- The paper introduces a novel LLM-based method that uses semantic mapping to combine CAPEC and CWE contexts, generating contextual code samples.
- It employs prompt engineering and orchestration with LangChain to create working code in Java, Python, and JavaScript with high compilability and relevance.
- Evaluations demonstrate >90% compilability and strong model consistency, making the dataset valuable for secure coding education and ML-based vulnerability detection.
Authoritative Summary: Code Generation Using LLMs for CAPEC and CWE Frameworks
Motivation and Context
Large-scale, real-world software systems increasingly demand robust identification and mitigation mechanisms for security vulnerabilities. While MITRE's CAPEC and CWE frameworks provide comprehensive catalogs of attack patterns and weaknesses, they suffer from an acute shortage of practical code examples, particularly for Java, Python, and JavaScript. Approximately 40% of CAPEC entries and 47% of CWE entries lack any code samples, with JavaScript and Python especially underrepresented. This deficit impedes advanced research, instruction, and the development of automated vulnerability detection tools.
Methodology: Mapping CAPEC and CWE and LLM-Based Code Generation
The dataset construction leverages semantic mapping and prompt engineering to maximize contextual richness of prompts delivered to LLMs. CAPEC descriptions are augmented with up to five semantically similar CWE entries per CAPEC, using SBERT for similarity computation. When CAPECs lack associated CWEs or have fewer than five, additional CWEs are selected based on cosine similarity scores from SBERT, ensuring minimum context.
The prompting mechanism employs LangChain as an orchestration layer to deliver structured, informative prompts to GPT-4o, Llama-3 (70B), and Claude-3-5-sonnet. Each prompt contains CAPEC and its mapped CWEs, demanding a concise code snippet illustrating the CAPEC along with a functional annotation and description, in the specified language.
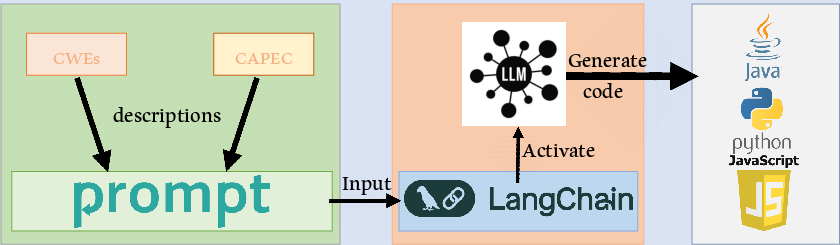
Figure 1: High-level overview of the code generation process demonstrating the pipeline from CAPEC/CWE retrieval through SBERT-based augmentation to LLM-driven code synthesis.
Token Context and Prompt Engineering
