- The paper introduces product-stability—a novel criterion using third and fourth derivatives—to guarantee GD convergence in regimes where loss sharpness exceeds classical thresholds.
- The analysis leverages bifurcation diagrams to reveal a three-phase dynamic in gradient descent, demonstrating convergence even for practical losses such as cross-entropy.
- Both analytical proofs and empirical experiments validate that product-stability unifies and extends convergence guarantees in overparameterized, non-convex deep learning settings.
Product-Stability and Edge-of-Stability Convergence in Gradient Descent
Overview
The paper "Product-Stability: Provable Convergence for Gradient Descent on the Edge of Stability" (2604.02653) addresses the convergence dynamics of gradient descent (GD) in the Edge of Stability (EoS) regime—where the sharpness λ of the loss exceeds classical convergence thresholds—but in a significantly broadened functional and practical context. The work introduces the notion of product-stability for minima of univariate loss functions and establishes that, for objectives of the form L(x,y)=l(xy), this property ensures provable convergence under GD, even when classical sharpness constraints are violated. This generalizes prior work restricted to quadratic or subquadratic losses and provides a new lens for analyzing training dynamics, including for practical losses such as cross-entropy.
Motivation and Background
Traditional convergence guarantees for GD require the learning rate η to satisfy η<λ2, with λ the maximum eigenvalue of the Hessian. Empirically, however, modern overparameterized networks commonly operate in a regime where the sharpness breaches the threshold (λ>η2), resulting in non-monotonic loss trajectories with oscillating sharpness—collectively known as the EoS phenomenon [cohen2022gradient]. Existing theoretical analyses have largely focused on specific loss landscapes (notably the squared loss and its variants) and impose often strong regularity conditions, thereby leaving open the behavior for canonical classification losses such as cross-entropy.
The present work aims to provide a unified and less restrictive criterion—product-stability—that captures a wider array of loss functions and settings. This is particularly salient for understanding convergence in deep learning, where EoS is not transient but persists throughout optimizations.
Product-Stability: Definition and Implications
A key contribution is the formalization of product-stability. For a twice differentiable loss l with continuous higher derivatives, the product-stability at a point z is defined as:
αl(z)=3(l(3)(z))2−l(4)(z)l′′(z)
A local minimum z∗ is product-stable if L(x,y)=l(xy)0. This property integrates third and fourth order derivative information and fundamentally extends beyond assumptions of convexity or subquadraticity found in prior literature.
Intuitively, positive product-stability guarantees the existence of two-step fixed points for GD in the EoS regime and, crucially, governs the stability and drift of dynamics around the minimizing manifold induced by the parameterization L(x,y)=l(xy)1. Negative fourth derivatives (i.e., "subquadraticity") and large third derivatives both contribute to positive L(x,y)=l(xy)2, but neither is strictly required.
Analytical Results
Convergence Under Product-Stability
The primary theoretical result demonstrates that when L(x,y)=l(xy)3 has a product-stable minimum, GD applied to L(x,y)=l(xy)4 with learning rate L(x,y)=l(xy)5 and initial sharpness L(x,y)=l(xy)6 such that L(x,y)=l(xy)7 (i.e., starting within the EoS regime) will globally converge to a stationary point as L(x,y)=l(xy)8.
The proof consists of bounding the projection of the iterates L(x,y)=l(xy)9 onto the "output" η0 and the "sharpness multiplier" η1, demonstrating that η2 follows an adaptive learning-rate GD on η3 whose rate is governed by η4. Dynamically, the iterates initially diverge from sharp minima and are drawn toward flatter regions—a trajectory characterized using bifurcation diagrams.
