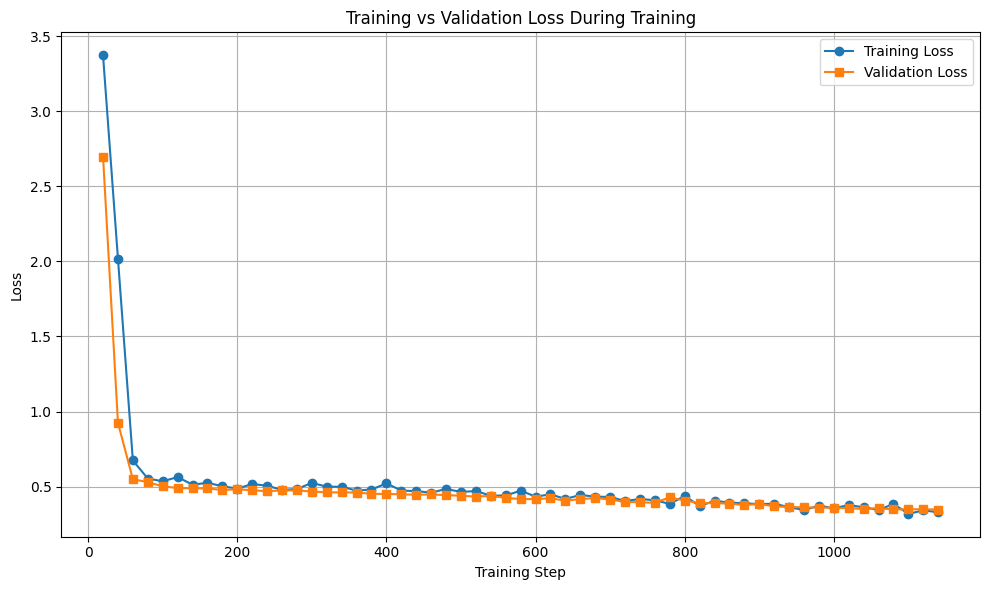
Figure 2: Training and validation losses with the proposed augmentation are consistently lower and more aligned, demonstrating improved regularization and generalizability.
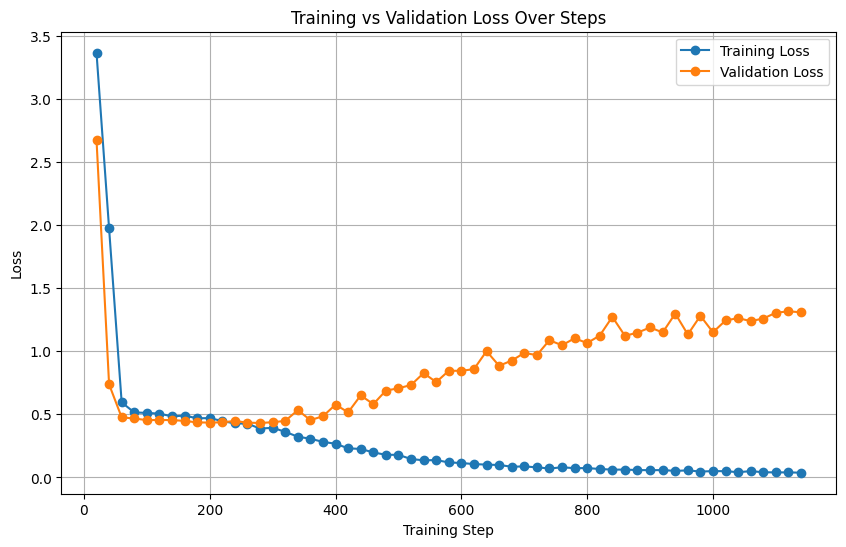
Figure 3: Loss curves under LoRA dropout regularization. While beneficial, this approach underperforms compared to augmentation-based protocol.
In expanded experiments on the GoEmotions emotion classification dataset, the SLM achieves accuracy of 0.8163 and Macro-F1 of 0.6380—outperforming all GPT-based baselines by a considerable margin (nearly doubling GPT-4o accuracy). This underscores that small, domain-aligned models surpass broad generalists for abstract judgment tasks when equipped with high-quality labeled data and augmentation.
Discussion and Implications
These results establish that quantized SLMs can be deterministically aligned to expert judgment with greater fidelity than black-box LLMs—even those orders of magnitude larger—across both rubric-based evaluation and classification. This challenges prevailing assumptions surrounding the necessity of scale for annotation efficacy and highlights the limitations of zero-/few-shot prompt programming in offsetting inherited LLM biases.
The pipeline’s determinism yields perfect reproducibility—critical for scientific and privacy-sensitive annotation applications. Furthermore, its small memory and compute footprint allow deployment on consumer hardware or edge devices, democratizing the annotation process without compromising on inter-annotator alignment.
By eschewing reliance on proprietary APIs, the proposed methodology resolves key issues of cost, privacy, and reproducibility, while obviating the need for continual prompt engineering in the face of evolving LLM versions and unknown data curation. The publicly released codebase also ensures community verifiability and extension.
Theoretical and Practical Impact
This methodology contributes to the broader theoretical discourse on annotation: it demonstrates the practical supersession of model size by task-specific alignment and targeted augmentation in settings where nuanced, human-like judgment is paramount. The work also strengthens calls for open, transparent annotation pipelines in domains (e.g., healthcare, law) where reproducibility and auditability are non-negotiable.
Practically, the approach paves the way for community-driven, locally hosted annotation systems, reducing reliance on potentially biased, expensive commercial LLMs and fostering trustworthy machine-generated labels at scale.
Conclusion
A quantized 1.7B parameter SLM, judiciously finetuned on a concise, high-quality human-annotated dataset and augmented with paraphrasing and regularization, can serve as an efficient, reproducible, and highly aligned annotator across diverse NLP tasks. The results call into question the primacy of large proprietary LLMs in automatic annotation and evaluation, setting a foundation for cost-effective, transparent, and bias-reduced annotation pipelines. Future research may further explore adaptive alignment strategies and expanded rubric designs for broader task coverage, accelerating progress toward robust, human-aligned machine annotation.