A critical consideration is the token count of inputs: simple CAPEC descriptions yield inadequate context, while augmenting with related CWE descriptions enriches semantic content, boosting generated code fidelity.
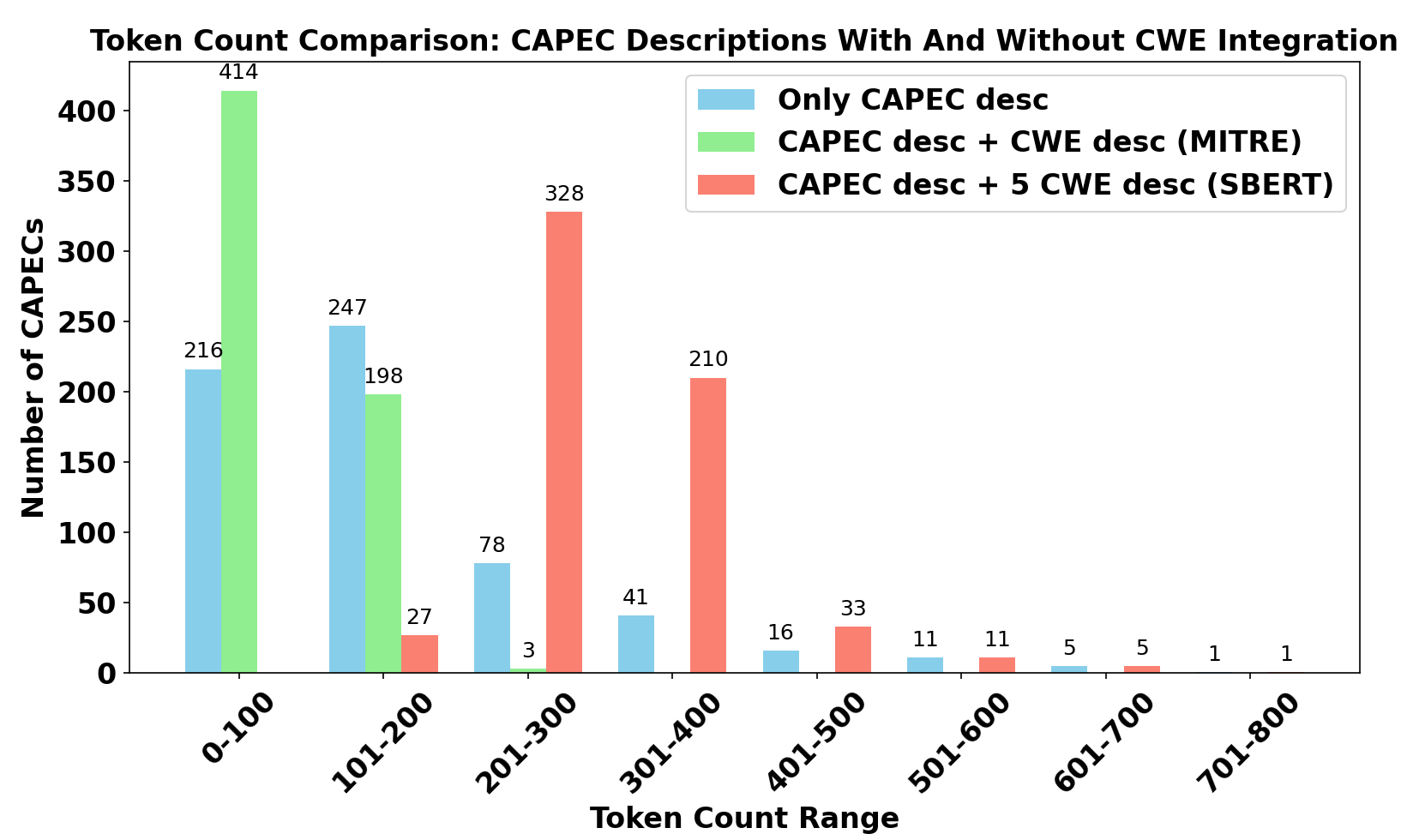
Figure 2: Token count comparison for purely CAPEC prompts versus contextually augmented prompts, verifying substantial information gain for LLM inputs.
The prompt is deliberately crafted for maximum specificity, instructing the LLM to capture the main idea of the CAPEC and integrate CWE-derived context without drifting toward generic weakness representation.
Dataset Characteristics
The resultant dataset encompasses 615 CAPEC-aligned code samples across Java, Python, and JavaScript—one of the most extensive resources of its kind.
Representative Output and Annotation
An example from the dataset for CAPEC 19 (Embedding Scripts within Scripts) demonstrates the model's capability. GPT-4o produces a Python routine that executes arbitrary scripts from file paths without access control, illustrating CWE-284 and CWE-506 implications. The accompanying description and in-code comments clarify the vulnerability and its mechanics.
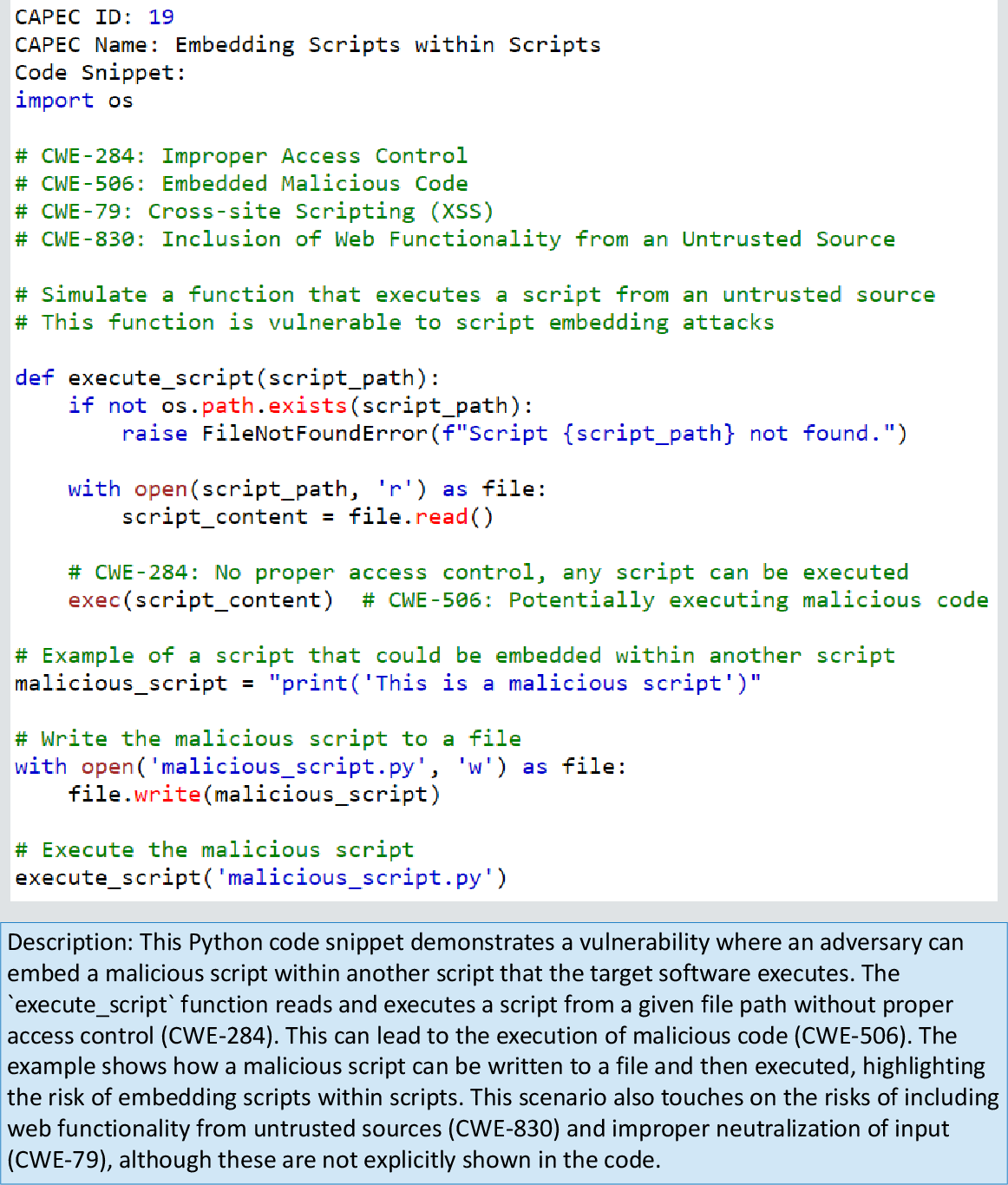
Figure 3: Example GPT-4o output for CAPEC 19, embedding scripts lacking proper access control and malicious code checks.
Evaluation and Numerical Results
Manual evaluation of randomly sampled dataset entries yielded the following:
- Compilability: >90% code successfully compiled across all languages, with Python leading.
- Relevance: Evaluators (Ph.D. CS students) marked nearly all samples as coherent and logically accurate for CAPEC representation; APA scores of 95.83%, 93.33%, and 96.67% for Java, Python, and JavaScript respectively.
- Readability: Evaluators assigned scores of 4–5 (on a 1–5 scale), with Python samples rated highest.
- Consistency: Across five independently generated datasets per language, CodeBERT-measured cosine similarity exceeded 0.98 for JavaScript, and 0.99 for Java and Python, demonstrating strong intra-model determinism.
- Cross-Model Consistency: Datasets generated by GPT-4o, Llama-3, and Claude-3-5-sonnet proved highly similar, with inter-model cosine similarities within 0.98–0.9944 for Java and marginally lower for JavaScript.
Theoretical and Practical Implications
