- The paper presents an ℓ1-regularized universal kriging method (K-ADMM) that achieves sub-second grid frequency predictions by enforcing sparsity in the estimator.
- It utilizes spectral diagonalization and a tailored ADMM approach to split the optimization into tractable subproblems, significantly reducing computational complexity.
- Empirical results demonstrate lower prediction errors and improved interpretability compared to standard kriging and GP regressors, making it viable for fast frequency control.
Accelerated Kriging Interpolation for Real-Time Grid Frequency Forecasting
Problem Context and Motivation
Grid frequency prediction underpins operational stability in power systems, especially as power networks transition towards high penetrations of inverter-based resources (IBRs), leading to decreased system inertia and increased susceptibility to rapid frequency transients. The limitations of physics-based modeling and deep learning approaches—stemming from either inadequate fidelity, data requirements, or lack of interpretability—necessitate robust, data-driven alternatives that offer both computational tractability and principled uncertainty quantification. This work introduces an ℓ1-regularized universal kriging (UK) framework, reformulated for efficient solution via a structured alternating direction method of multipliers (ADMM) scheme (K-ADMM), to deliver sparse, interpretable forecasts with sub-second performance suitable for fast frequency control.
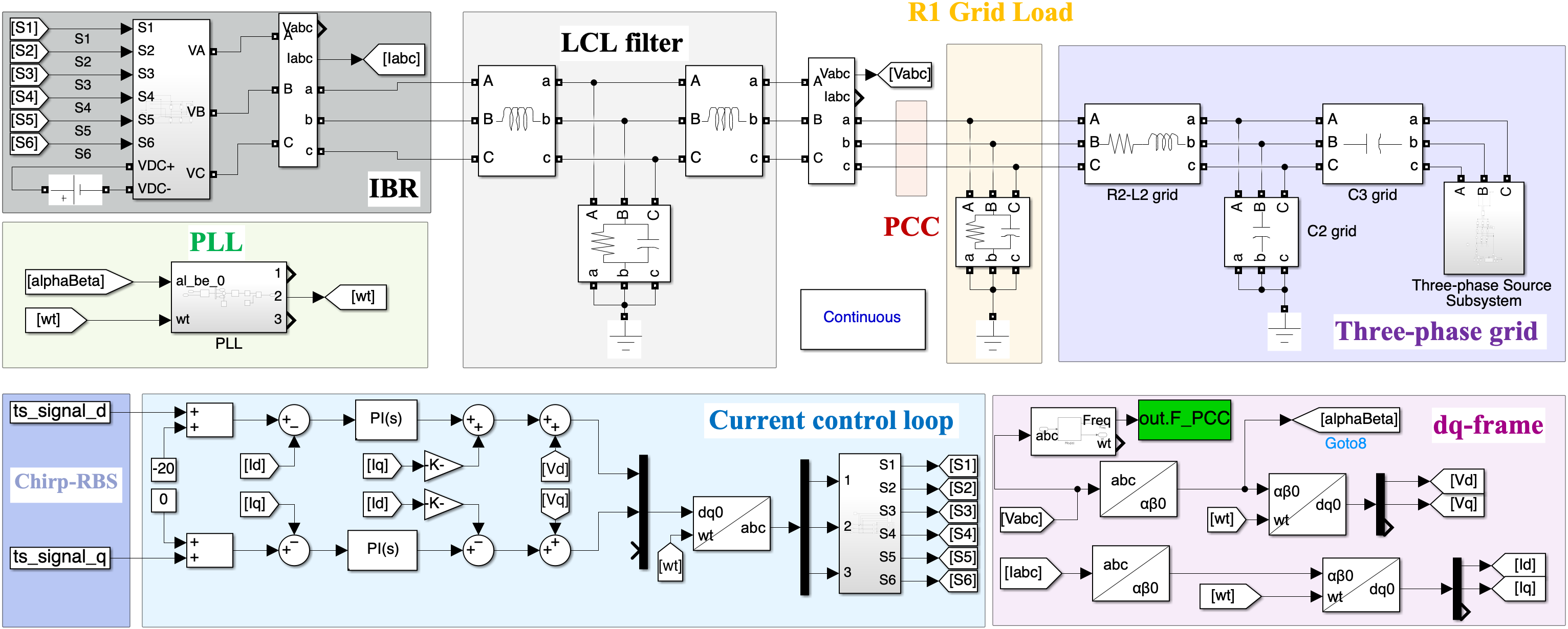
Figure 1: MATLAB Simscape schematic of the simulated grid case study featuring an IBR injection point and realistic measurement perturbations.
Methodological Advances
The proposed method extends UK by imposing sparsity-inducing ℓ1 regularization on the weight vector λ associated with the best linear unbiased estimator (BLUE) formulation. Unlike conventional kriging—where the screening effect and dense predictors can yield negative and physically uninformative weights among all samples in a local cluster—the regularized formulation constrains the predictor to select a minimal subset of influential regressors. This is operationalized as:
λmin−λ⊤ΓDλ+2Γ0⊤λ+i∑βi∣λi∣ subject toRλ=r0
To circumvent the computational burden induced by the dense, often ill-conditioned variogram (semivariogram) matrices and the non-smooth norm, the authors introduce a spectral diagonalization that enables splitting the optimization into tractable homogeneous subproblems. The ADMM-based numerical procedure is specifically tailored: the quadratic part is rendered separable, the nonsmooth term is efficiently managed via proximal updates, and affine unbiasedness constraints are enforced with high precision.
Empirical Evaluation and Numerical Behavior
The method is validated using a detailed Simscape simulation of a weak grid equipped with an IBR operating under realistic stochastic conditions. Data-driven ARX regressors encapsulate the relevant grid frequency and dq-frame current histories, with clusters in regressor space established through k-means partitioning to enable locally homogeneous modeling and computational scalability.