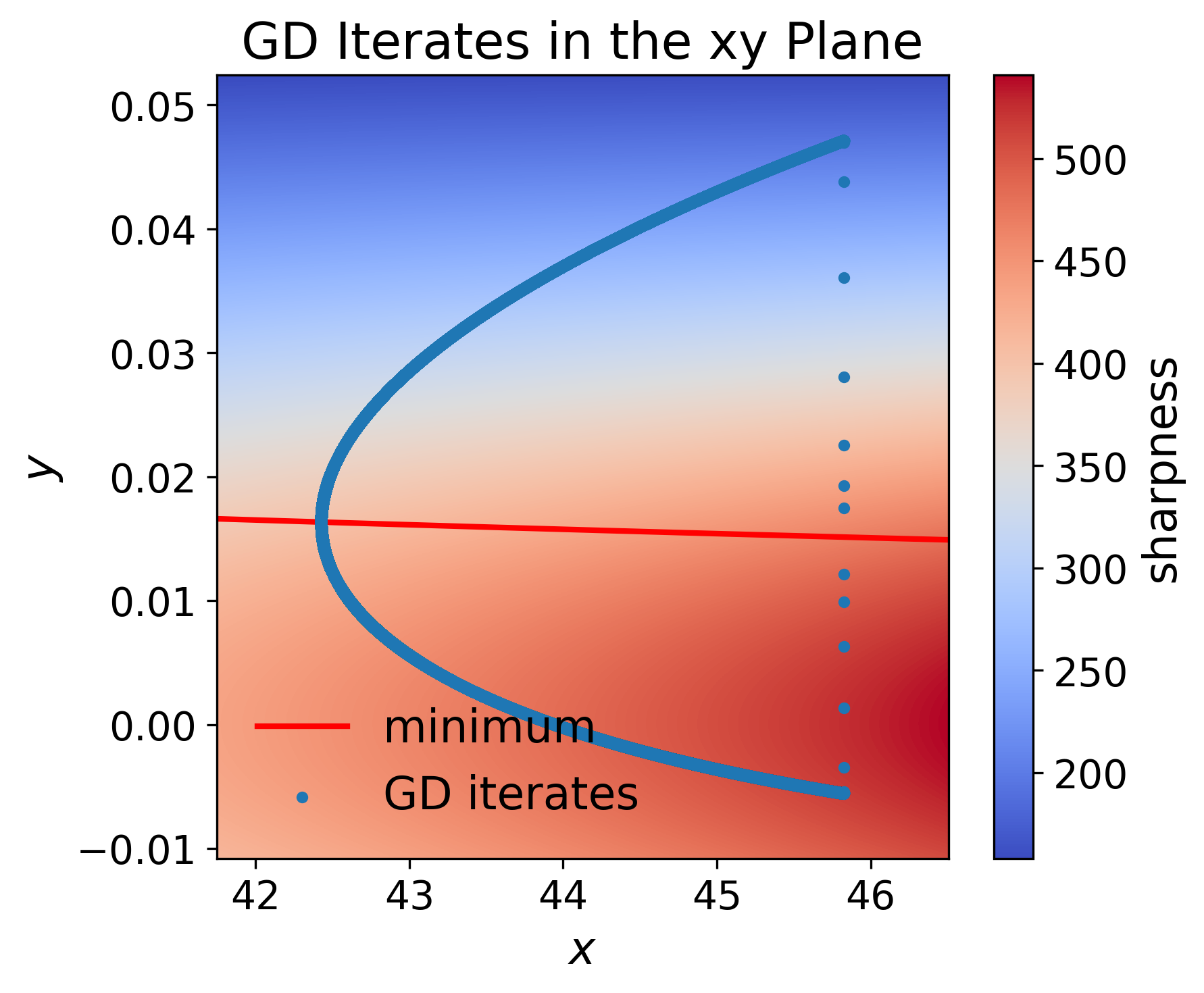
Figure 1: EoS GD dynamics in the η5-plane: iterates start near a sharp minimum and drift toward flatter minima, consistent with the adaptivity of sharpness.
Bifurcation Dynamics
The analysis exploits bifurcation diagrams, mapping the learning rate to the loci of two-step fixed points. This framework reveals that, generically, GD trajectories in EoS exhibit three phases:
- Phase I: Rapid approach toward the bifurcation diagram with near-constant sharpness multiplier.
- Phase II: Slow drift along the diagram with decreasing sharpness multiplier, effectively reducing η6 toward the EoS threshold.
- Phase III: Final convergence to the local minimum with sharpness slightly below η7, as quantified precisely by a correction dependent on η8:
η9
The figures below illustrate the loss, sharpness, and phase space evolution for multilayer squared (MLSq) and binary cross-entropy (BCE) losses, both of which are shown to be product-stable.
