- The paper introduces a novel provenance-based gradient guidance approach that directs model attention to task-relevant regions, reducing spurious correlations.
- It leverages synthetic data generation methods like image mixing and generative editing, using provenance masks to enhance localization and improve classification accuracy.
- Experimental results demonstrate improved robustness, faster convergence, and mitigated effects of background artifacts across various tasks.
Introduction
The use of synthetic data for regularizing and improving the generalization of deep neural networks (DNNs) is widespread, particularly in computer vision and related domains. However, existing synthetic learning approaches often improve robustness only indirectly by diversifying data distributions, without explicitly informing models which regions in the input are relevant for the task. "Learning from Synthetic Data via Provenance-Based Input Gradient Guidance" (2604.02946) addresses this by introducing a principled framework that leverages provenance information—annotation-free labels that specify the true origin of each input region—available during data synthesis. The proposed method uses these provenance signals to guide input gradients and thus enforces class predictions to depend on truly relevant regions, effectively mitigating the learning of spurious correlations induced by synthetic artifacts or contextual biases.
The framework generalizes across various synthetic data generation strategies (e.g., mixing, editing) and applies to both vision and spatio-temporal action localization tasks. The paper presents a suite of experiments demonstrating that provenance-guided gradient supervision systematically improves discriminative performance, robustness, and convergence efficiency.
Methodology
The framework consists of three components: (1) Data Synthesis, (2) Provenance Extraction, and (3) Input Gradient Guidance.
Data Synthesis and Provenance Extraction
Synthetic data generation is accomplished via three paradigms:
Rather than solely relying on indirect regularization via data augmentation, the method introduces a provenance loss, LPG, penalizing input gradients corresponding to class logits in regions that, according to the provenance mask, should not contribute to the class score. Specifically:
- For mix-based synthetic data, the gradient of each class logit is explicitly suppressed outside the mask corresponding to that class.
- For hard-label synthetic data (as in generative editing), the class logit's input gradient is suppressed over any non-target (altered) region.
The total loss is:
Ltotal=Lcls+αLPG
where Lcls is the (soft or hard) cross-entropy classification loss and α balances the regularization strength.
This approach forces models to localize their evidence on semantically meaningful regions, increasing robustness to distribution shifts (e.g., spurious context cues).
Experimental Results
The evaluation assesses localization and classification performance, as well as robustness to domain shift and spurious correlation. Datasets include CUB-200-2011 for fine-grained bird recognition and localization, iWildCam for domain shift, Waterbirds for background-class correlation, and UCF101-24 for spatio-temporal action localization.
Weakly Supervised Object Localization
Incorporating provenance-guided input gradient supervision into CutMix and multi-modal models (VGG16, DeiT-S, SAT) results in a consistent boost in localization accuracy. For instance, CutMix+CAM on CUB improves from 62.3% to 65.1% mean MaxBoxAccV2; introducing provenance loss lifts SAT from 91.5% to 92.1% mean accuracy.


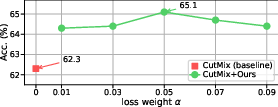
Figure 2: Guided Grad-CAM visualizations (left) and predicted BBoxes overlaid on ground truth (middle) on CutMix-synthesized CUB images; localization accuracy as a function of α (right).
The qualitative results demonstrate increased focus of class activation maps on the actual target object, with reduced reliance on spurious background correlations. These trends are robust to variations in the α coefficient.
Weakly Supervised Spatio-Temporal Action Localization
For SKP with BatchMix augmentation on UCF101-24, provenance-based guidance boosts AP from 38.0% to 39.7%. This highlights utility beyond images, into spatio-temporal domains where action cues may be confounded by unrelated trajectories.
Image Classification under Distribution Shifts
When introduced to ALIA (image editing-based augmentation), provenance-based guidance further improves accuracy: CUB (71.7%→72.0%), iWildCam (83.5%→84.4%), Waterbirds (71.4%→80.7%). The improvement on Waterbirds (9.6 pp) signals strong mitigation of background-based spurious correlation, a critical concern for robust model deployment.


Figure 3: Visualization of image editing synthesis steps and corresponding provenance masks deriving unedited (target) versus edited (non-target) regions.
Ablations: Mask Quality and Regularization
- Mask dependence: If the provenance mask is replaced by a random or full (uniform) mask, accuracy drops (Tab. R1 controls), confirming that performance gains stem from semantically meaningful provenance, not mere gradient suppression.
- Mask robustness: Modest dilation/erosion (±30%) of mask regions does not notably harm performance; the method is robust to some imprecision in mask extraction, especially for generative editing-based provenance.
- Training Efficiency: The approach reduces epochs-to-convergence for both mixing-based (VGG, DeiT-S) and image editing-based setups—sometimes by over 3×—without increasing tuning complexity.
- Computational overhead: Extra memory (due to second-order differentiation for input gradients) is offset by fewer required epochs for convergence.
Theoretical and Practical Implications
This work makes a concrete case for leveraging annotation-free, synthesis-side provenance annotations as auxiliary supervision in synthetic data pipelines. Its modularity ensures applicability to arbitrary modalities and synthetic learning strategies providing region-level provenance. The explicit suppression of input gradient signal in non-target regions yields models that are better aligned with the task itself, less reliant on context or artifact-based shortcuts, and more robust under domain shifts.
A core implication is that the provenance-based regularization localizes the model's functional support and promotes interpretability, as visualized through activation maps and sensitivity heatmaps.
Given the reliance on provenance masks, future work should examine further avenues for provenance extraction, including unsupervised or model-attention-based mask generation, especially in generative augmentation pipelines where difference images may be insufficient. The paradigm also invites integration into more fine-grained multi-modal or continuous-provenance tasks, as well as scaling studies on large foundation models.
Conclusion
Provenance-based input gradient guidance transforms synthetic learning from indirect regularization to direct supervision, focusing DNN attention on task-relevant input regions as provided by the synthesis process. The framework generalizes across image and temporal domains, different architectures, and multiple synthetic strategies. The result is enhanced robustness to spurious correlations, improved convergence efficiency, and superior localization and classification metrics without incurring significant hyperparameter or annotation cost. This method establishes provenance-aware regularization as a central component for any future work on synthetic data-driven training regimens.