This work bridges the gap between abstract vulnerability descriptions and concrete realizations in code, enabling:
- Enhanced training data for ML-based vulnerability detection models, fostering supervised learning and transfer learning across diverse codebases.
- Rich pedagogical resources for secure coding education, facilitating hands-on exposure to realistic vulnerability patterns.
- Improved context-driven vulnerability scanning and automated remediation strategies.
Nevertheless, the dataset includes code for CAPEC entries such as physical attacks, which have no software manifestation. CAPEC's lack of explicit software/non-software segmentation necessitates future pre-filtering for better dataset targeting.
Limitations and Future Directions
- CAPEC Filtering: Current methodology does not distinguish software-related CAPECs, generating code for irrelevant entries.
- CWE Threshold: The fixed threshold of five CWEs remains unvalidated for optimal context—future work should empirically analyze impact.
- Language Extension: The dataset presently covers only Java, Python, and JavaScript; inclusion of C/C++, Go, and others would broaden applicability.
- Real-World Integration: Future work should focus on linking these examples to real vulnerability scanners and integrating feedback loops for code correctness validation.
- Model Selection: Advanced LLMs (e.g., Claude-3 Opus) may further improve code quality, especially for complex or multi-step vulnerability cases.
Conclusion
The research presents a robust pipeline for generating practical, vulnerability-aligned code examples using contextualized CAPEC/CWE prompts and LLMs, notably GPT-4o, Llama-3, and Claude-3-5-sonnet. The resulting dataset is empirically validated for accuracy, readability, and cross-model consistency, addressing the longstanding deficiency of code examples in security vulnerability catalogs. This augmentation of the CAPEC/CWE frameworks with concrete code illustrations has substantial impact for ML-based vulnerability detection, secure coding education, and automated remediation research in software security.
Future expansion will focus on refining CAPEC filtering, optimizing CWE context, broadening language support, and tighter integration with real-world vulnerability assessment pipelines, further strengthening methodological rigor and practical relevance.