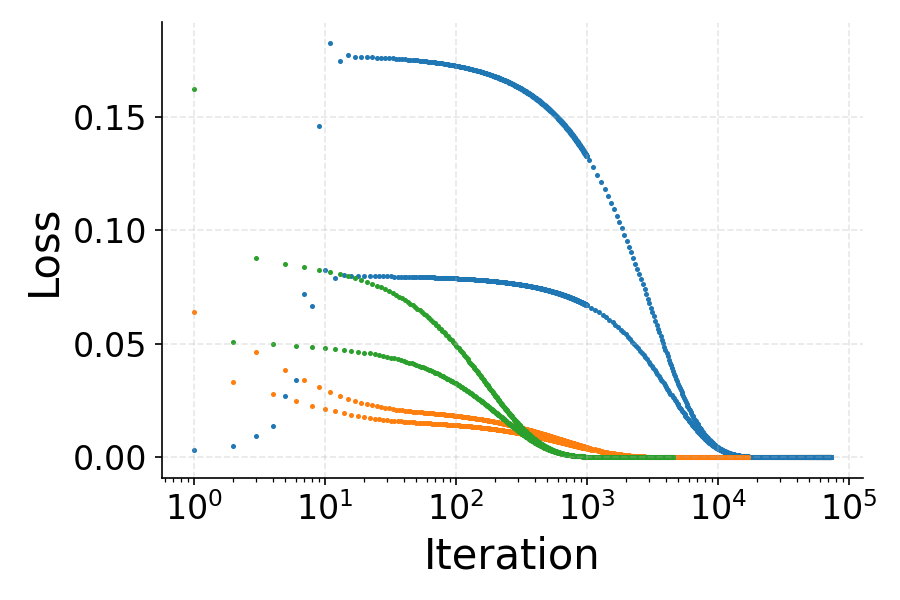
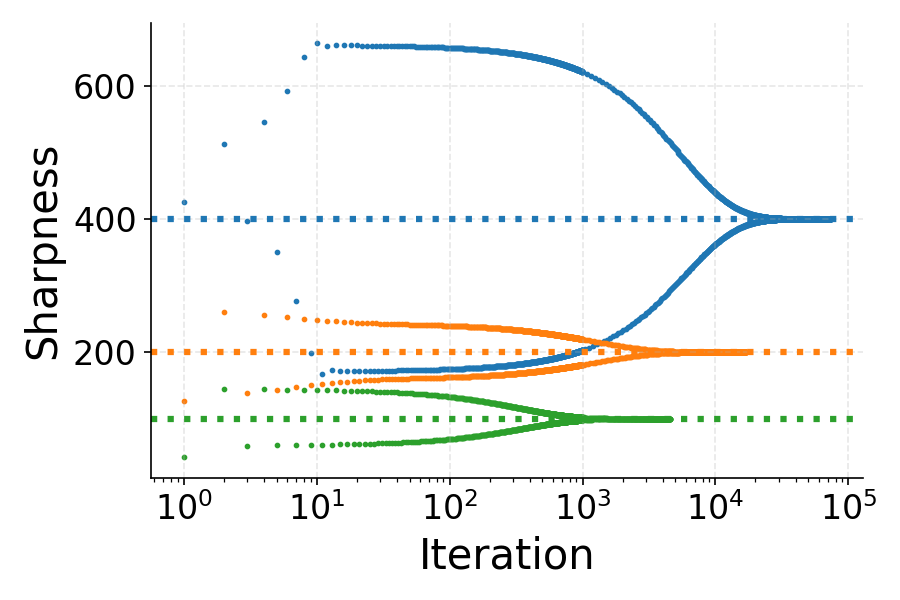
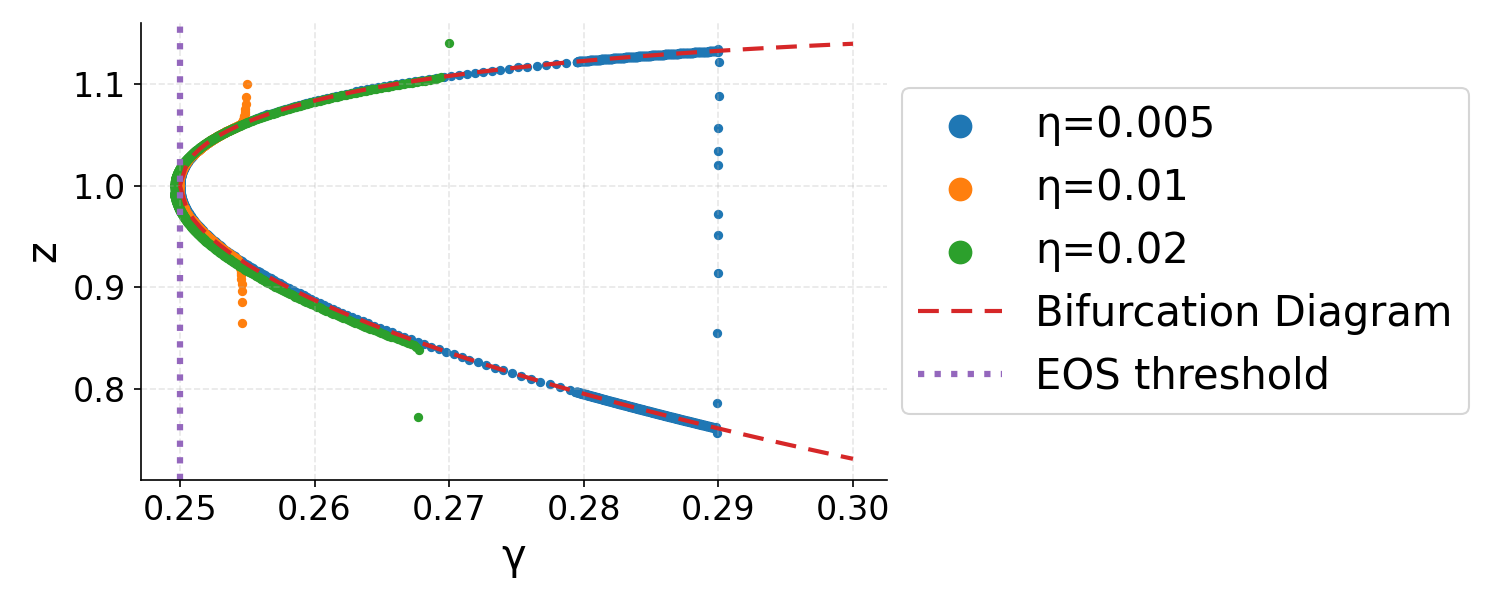
