- The paper introduces a dual-branch architecture combining RGB appearance with clothing-invariant structural features to address drastic clothing changes.
- It employs a quality-aware query-adaptive convolution with pixel-level weighting and bidirectional matching to enhance similarity estimation.
- Experimental results show significant gains in Rank-1 accuracy and mAP across datasets, confirming the approach's robustness under clothing variations.
QA-ReID: Quality-Aware Query-Adaptive Convolution Leveraging Fused Global and Structural Cues for Clothes-Changing ReID
Introduction
Clothes-changing person re-identification (CC-ReID) confronts drastic image appearance variance induced by alterations in clothing, severely impairing traditional appearance-based matching. The framework introduced in "QA-ReID: Quality-Aware Query-Adaptive Convolution Leveraging Fused Global and Structural Cues for Clothes-Changing ReID" (2601.19133) advances CC-ReID by integrating global RGB and clothing-invariant structural features and proposing a quality-aware, pixel-level, query-adaptive matching module. This approach directly addresses the limitations of previous fusion and matching strategies, explicitly focusing on feature robustness and fine-grained similarity estimation under significant appearance shifts.
Methodology
Dual-Branch Feature Extraction and Multi-Modal Fusion
The architecture employs a dual-branch structure, processing the input RGB image alongside a human parsing-derived segmentation to extract appearance-agnostic, body-structure-centric features. The human parsing branch masks out non-identity-related regions (primarily clothing), producing a "clothing-invariant" image that accentuates physical biometric cues. Features from both branches are then subjected to a multi-modal attention fusion module that applies learned channel and spatial attention, adaptively emphasizing informative cues according to image context:
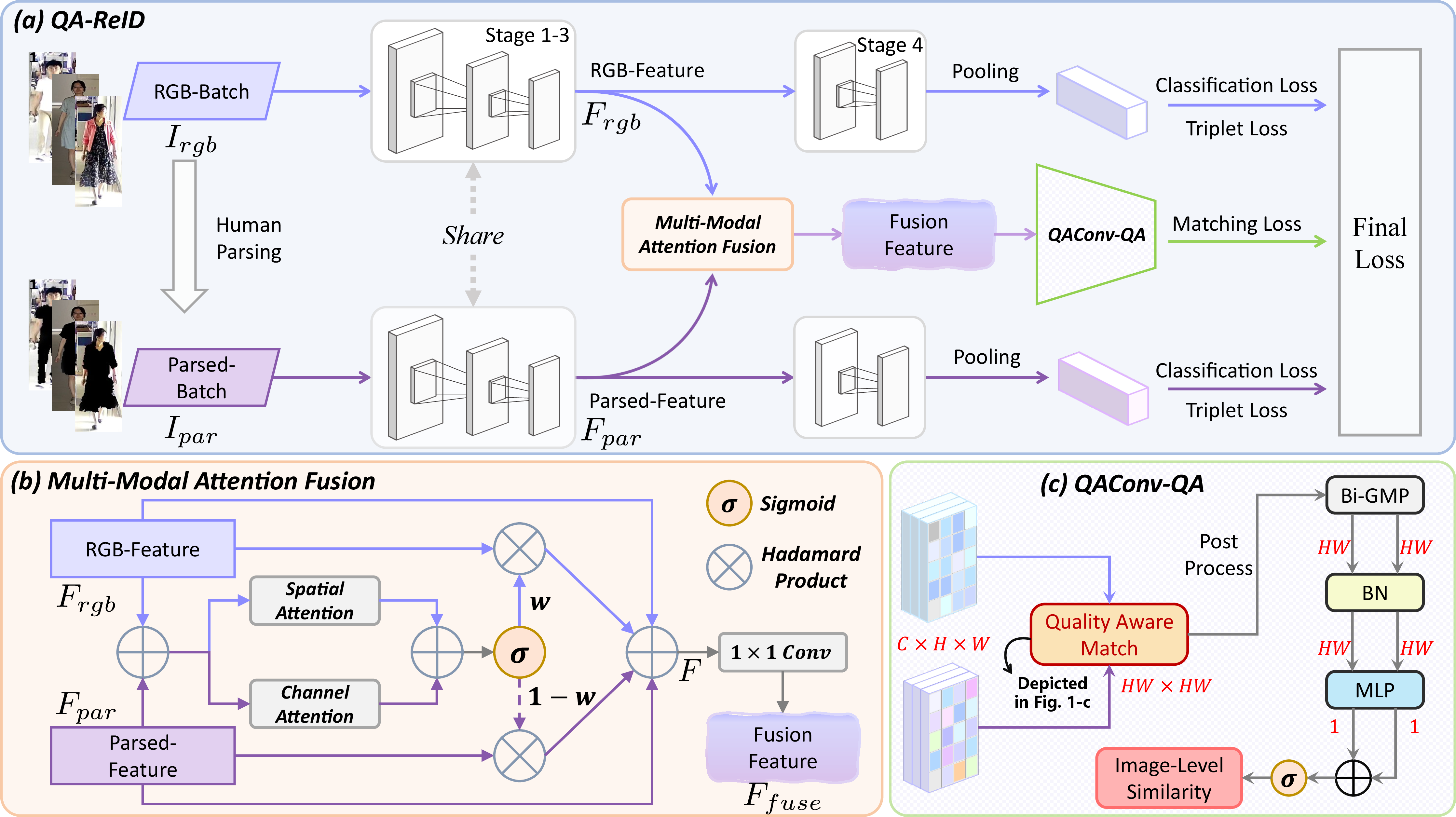
Figure 1: The QA-ReID dual-branch mechanism combines RGB and parsing-based representations through multi-modal attention fusion, followed by quality-aware query adaptive convolution for similarity computation.
