- The paper demonstrates that CT-to-X-ray knowledge transfer fails to produce robust improvements in X-ray classifiers under rigorous, uncertainty-aware resampling protocols.
- It employs patient-level fixed-split and Monte Carlo resampling to compare plain cross-modal logit KD, late fusion, and ablation-tested architectures.
- The study concludes that complex cross-modality methods are ineffective in scarce data regimes, stressing the need for larger, balanced paired datasets for reliable clinical deployment.
Evidence-Bounded Evaluation of CT-to-X-ray Distillation in Small Paired Cohorts
Introduction
The study "CT-to-X-ray Distillation Under Tiny Paired Cohorts: An Evidence-Bounded Reproducible Pilot Study" (2603.29167) critically examines the potential of leveraging computed tomography (CT) as a training-only supervisory signal to strengthen chest X-ray classification models for binary COVID-19 diagnosis. The research navigates the technically challenging regime where CT is only present during training, but the final deployment path must rely solely on X-ray. The paper emphasizes the methodological rigor necessary for drawing credible conclusions in the context of extremely small, imbalanced patient-level paired cohorts. Instead of proposing a new state-of-the-art model, the authors aim to demarcate the evidential limitations and failure modes that impact the reliability of cross-modality distillation claims in medical imaging.
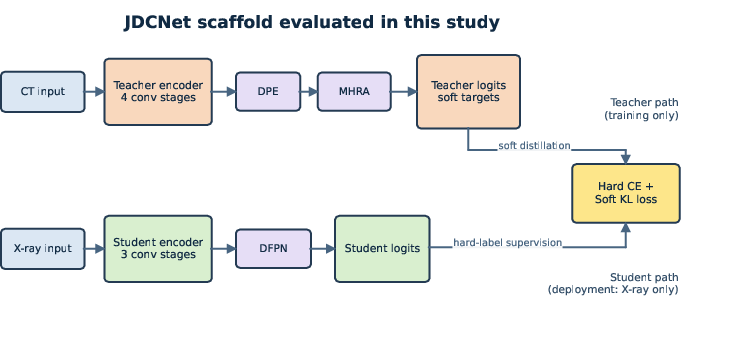
Figure 1: Overview of the executable pilot scaffold evaluated in this study; CT is utilized as training-only supervision for the X-ray student via a teacher--student distillation paradigm, with optional DPE/MHRA/DFPN mechanisms introduced as ablation-tested components.
The core inquiry is whether CT provides additive supervision for improving X-ray classifiers under the restriction that only X-ray data is available during inference. This supervision is formalized as a cross-modality knowledge distillation (KD) problem: a teacher network processes CT images during training while a student network processes X-rays, both sharing binary labels. The deployment model is always X-ray-only, ensuring practical clinical viability.
Experimental protocols are engineered to explicitly isolate and probe five key hypotheses relevant to cross-modality transfer:
- whether plain cross-modal logit KD supplies gains over student-only X-ray training (H1),
- whether those gains are irreducible to same-modality KD (H2),
- whether late fusion at inference retains any advantage (H3),
- whether the inclusion of more sophisticated modules (DPE, MHRA, DFPN) justifies their complexity (H4),
- and whether any observed advantages persist under stricter balance and resampling controls (H5).
To support reproducibility and fair comparison, all cohort construction, model selection, and repeated resampling are performed at the patient level, employing both fixed-split and Monte Carlo resampling regimes.
Baseline Comparisons and Empirical Findings
Initial fixed-split experiments (four validation X-rays, three positive, one negative) suggested that plain cross-modal logit KD outperformed (0.875 accuracy, 0.714 macro-F1) both the student-only baseline and versions incorporating DPE, MHRA, or DFPN. However, the limited size and instability of the split rendered this result speculative.