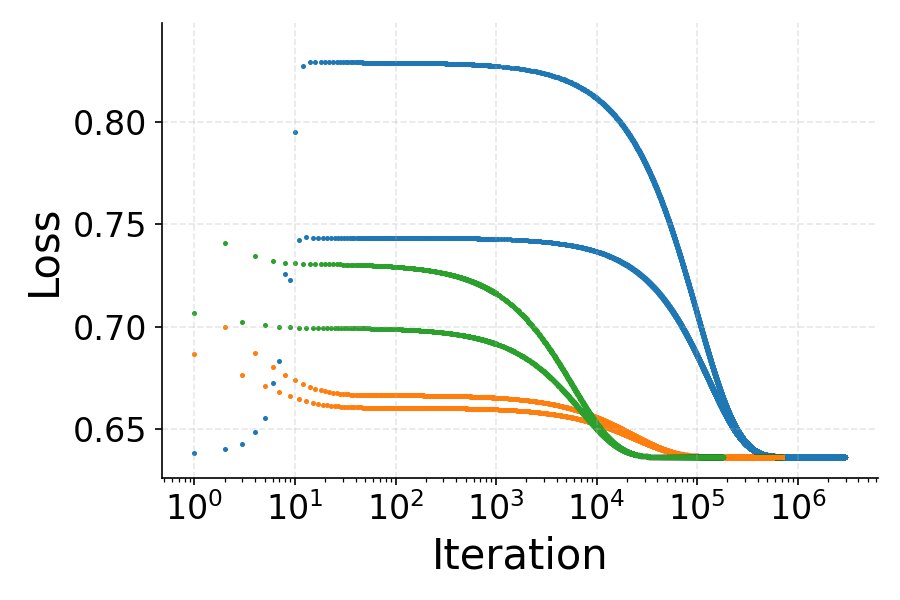
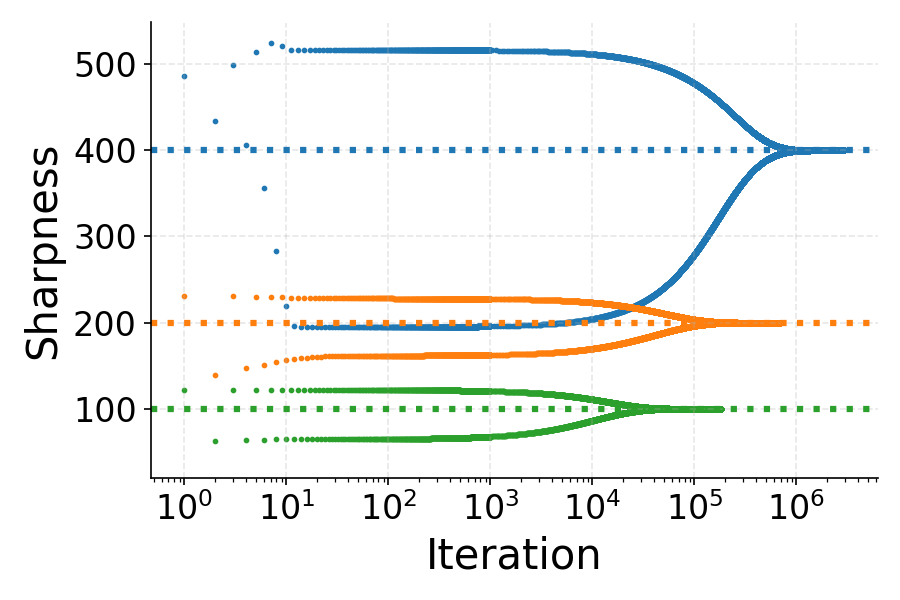
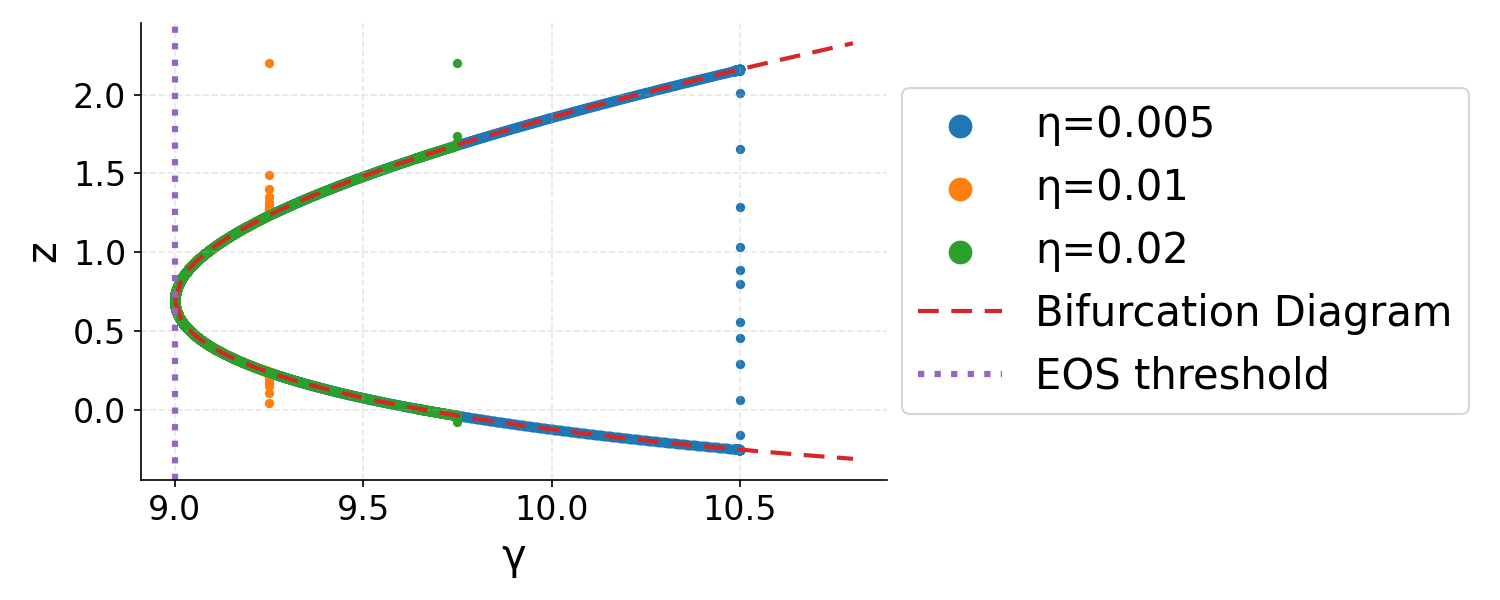
Figure 2: Loss and sharpness dynamics for MLSq and BCE losses, demonstrating oscillatory loss and sharpness convergence just below the EoS threshold.