This fusion is realized by constructing a weight map that mediates pixel and channel-level aggregation, ensuring the resulting feature map preserves balanced contributions from both sources. Finally, the concatenated and fused feature maps are refined via a 1×1 convolution to yield the discriminative representation for downstream matching.
Quality-Aware Query-Adaptive Convolution (QAConv-QA)
The central innovation occurs during matching. Unlike vanilla QAConv, which operates on query-image-driven dynamic convolutions at the pixel level, QAConv-QA introduces quality-aware pixel weighting and a bidirectional matching constraint. Each position in the fused feature map receives a quality score reflecting its expected relevance to identity cues (e.g., head, limbs vs. clothing or background). This weight is normalized and directly modulates local similarity calculations.
Moreover, the bidirectional matching design evaluates pixel-pair similarities in both query-to-gallery and gallery-to-query directions. Only pairs demonstrating high consensus contribute to the final similarity score, accumulated through bidirectional global-max pooling (Bi-GMP) and further refined with normalization and an MLP-sigmoid post-processing stack:
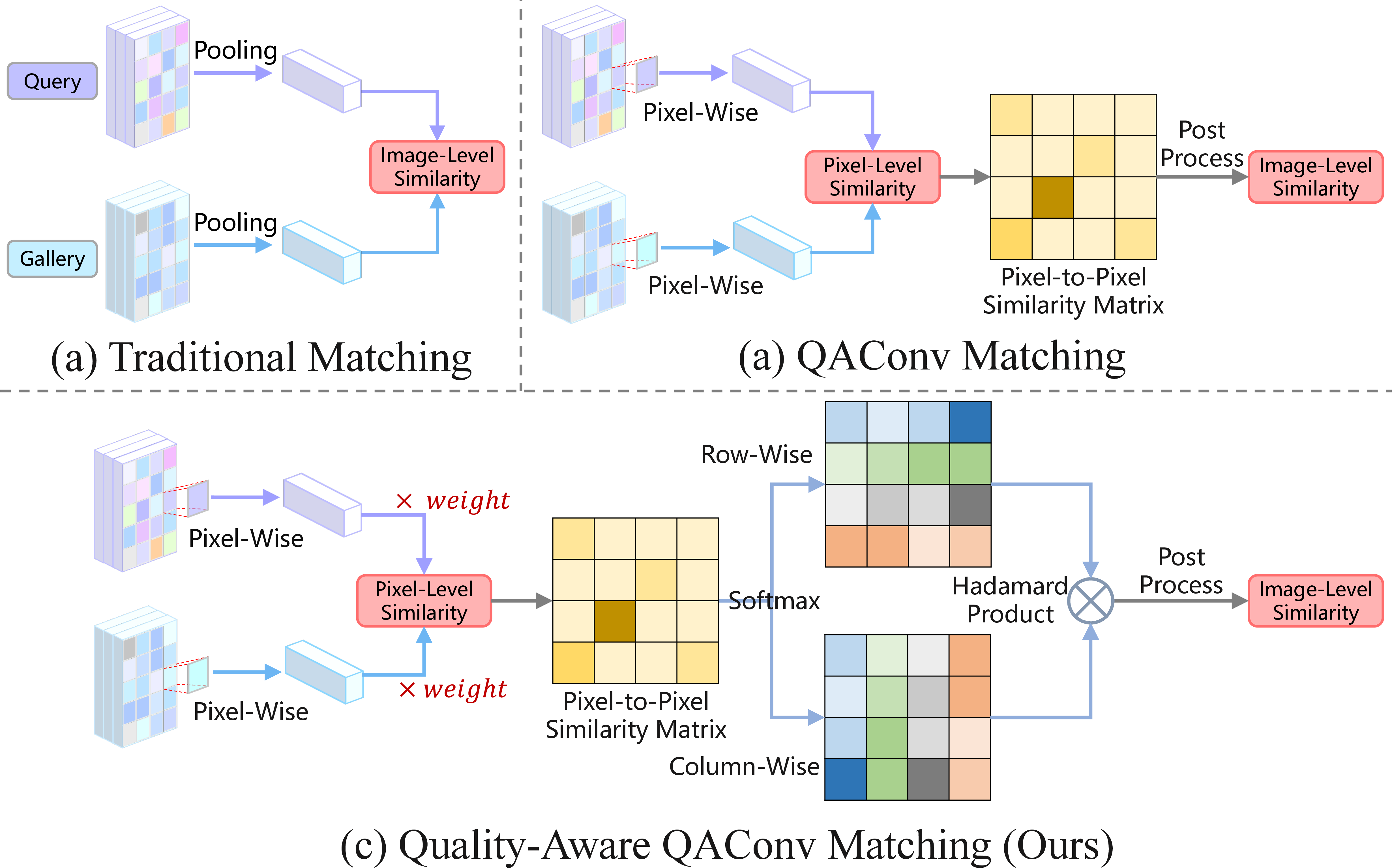
Figure 2: (a) Traditional global matching, (b) QAConv-based local matching, and (c) the proposed quality-aware, pixel-adaptive QAConv-QA.
This dual constraint mechanism substantiates robust similarity measurement under the expected appearance volatility in CC-ReID.
Multi-Task Loss
The framework is trained with a composite loss: cross-entropy on ID prediction (from both branches), triplet ranking loss to maximize inter-class separation in the embedding space, and a pairwise binary cross-entropy matching loss supervising the QAConv-QA similarity scores. This joint optimization enforces feature discriminability, robust intra-class matching, and resilience to clothing-induced feature drift.
Experimental Results
