- The paper introduces a new task formulation and SYSU-CMCC dataset to study person re-identification under simultaneous modality discrepancy and clothing variations.
- It proposes the Progressive Identity Alignment Network (PIA) with Dual-Branch Disentanglement Learning and Bi-Directional Prototype Learning to tackle these challenges.
- Experimental results on SYSU-CMCC demonstrate significant improvements, achieving Rank-1 rates of 57.0% for V2I and 50.4% for I2V retrieval.
The paper introduces Cross-Modality Clothing-Change Re-Identification (CMCC-ReID), addressing pedestrian matching across both modality discrepancy (visible–infrared) and clothing variation in surveillance conditions. Unlike previous VI-ReID or CC-ReID settings, CMCC-ReID reflects realistic scenarios where appearance changes due to both lighting conditions and outfit transitions co-occur. The authors highlight that existing solutions generalize poorly under such compound heterogeneity, as they focus on disjoint factors and treat modality and clothing as mutually exclusive challenges.
To support CMCC-ReID, the SYSU-CMCC dataset is constructed by integrating SYSU-MM01 (infrared images) and PRCC (visible images) while ensuring clean, identity-consistent pairing across modalities and distinct clothing per identity. The benchmark contains 214 identities and 18,375 images spanning visible and infrared spectra with non-overlapping outfits, offering paired V2I and I2V retrieval protocols for evaluating cross-modality, clothing-change Re-ID.
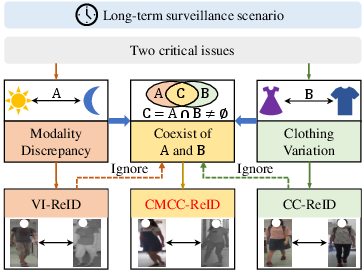
Figure 1: CMCC-ReID is motivated by the coexistence of modality discrepancy and clothing variation in real-world long-term surveillance.
Challenges in CMCC-ReID: Feature Degradation and Misalignment
Two central issues arise in CMCC-ReID. First, in the infrared domain, degraded visual cues hinder the extraction of identity features invariant to clothing, as standard methods are tailored to high-contrast visible settings. Second, implementing direct modality alignment—without addressing clothing as a noisy confounder—can degrade Re-ID efficacy by encouraging networks to latch onto clothing artifacts across spectral domains.
The paper provides empirical visualizations demonstrating that established architectures, such as CAL or SAAI, either produce heatmaps improperly dominated by clothing or exhibit counterproductive alignment when subjected to dual heterogeneity. Only after explicit clothing interference mitigation does modality alignment improve identity discrimination.
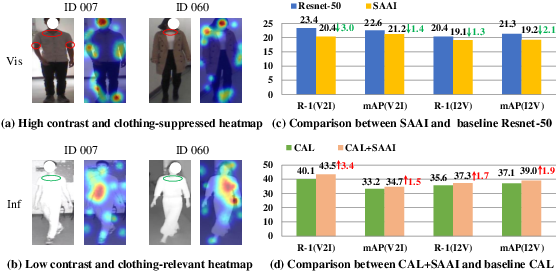
Figure 2: Illustration of modality and clothing-related issues in CMCC-ReID with visualizations of attention maps and comparative module performances.
The Progressive Identity Alignment Network (PIA)
To resolve these challenges, the authors propose the Progressive Identity Alignment Network (PIA), which employs a two-stage learning strategy:
Stage I: Clothing interference is suppressed via a Dual-Branch Disentanglement Learning (DBDL) module, which employs spatial attention to construct orthogonal subspaces for identity- and clothing-related features in both modalities. The orthogonality constraint enforces explicit semantic separation, leveraging a learnable suppression coefficient to retain informative details while minimizing clothing-induced noise.
Stage II: Robust, modality-consistent alignment is achieved with a Bi-Directional Prototype Learning (BPL) module. BPL maintains momentum-updated prototypes for each identity per modality, utilizing ProtoNCE-based intra-modality compactness and cross-modality prototype contrast to bridge the spectral gap and refine identity consistency. The training strategy alternates: DBDL is first optimized in isolation, then DBDL and BPL are jointly updated after an empirically optimized epoch.
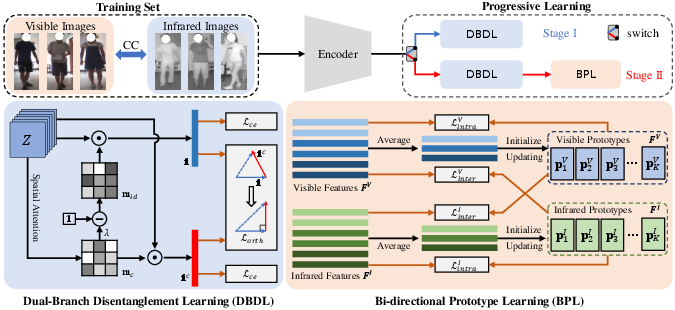
Figure 3: PIA architecture overview, highlighting DBDL for disentanglement and BPL for bidirectional prototype-based alignment.