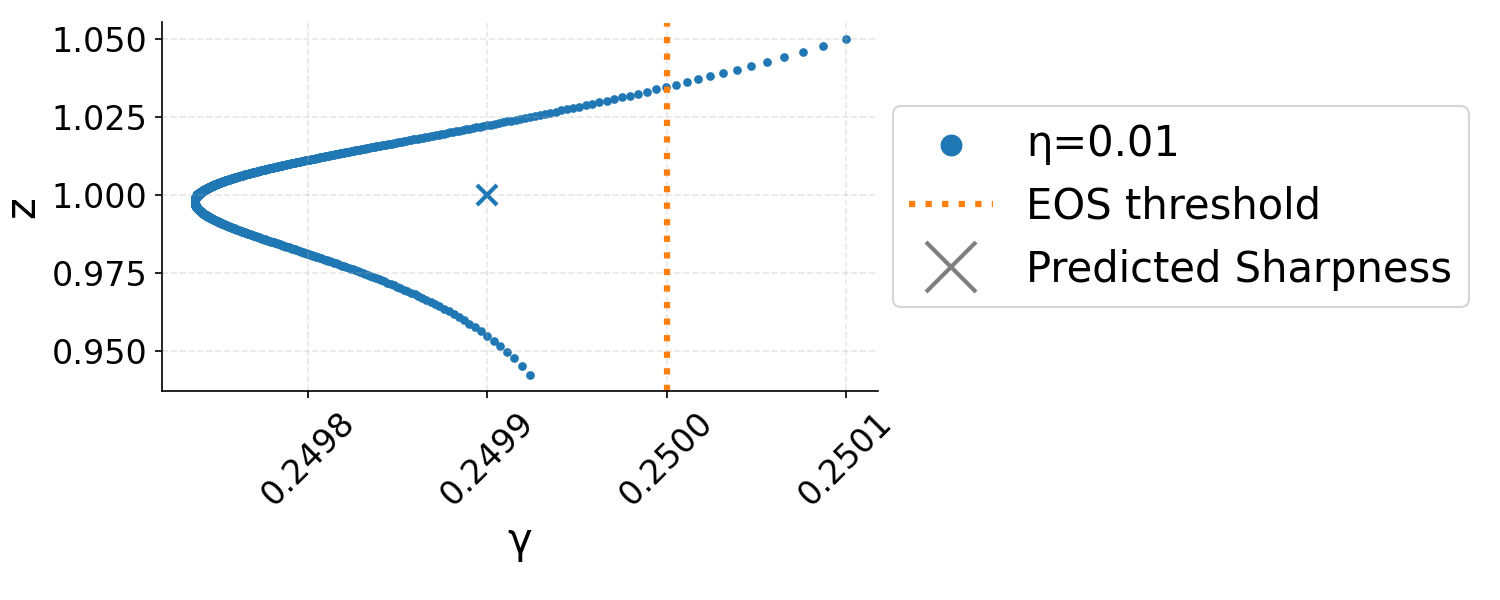
Figure 3: GD trajectories in η<λ20 phase space showing rapid approach (Phase I), drift (Phase II), and final convergence (Phase III) to stable minima.
Applicability and Generalization
- Cross-Entropy Loss: The binary cross-entropy loss is shown to be product-stable at all points. This resolves a major gap in prior EoS theory by encompassing the canonical classification objective.
- Deep Architectures: Extensions to deeper homogeneous models (e.g., multilayer losses of the form η<λ21) are covered by product-stability, generalizing earlier findings that identified depth as a key factor enabling EoS convergence [zhu2023understanding].
- General Losses: Product-stability subsumes the "subquadraticity" conditions used by [ahn2023learning] and others, and captures loss families parameterized by higher-order derivatives, including those with "good regularity" as defined in [wang2023good].
Empirical Validation
Experiments with overparameterized fully-connected architectures trained on CIFAR-10 demonstrate that GD in real-world models displays EoS oscillations and stable convergence when the multivariate extension of product-stability is positive along principal Hessian directions.
