- The paper presents explicit formulas for the Lipschitz constant of kernel feature maps, enabling precise robustness certification in kernel-based learning systems.
- It details a rigorous theoretical framework that computes bounds for both infinite-width neural network kernels and shift-invariant kernels using closed-form expressions.
- Numerical experiments confirm that empirical Lipschitz estimates converge to theoretical bounds, validating the robustness guarantees provided by the derived criteria.
Lipschitz Bounds for Integral Kernels: Theory and Implications
Introduction
The quantitative characterization of robustness in kernel-based learning systems is paramount for applications subject to adversarial perturbations or sensitive to operator stability. In this context, the global Lipschitz constant of a model—particularly of the kernel feature map—is directly tied to certified robustness and stability guarantees. The article "Lipschitz bounds for integral kernels" (2604.02887) provides a comprehensive theoretical framework for obtaining explicit, often sharp, Lipschitz constants for a broad class of integral kernels, including those associated with infinite-width random neural networks and shift-invariant kernels commonly used in practice.
Main Theoretical Results
The paper advances the state of the art by addressing the estimation and explicit computation of the Lipschitz constant for the feature map associated with positive definite kernels that admit a representation as an integral over random features. The core contribution is the establishment of precise conditions under which the feature map is Lipschitz continuous, accompanied by closed-form (or tractable) expressions for the optimal Lipschitz constant.
Lipschitz Regularity of Feature Maps
Let k(x,x′)=∫Ωϕ(ω,x)ϕ(ω,x′)dP(ω) denote the integral kernel with associated feature map φ:x↦k(x,⋅) into its RKHS. Under the assumption that ϕ(ω,⋅) is Fréchet differentiable and Lip(ϕ(ω,⋅)) is L2(P)-integrable, the feature map’s Lipschitz constant Lip(φ) can be exactly characterized by
Lip(φ)=x∈X, z∈SEsup∥Dxϕ(⋅,x)[z]∥L2(P)=x∈X, z∈SEsup(DxDyk(x,x)[z,z])1/2
where SE is the unit sphere in the input Banach space.
This formula generalizes prior non-sharp bounds, leading to tighter and sometimes minimal certificates for model robustness. Furthermore, the article identifies a criterion under which no finite Lipschitz bound exists—namely, when the corresponding supremum diverges, as in the case of certain non-smooth kernels.
Classes of Kernels Analyzed
Infinite-Width Neural Network Kernels
For two-layer neural network kernels with random weights (w,b) drawn from an isotropic Gaussian distribution, and ϕ(ω,x)=σ(wTx+b) for activation φ:x↦k(x,⋅)0, φ:x↦k(x,⋅)1 admits an explicit expression as a supremum over a two-dimensional integral involving the first derivative of φ:x↦k(x,⋅)2 and the Gaussian measure. In particular:
- Random Fourier Features (RFF): For φ:x↦k(x,⋅)3 and phase uniform in φ:x↦k(x,⋅)4, corresponding to the Gaussian kernel, φ:x↦k(x,⋅)5 where φ:x↦k(x,⋅)6 is the Gaussian width parameter.
- ReLU Kernel: For φ:x↦k(x,⋅)7, φ:x↦k(x,⋅)8, matching robust upper bounds for neural network kernels.
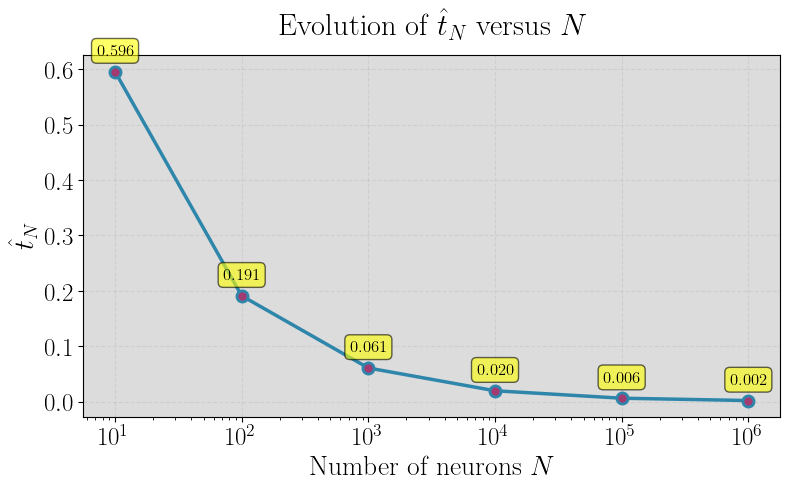