Experimental semivariogram estimation demonstrates non-differentiable dynamics and motivates the use of an exponential model, fitted with high consistency to empirical spatial statistics.
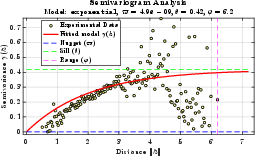
Figure 2: Empirical semivariogram (yellow) and fitted exponential model (red), validating model selection for spatio-temporal correlation.
A formal benchmarking process—using discrete trapezoidal error accumulation over a 40-step (500 ms) predictive horizon—guides hyperparameter selection for the ARX regressor lengths, ultimately fixing na=2, nb=4 as optimal.
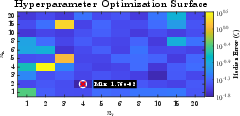
Figure 3: Heatmap of trajectory prediction error as a function of ARX orders na and nb; the boxed minimum indicates the final configuration used.
Sparsity enforcement significantly reduces the number of active weights per prediction (to approximately 20% of the local cluster), as illustrated by direct visualizations of λ∗ vectors. The regularized predictor displays markedly fewer negative weights, directly correlating with improved error statistics.
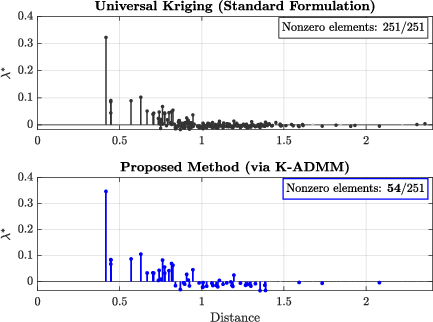
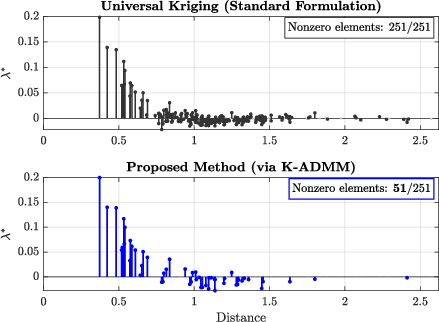
Figure 4: Standard UK solutions (top) distribute weights densely; K-ADMM (bottom) enforces sparsity, highlighting only the most informative neighbors.
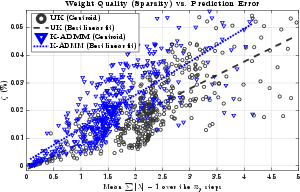
Figure 5: Relationship between negative weight magnitude (ℓ10) and prediction error. K-ADMM predictions (blue) achieve both lower errors and near-interpolative behavior compared to non-regularized UK.
Qualitative comparisons on challenging transient scenarios confirm that K-ADMM matches or outperforms both standard UK and GP regressors in pointwise and uncertainty quantification, with substantially lower active model complexity.


Figure 6: Recursive 0.5s frequency trajectory predictions. Columns: Standard UK, K-ADMM, GP regression. Red dashed: ground truth; shaded: uncertainty intervals. K-ADMM attains high accuracy with substantial sparsity.
K-ADMM exhibits robust numerical convergence, consistently terminating within a median of 9 ADMM iterations per prediction step, and requiring only 44 ms (median) to compute a 500 ms trajectory—orders of magnitude faster than generic QP solvers.
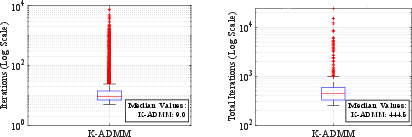
Figure 7: K-ADMM convergence on validation set: left, per-step iterations (median: 9); right, total iterations over 40-step trajectories.
Theoretical and Practical Implications
The introduction of ℓ11-regularization into kriging for power system forecasting shifts the estimator's behavior decisively from extrapolation-prone, dense models to parsimonious, locally adaptive predictors. Notably, regularization aligns with physical intuition, reflecting convex combinations of proximate historical data under stationarity assumptions. The ADMM-based solution strategy preserves numerical stability—even under strong correlations and nearly singular kernel matrices—and avoids degradation of predictive performance. The strong correspondence of negative weights with test error further emphasizes the benefit of sparse, interpolative solutions in operationalizing kriging within dynamic system contexts.
Empirically, median relative trajectory errors are held below ℓ12, ensuring suitability for sub-second grid control (e.g., fast frequency response mechanisms). The computational profile easily fits within real-time operational budgets, facilitating deployment in next-generation wide-area monitoring and adaptive control systems.
Future Directions
Potential avenues for further research include:
- Extension of the proposed K-ADMM framework to multivariate and non-Euclidean input spaces (e.g., for regionalized, multi-node grid predictions);
- Online adaptation of both variogram models and regularization strengths, e.g., using streaming data for resilience to regime shifts;
- Integration with control and protection modules to directly exploit uncertainty quantification in adaptive grid response policies;
- Investigation of hybrid physically-informed kriging where explicit domain knowledge (e.g., known line or converter transfer functions) further constrains or guides the adaptive learning process.
Conclusion
The paper establishes a principled, computationally scalable, sparse kriging framework for rapid power grid frequency forecasting, suitable for deployment in low-inertia, renewable-heavy systems. The proposed K-ADMM algorithm balances predictive accuracy, statistical interpretability, and operational efficiency, sidestepping the limitations of both standard kriging and deep learning approaches. Its adaptivity, coupled with robust uncertainty quantification and numerical reliability, positions it as a practical tool for future power system monitoring and control applications.