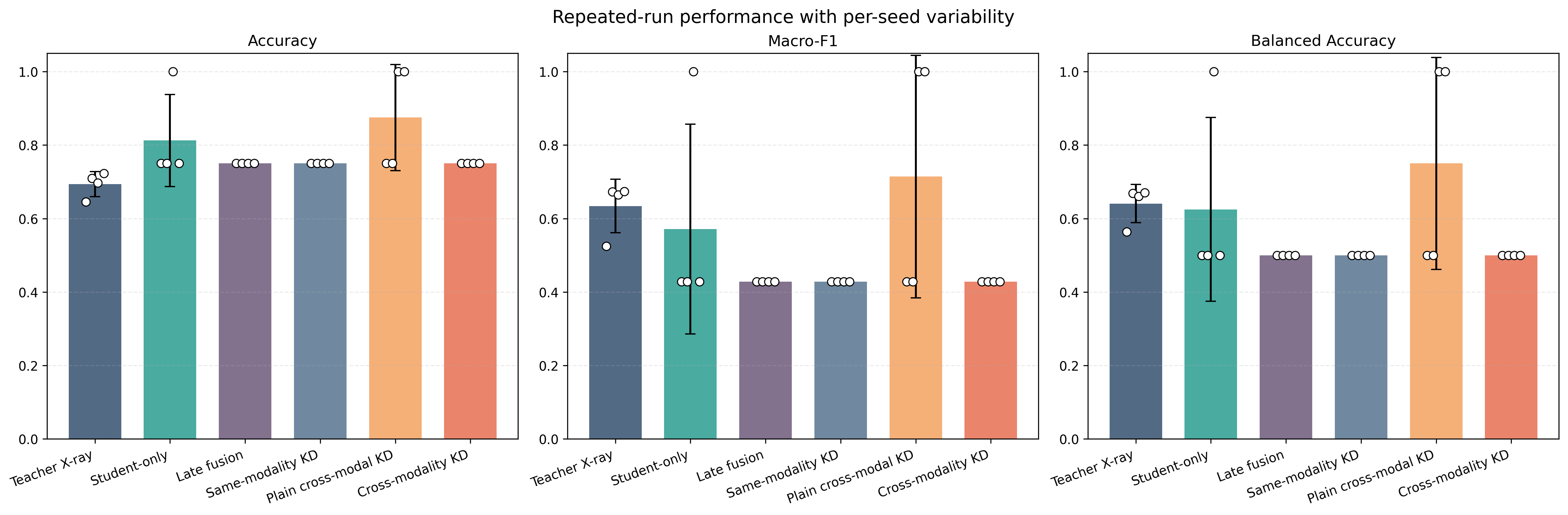
Figure 2: Fixed-split results on the tiny paired X-ray cohort; high per-seed variability and extremely small cohort size undermine the robustness of apparent gains from cross-modal KD.
Upon expanding evaluation to eight patient-level Monte Carlo resamples (each holding out five validation patients), the ranking altered significantly. Late fusion achieved the highest average accuracy (0.885), while same-modality distillation attained the best macro-F1 (0.554) and balanced accuracy (0.660). In contrast, the plain cross-modal KD baseline's mean balanced accuracy collapsed to 0.500 with zero mean specificity, revealing that early apparent advantages did not withstand stricter, uncertainty-aware testing. The integration of attention transfer, feature hints, and the full module stack failed to reclaim the fixed-split cross-modality superiority.