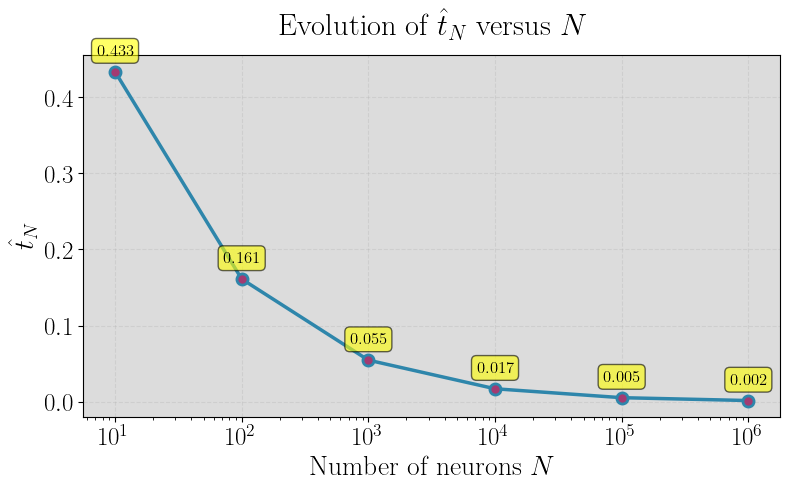
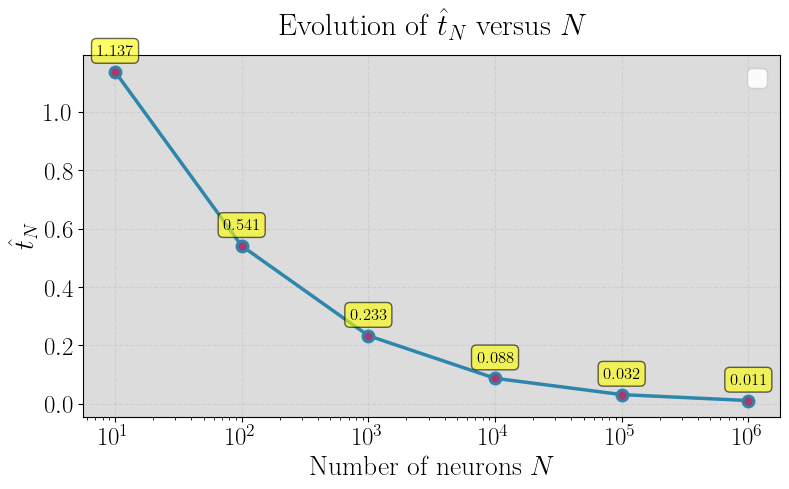
Figure 1: Random Fourier features of Gaussian kernel.
Shift-Invariant Kernels
For continuous, shift-invariant kernels (φ:x↦k(x,⋅)9) with Fourier transform ϕ(ω,⋅)0, the necessary and sufficient condition for the feature map’s Lipschitz continuity is that ϕ(ω,⋅)1. The Lipschitz constant is
ϕ(ω,⋅)2
This result applies to generalized Gaussian, Matérn, and Laplace kernels, where for Matérn kernels, ϕ(ω,⋅)3 is finite if and only if the smoothness parameter ϕ(ω,⋅)4; otherwise, the feature map is not Lipschitz continuous.
Numerical Investigation and Open Questions
A persistent open question addressed is the asymptotic behavior of the Lipschitz constant for empirical random feature maps ϕ(ω,⋅)5 (with ϕ(ω,⋅)6 features) as ϕ(ω,⋅)7. The paper empirically investigates whether ϕ(ω,⋅)8 converges to the analytically computable ϕ(ω,⋅)9 derived for the infinite feature case.
Using Monte Carlo evaluation and quantile analysis for three representative kernels (Gaussian RFF, ReLU neural networks, Matérn RFF), the experimental results confirm convergence in probability of Lip(ϕ(ω,⋅))0 to Lip(ϕ(ω,⋅))1 with increasing Lip(ϕ(ω,⋅))2, supporting the theory that these explicit formulas accurately govern not only the integral kernel but also its finite approximations in high dimensions.
Implications and Future Directions
The formal expressions for the Lipschitz constant derived in this article have both practical and theoretical significance. Practically, they provide rigorous certificates of robustness for kernel-based predictors—directly bounding the adversarial contraction or expansion exerted by the learned representation. Theoretically, the equivalence between moment finiteness (second-order for weight distributions) and Lipschitz continuity of the feature map identifies an intrinsic link between kernel smoothness and robustness properties.
These results further inform the design of robust, scalable kernel machines using random feature approximations, privileging kernel and random projection constructions with analytically tractable and minimal Lipschitz constants. The explicit dependence on covariance and Hessian spectral properties also opens avenues for spectral kernel parameterization.
Future research could look at sharp finite-sample concentration results for empirical Lipschitz constants, generalizations to deeper neural tangent kernels, and computational approaches to estimating Lip(ϕ(ω,⋅))3 for non-integral or non-differentiable kernels.
Conclusion
This paper establishes a rigorous and complete theory for computing Lipschitz bounds for a broad family of integral kernels, with explicit formulas covering both neural network and shift-invariant kernels. The results enable precise robustness certification for random feature models and highlight the critical dependence on kernel spectral/curvature properties and the distributional moments of random weights. The findings pave the way for principled robustness analysis and informed architecture design in kernel machines and infinite-width neural networks, with ongoing research needed to extend these guarantees to even richer kernel and neural architectures.

