- The paper introduces a geometric occupancy measure framework that computes the exact Pareto front in average-cost MOMDPs.
- It demonstrates that deterministic policies and their convex mixtures can yield all Pareto-optimal cost vectors, overcoming limitations of scalarization.
- A numerical study on remote state estimation validates threshold-based policy efficiency and shows practical implications for nonconvex objectives.
Exact Pareto Front Computation in Average-Cost Multi-Objective Markov Decision Processes
The paper addresses the challenge of determining the exact Pareto front in average-cost multi-objective Markov Decision Processes (MOMDPs). MOMDPs model scenarios with multiple conflicting objectives, such as control-communication tradeoffs in networked systems. Each policy yields a vectorized cost, and Pareto optimality is defined as the set of policies that cannot be strictly improved in all objectives simultaneously.
Previous literature has mostly relied on scalarization, reducing multi-objective problems to a series of single-objective MDPs via linear combinations of the objectives. While computationally tractable, this approach does not recover the full Pareto front, especially when objectives interact nonlinearly or are nonconvex. The paper thus targets a fundamental limitation: for average-cost MOMDPs, how can one compute the entire Pareto front exactly, rather than approximate or select points via scalarization?
Structural Results: Occupancy Measure Polytope and Pareto Front Geometry
The core theoretical advance is a geometric characterization of the Pareto front. The paper demonstrates that, under standard assumptions (finite state and action spaces, unichain Markov transitions), the set of attainable average-cost objective vectors forms a convex polytope. Each deterministic stationary policy corresponds to a vertex of this polytope; policies at adjacent vertices differ in exactly one state. Edges between vertices represent convex mixtures (randomization in a single state), with closed-form coefficients. Every point on the Pareto front (boundary of the polytope) can be realized by stationary policies or mixtures thereof.
Formally, the occupancy measure induced by any stationary policy lies in the polytope Φ defined by normalization, balance, and nonnegativity constraints—completely characterized by linear programming. The mapping from occupancy measures to objective vectors is linear. The Pareto front is a continuous, piecewise-linear surface lying on the boundary, consisting of connected edges between deterministic policies.
For scalarized MDPs with strictly increasing (not necessarily linear) scalarization functions, the paper establishes that the optimal solutions always reside on the Pareto front and can be realized by convex combinations of at most K deterministic policies, where K is the number of objectives. This is a strong claim: computing the full Pareto front requires no explicit solution of the underlying MDPs, and nonlinear objectives are admissible as long as they are strictly increasing.
Numerical Case Study: Remote State Estimation
The theoretical results are applied to remote state estimation in a linear Gaussian system, balancing estimation error and communication rate. Each policy is parameterized as a threshold; transmission decisions depend on the elapsed time since the last update. The occupancy measure polytope allows computation of all achievable (error, rate) pairs. The study reveals that each vertex of the Pareto front corresponds to a threshold policy and that any interior point can be realized by mixing two adjacent thresholds. Significantly, for certain ranges of the scalarization weight λ, a single threshold policy uniquely attains the minimum cost over the entire interval.
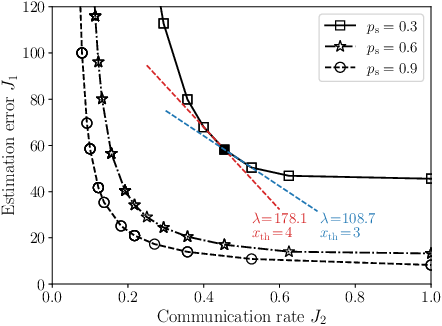
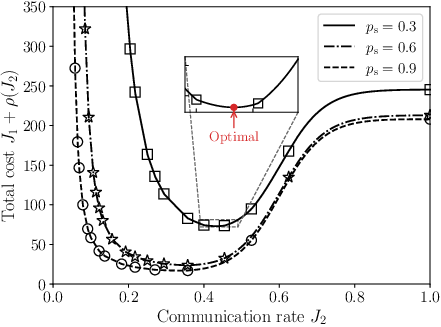
Figure 1: Pareto front of the estimation system for varying communication policies, highlighting threshold-based structure and linear segments.
Further analysis demonstrates that the optimal cost for nonlinear scalarization (e.g., with a sigmoid penalty for communication rate) remains on the Pareto front despite nonconvexity, and the optimal policy can be constructed by combining deterministic threshold policies on an edge.
Theoretical and Practical Implications
The geometric occupancy measure framework unifies the multi-objective average-cost MDP literature by clarifying that stationary policies suffice for Pareto optimality, and that deterministic policies yield all vertices. This result means any strictly increasing objective function—potentially nonlinear and application-specific—can be optimized by selecting suitable mixtures of deterministic policies corresponding to Pareto front vertices.
Practically, this enables efficient enumeration and policy selection for MOMDPs without the necessity of repeated dynamic programming or reinforcement learning for each scalarization. For theoretical research, the connection to convex polytopes opens avenues for advanced MOLP techniques, Carathéodory representations, and policy synthesis so long as the underlying system meets the stated finiteness and unichain conditions.
The methodology also has implications in multi-agent and multi-objective reinforcement learning, semantic communications, and constrained control, where trade-offs must be analyzed exactly and not heuristically. Notably, the fact that nonlinear and even nonconvex operational objectives (as long as they are strictly increasing) can be handled is a contradiction to classical assertions of computational intractability.
Future Directions
Future work can focus on generalizing the approach to infinite state spaces, broader classes of policies (history-dependent, randomized), and relaxing the unichain assumption. Extensions to robust settings, adaptive polytopes under uncertainty, and algorithmic efficiency for high-dimensional objectives are also pertinent. Integration with existing RL approaches for policy mixing and Pareto front exploration is promising for nonconvex, nonstationary environments.
Conclusion
The paper rigorously characterizes the exact Pareto front in average-cost MOMDPs via the geometry of the occupancy measure polytope. Detailing a linear mapping from stationary policies to objective vectors, it asserts—contrary to prevailing beliefs—that the complete Pareto front and optimal solutions for strictly increasing scalarization functions can be obtained via deterministic policies and simple mixtures. These insights have broad theoretical and practical implications for multi-objective optimization in MDPs, enabling efficient, exact policy design for systems with conflicting operational goals.