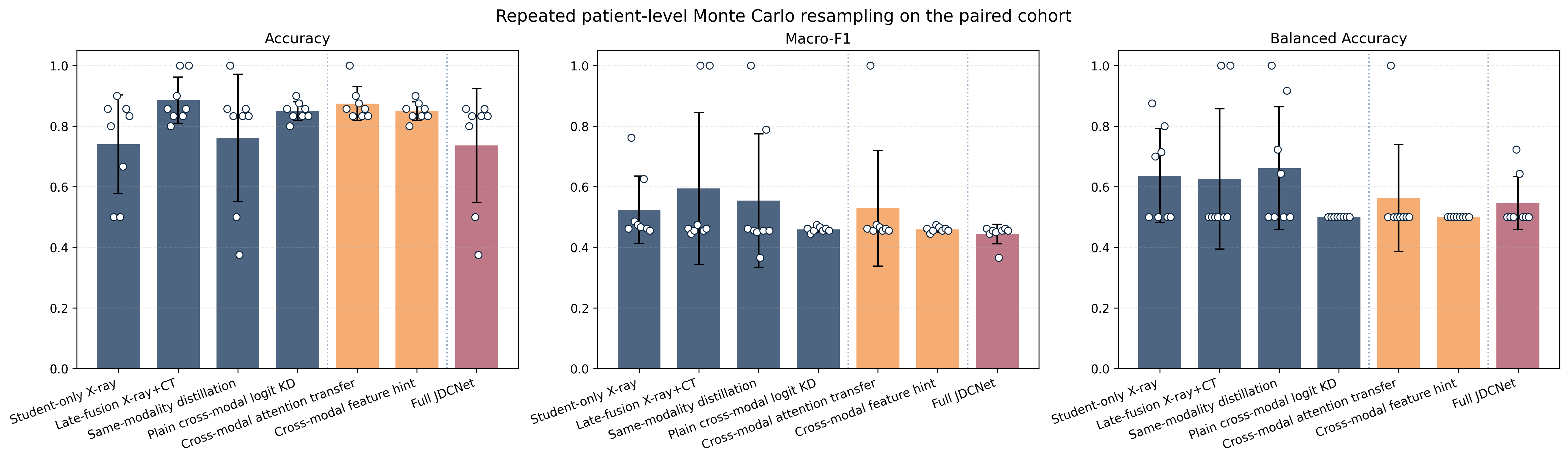
Figure 3: Monte Carlo resampling stability assessment; the best-performing strategies shift, and no cross-modal variant produces a sustained advantage in balanced accuracy or specificity after repeated, fair same-case partitioning.
Hyperparameter and Module Ablations
The researchers performed ablations over distillation temperature and weight, as well as module leave-one-out experiments. Virtually all parameter variations yielded flat or unstable results; predictive outcomes were dominated by severe cohort limitations rather than interaction effects or hyperparameter sensitivity.
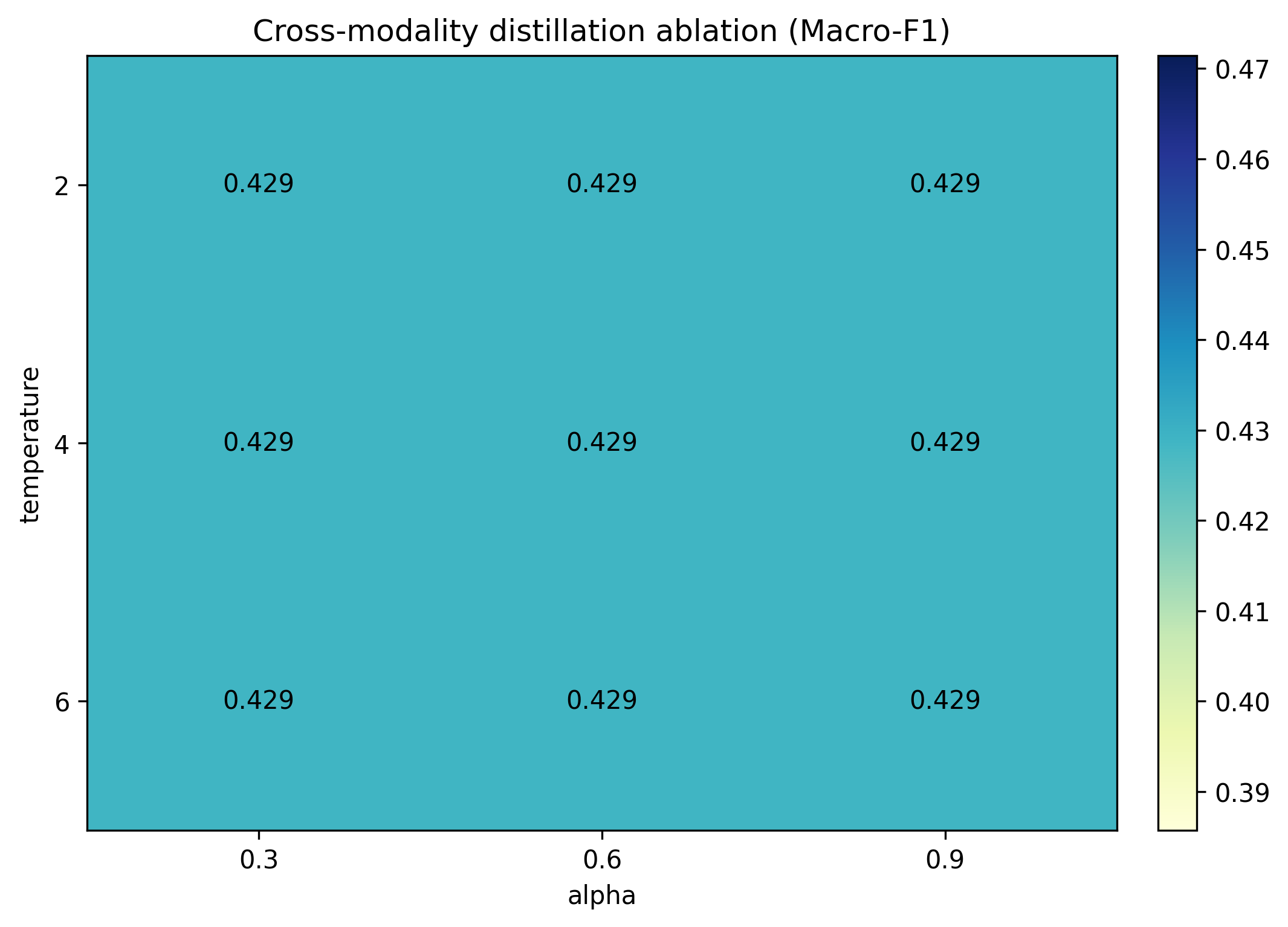
Figure 4: Distillation temperature and weight ablation; the response surface is flat, indicating that the conclusions are driven by data inadequacy rather than optimization details.
Module ablations (DPE, MHRA, DFPN) did not exhibit consistently positive effects. Removal of these modules did not regress performance beneath that of the plain cross-modal KD baseline, and in some cases, removing complexity improved outcomes. These observations further undermine claims that larger or more sophisticated cross-modality architectures are helpful in this scarce data regime.
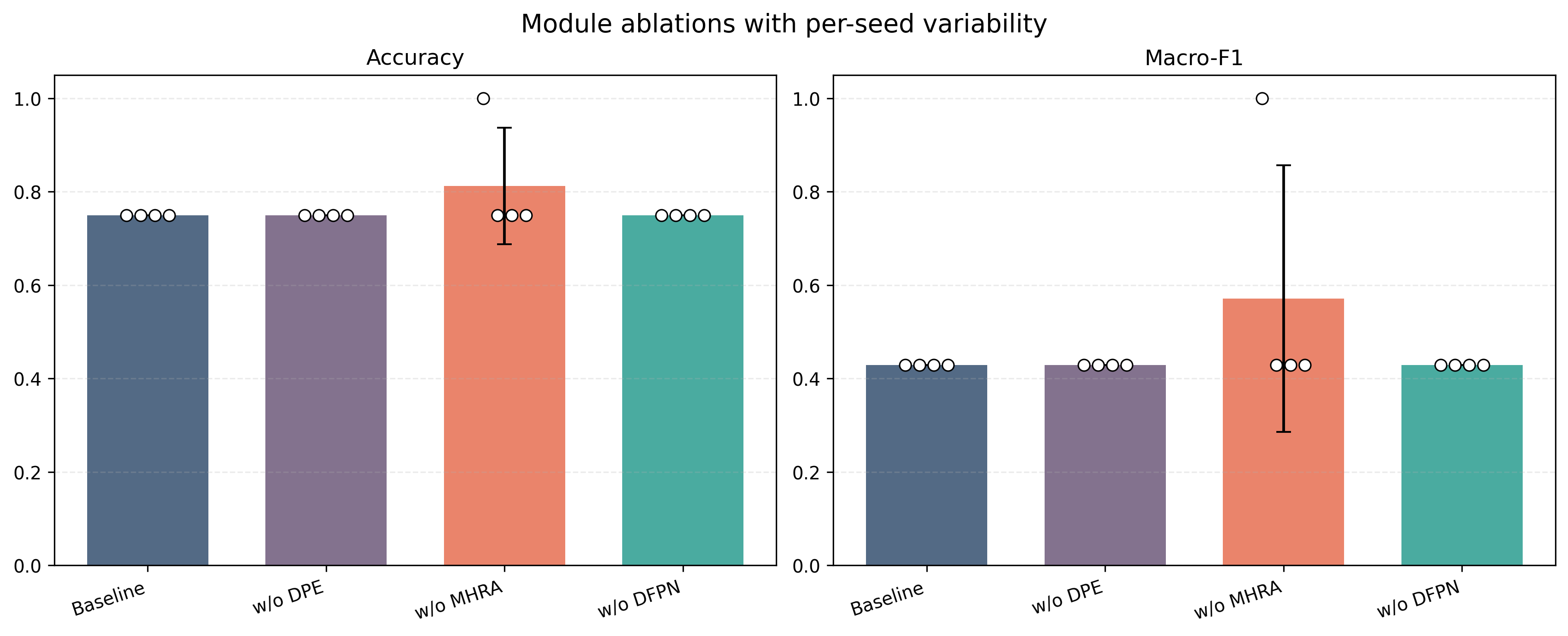