Comprehensive evaluation on PRCC, LTCC, and VC-Clothes datasets demonstrates dominant performance across all CC protocols. QA-ReID yields clear, consistent gains in Rank-1 and mAP under the challenging clothing-changing test cases and matches or exceeds sota in same-clothing and general scenarios. On VC-Clothes, for instance, the Top-1 accuracy reaches 86.3% (mAP: 86.1%), and PRCC and LTCC results similarly surpass prior systems (2601.19133).
Ablation studies confirm the complementary contribution of the parsing branch and the multi-modal attention fusion. Critically, integrating QAConv-QA delivers further substantial improvements regardless of the feature backbone, with pixel-level weighting and bidirectional consistency both indispensable for maximal performance.

Figure 3: Attention maps on LTCC reveal the model’s suppression of clothing and focus on biometric cues, outperforming the baseline method CAL.
Visualization demonstrates that, relative to strong RGB-based methods such as CAL, QA-ReID selectively activates on anatomical regions invariant to clothing, confirming effective disentanglement of identity from attire.
Implications and Future Outlook
The dual-branch, attention-fused, quality-aware matching established here refines the solution space for CC-ReID, introducing explicit handling of pixel-level reliability and bidirectionality often overlooked in prior art. The modularity of QAConv-QA suggests adaptability to other tasks involving high intra-class variance and partial occlusion.
Future developments could focus on computational optimization for deployment in real-time or large-scale surveillance, extending the fusion methodology to mesh or gait features, or unifying with vision-LLMs for constraint-rich open-world identification scenarios. Lightweight adaptation and explicit domain generalization, tightly coupled with the parsing-driven fusion, have potential to further broaden applicability in unconstrained environments.
Conclusion
QA-ReID systematically addresses the intrinsic challenges of clothing-changing person ReID through joint exploitation of global and parsing-driven structural features and deployment of a pixel-level, quality-weighted, bidirectionally consistent matching mechanism. Empirical results confirm robust SOTA performance under severe appearance changes, establishing a rigorous foundation for future CC-ReID and cross-domain identity matching research.