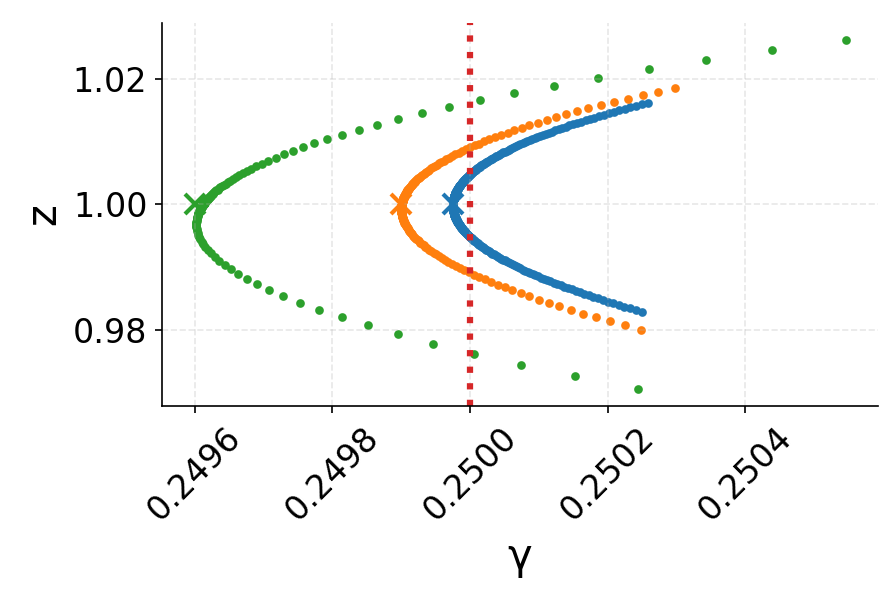
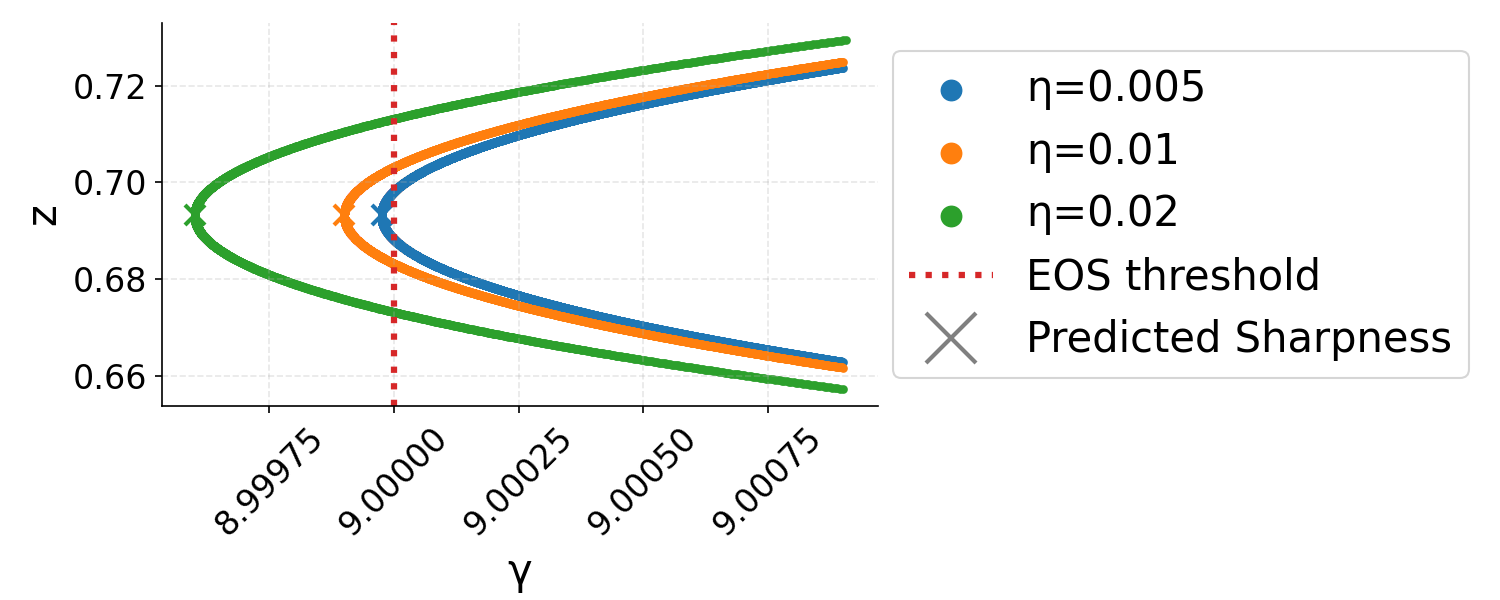
Figure 4: Empirical dynamics for a fully-connected tanh network: (a) training loss oscillations, (b) sharpness tracking the EoS threshold, (c) positive product-stability during EoS regime.
Loss oscillations within the EoS regime are shown in detail to further corroborate the qualitative training behavior.