Figure 5: Module ablation repeated-run outcomes; no component of the transfer stack demonstrates robust additive utility given the instability of the paired validation cohort.
Discussion: Evidence Boundaries and Implications
The primary implication is that—given the current real-world availability of tiny paired chest CT/X-ray cohorts—there is no empirical support for strong CT-to-X-ray knowledge transfer claims. The supposed gains from cross-modal KD are highly contingent on accidental fixed splits and evaporate under resampled and imbalance-sensitive controls. Late fusion and same-modality distillation, while not deployable in an X-ray-only setting, serve as crucial methodological controls and often outperform cross-modality transfer under fair patient-level benchmarking.
The study makes explicit that prevalence, class imbalance handling, and careful resampling influence performance as much or more than choice of transfer mechanism or capacity. Thus, positive cross-modality findings in the field should be interpreted skeptically unless evidence includes uncertainty-aware, patient-level, same-case protocols and balanced statistical analyses. The utility of complex transfer architectures is not only untested but, on current evidence, actively contraindicated in this data regime. The presented pilot scaffold provides a foundation and evidential standard by which future research can be evaluated and replicated.
Mechanistically, these results are consistent with the hypothesis that the inductive gap between CT and X-ray—arising from domain shift, heterogeneous appearance statistics, and low sample support—renders teacher-student distillation ineffective without larger, more balanced paired datasets. The study’s negative and fragile results serve as a safeguard, preventing over-interpretation of transient or statistically unreliable improvements in clinical ML pipelines.
Conclusion
This pilot study establishes a conservative, evidence-bounded protocol for evaluating cross-modality distillation from CT to X-ray in the context of small, imbalanced, paired medical imaging cohorts. None of the tested cross-modality mechanisms—including plain logit KD, attention transfer, or feature hints—yield a robust, reproducible deployment advantage once methodological rigor is applied. The findings underscore the necessity for larger and better-balanced paired datasets as well as careful, uncertainty-aware benchmarks for any future claim of effective CT supervision for X-ray classifier improvement. The methodological framework and transparency in failure analysis set a precedent for subsequent research in medical cross-modality learning.

