- The paper introduces EMS, an adaptive framework that efficiently aggregates multi-agent LLM outputs through early stopping and reliability-based scheduling.
- It employs Agent Confidence Modeling to prioritize agents based on historical and semantic reliability, achieving a 32% reduction in inference calls.
- Experiments demonstrate that EMS maintains near full voting accuracy while significantly reducing resource use through adaptive consensus determination.
Efficient Majority-then-Stopping: Optimizing Multi-Agent LLM Voting
Majority voting is foundational for decision aggregation in multi-agent systems (MAS) driven by LLMs. Despite its robustness and theoretical guarantees, the standard paradigm where all agents reason in parallel before aggregation is computationally inefficient. Often, the majority can be established far before all agent outputs are available, leading to wasted inference calls and unnecessary resource expenditure.
The paper "EMS: Multi-Agent Voting via Efficient Majority-then-Stopping" (2604.02863) formulates the aggregation process as a reliability-aware scheduling problem. It proposes a framework—Efficient Majority-then-Stopping (EMS)—that adaptively selects and queries agents based on estimated task-specific reliability and terminates further inference as soon as a majority consensus is reached. The approach draws inspiration from Byzantine Fault Tolerance, emphasizing early consensus and resource conservation without sacrificing accuracy.
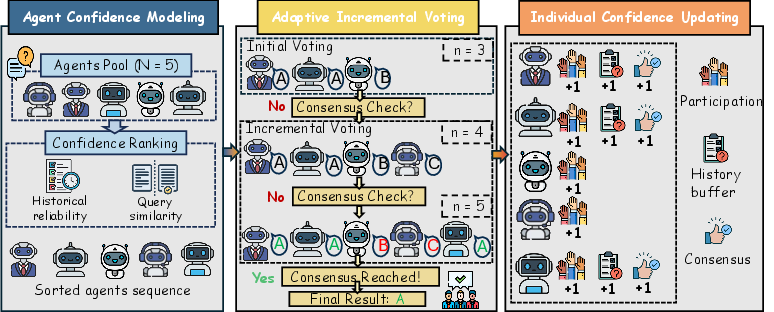
Figure 1: Overview of the EMS framework showing Agent Confidence Modeling (ACM), Adaptive Incremental Voting (AIV), and Individual Confidence Updating (ICU) stages for each query.
EMS Framework and Component Analysis
Agent Confidence Modeling (ACM)
EMS integrates robust agent scheduling via ACM, estimating reliability using two strategies:
- Historical Reliability: Agent-level global accuracy, measured as the proportion of votes aligning with previous consensus.
- Semantic Reliability: Query-adaptive similarity, computed as the mean embedding similarity between the current query and queries where the agent previously agreed with the consensus.
Confidence scores Si,j are computed per agent-query pair and globally sorted to establish a reliability-aware voting order. This dynamic prioritization is critical to reduce the expected number of invocations while increasing the probability that early votes yield consensus.
Adaptive Incremental Voting (AIV)
The voting order determined by ACM allows sequential querying of agents. EMS begins with the minimum quorum size τ=⌈(N+1)/2⌉, invoking the most reliable agents, and at each step checks for majority consensus. If consensus is not reached with the initial set, further agents are added incrementally until the majority threshold is satisfied.
This adaptive early-stopping mechanism—AIV—exploits the statistical independence and diversity of agent reasoning, operationally formalized as:
- Each query: Invoke agents in sorted order until a consensus answer is supported by τ votes;
- If consensus is unreachable, fallback to full ensemble voting.
Individual Confidence Updating (ICU)
Post voting, participating agents update their confidence states—counters for participation and correct votes, as well as semantic history buffers. This enables continual improvement in agent scheduling, leveraging online feedback from each voting episode. Agents not invoked retain previous states; invoked agents add query embeddings when their response aligns with the consensus.
Empirical Evaluation and Numerical Results
EMS is evaluated across six benchmarks: mathematical reasoning (AQuA, Math500, GSM8K), general knowledge (MMLU, GPQA, CommonsenseQA), using a heterogeneous pool of nine leading LLMs spanning OpenAI, Google, Anthropic, DeepSeek, Meta, and Alibaba.
- EMS achieves substantial reduction in average number of agent invocations (from 9.0 to approximately 6.1), corresponding to a 32% reduction in inference cost.
- Accuracy preservation: EMS variants (EMS-Rel, EMS-Sim) retain nearly all accuracy improvements of full ensemble voting (86.38% vs. 86.61% for Weighted MV).
- Early stopping enabled by reliability-informed agent order avoids performance degradation observed in naive truncation strategies; consensus-based stopping is essential to maintain accuracy.
(Figure 2)
Figure 2: Distribution of the number of agents invoked per query under AIV across benchmarks, indicating a high proportion of queries resolved with the initial agents.
Ablation and Scalability Analysis
Heuristic baselines (Random ES, Fixed Random-5, Fixed Top-5) illustrate the importance of informed agent ordering and consensus checking. Specifically:
- Random ordering with early stopping (Random ES) achieves similar accuracy as full voting but slightly higher inference cost than EMS.
- Without consensus verification, accuracy dramatically degrades (e.g., Fixed Random-5).
- Historical reliability sorting (EMS-Rel) outperforms query-adaptive semantic sorting (EMS-Sim) in efficiency.
The scaling analysis demonstrates that as agent pool size N increases, accuracy gains diminish, and EMS’s early-stopping keeps invocation cost nearly stable—a desirable property for practical deployment in large-scale MAS.
Practical and Theoretical Implications
EMS addresses the central inefficiency in multi-agent LLM reasoning: it decouples inference cost from agent pool size, fundamentally shifting the operational paradigm from full ensemble redundancy to adaptive consensus-driven computation. By integrating reliability signals and sequential majority-checking, EMS enables:
- Substantial reduction in LLM API calls, critical for cost-sensitive or latency-sensitive applications.
- Preservation of accuracy benefits derived from ensemble diversity.
- Foundational groundwork for future dynamic scheduling protocols—potentially incorporating reinforcement learning, meta-learning, or more sophisticated agent-level feedback.
From a theoretical perspective, EMS connects classical distributed consensus (Byzantine quorum) with modern agent-based LLM inference, potentially catalyzing new research on minimax-optimal aggregation, robustness under adversarial or heterogeneous agents, and fairness in scheduling.
Conclusion
The Efficient Majority-then-Stopping (EMS) framework provides a principled solution for resource-efficient MAS aggregation—leveraging dynamic, reliability-aware agent ordering and adaptive early stopping without loss of accuracy (2604.02863). Its modular architecture (ACM, AIV, ICU) generalizes naturally to diverse multi-agent settings and paves the way for advances in scalable, intelligent coordination among LLMs.
Key directions for future research include exploration of richer confidence modeling, agent specialization signals, and integration with advanced scheduling techniques, as well as real-world deployment and benchmarking on large agent systems and dynamic environments.