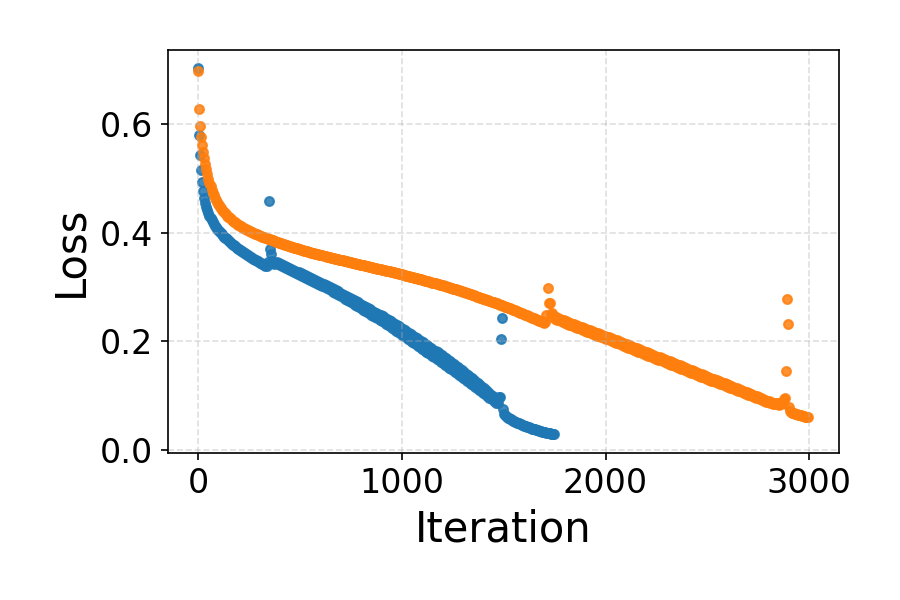
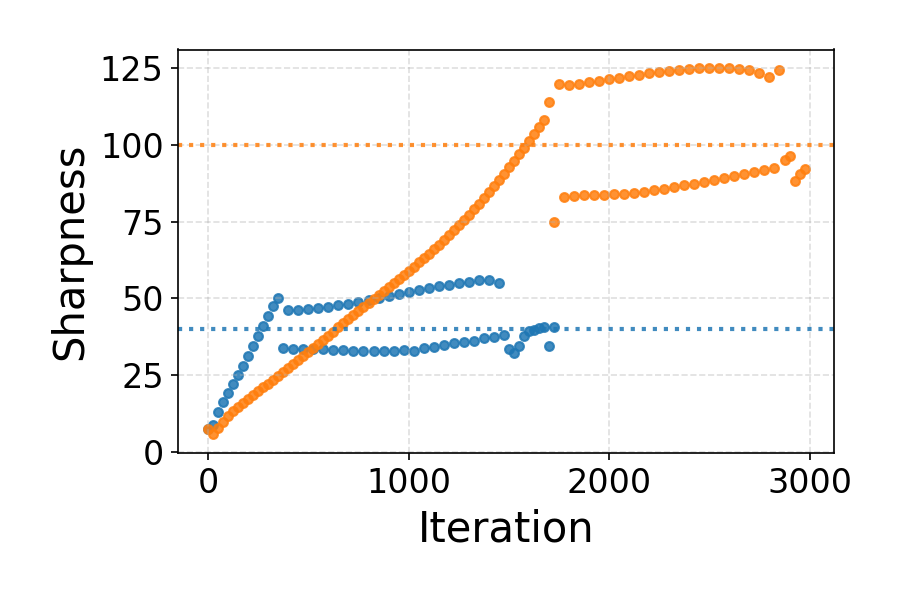
Figure 5: Zoom-in of oscillatory loss dynamics during the EoS regime for a deep network.
Implications and Future Directions
This work provides a principled, unifying framework for understanding the convergence and stability of GD on a broad class of deep learning objectives under the empirically observed EoS regime. The product-stability criterion:
- Enables analysis of convergence for practical classification losses (notably cross-entropy) which were previously out of scope.
- Clarifies the role of higher-order derivatives and depth-like parameterizations on EoS behavior.
- Justifies the sharpness adaptivity phenomenon, with explicit analytic correction terms for the limiting sharpness.
- Extends, unifies, and relaxes prior theoretical frameworks that depended on symmetry, convexity, or subquadraticity.
Potential future work includes:
- Global (rather than local) analysis of GD dynamics under product-stability, addressing how and when iterates enter the EoS regime.
- Systematic study of how (and if) practical deep networks' loss landscapes satisfy the product-stability condition in high dimensions.
- Application of these insights to design new optimization algorithms or regularizers informed by product-stability-based landscape analysis.
Conclusion
The introduction and analysis of product-stability provides a comprehensive explanation for the empirical robustness of EoS training across a spectrum of loss functions relevant to deep learning. By characterizing convergence, oscillatory dynamics, and sharpness adaptation in the EoS regime, this work both generalizes and strengthens theoretical understanding, opening new avenues for rigorous optimization analysis and algorithmic innovation in overparameterized settings.