Experimental Evaluation and Ablations
PIA is comprehensively evaluated on SYSU-CMCC, surpassing state-of-the-art VI-ReID and CC-ReID methods by significant margins under both V2I and I2V settings. Specifically, PIA achieves 57.0%/46.5% (Rank-1/mAP) for V2I and 50.4%/50.3% for I2V—indicating robust performance under compounded heterogeneity and establishing a strong baseline for future work in CMCC-ReID.
Ablation studies validate all PIA components. DBDL with orthogonality outperforms standard baselines, particularly in reducing semantic entanglement between identity and clothing. BPL’s intra-modality and inter-modality prototype losses incrementally increase both Rank-1 and mAP. The progressive training scheme is crucial, yielding optimal performance when cross-modality alignment is applied to already purified features. Hyperparameter sensitivity is minimal, and the architecture demonstrates stable training dynamics across a spectrum of parameter settings.
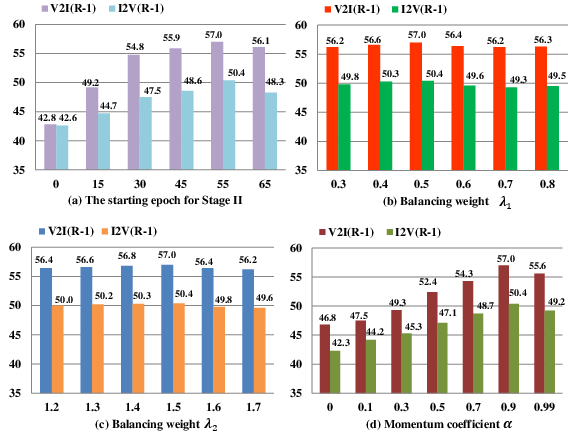

Figure 4: Hyperparameter analysis demonstrating the impact of learning stage timing and loss weights.
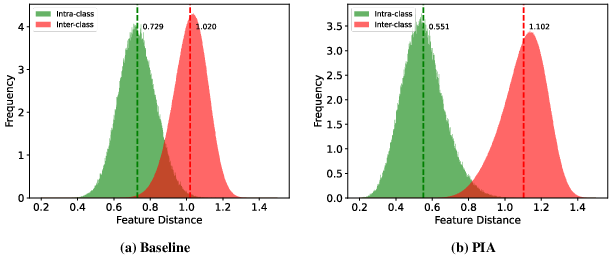
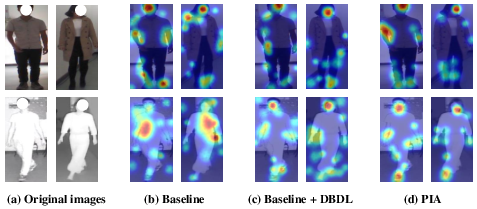
Figure 5: Cosine distance distributions of positive and negative pairs reveal increased separability with PIA.
Visualizations and Qualitative Analysis
Qualitative retrieval comparisons confirm that PIA retrieves more correct identities in the top-ranked positions than variants, substantiating superior discrimination across both modalities and clothing changes. Feature analysis of cosine distances shows increased inter-class divergence and reduced intra-class distance post-PIA. Attention map visualization exhibits progressive reduction of background and clothing-related activations, culminating in compact, identity-centric localization for both visible and infrared inputs.
Practical and Theoretical Implications
PIA, by jointly addressing modality and clothing heterogeneity, provides a blueprint for robust, deployable person Re-ID systems in long-term, real-world surveillance. Its modular progressive design suggests extensibility: future work may adapt the dual-branch disentanglement strategy to other compound confounders or extend prototype-based contrastive alignment to unsupervised or semi-supervised settings. The SYSU-CMCC benchmark further catalyzes research in this compounded domain, exposing the inadequacy of isolated solutions and incentivizing unified approaches.
Conclusion
The paper establishes a novel task—CMCC-ReID—with a corresponding scalable dataset and an effective reference architecture. PIA’s progressive learning paradigm, employing disentanglement and cross-modality prototype alignment, yields consistent improvements over both VI-ReID and CC-ReID paradigms. The methodology and empirical findings offer a principled direction for developing person Re-ID solutions capable of operating in unconstrained, long-term deployment scenarios, motivating future research on multi-factor disentanglement and adaptive alignment strategies (2604.02808).