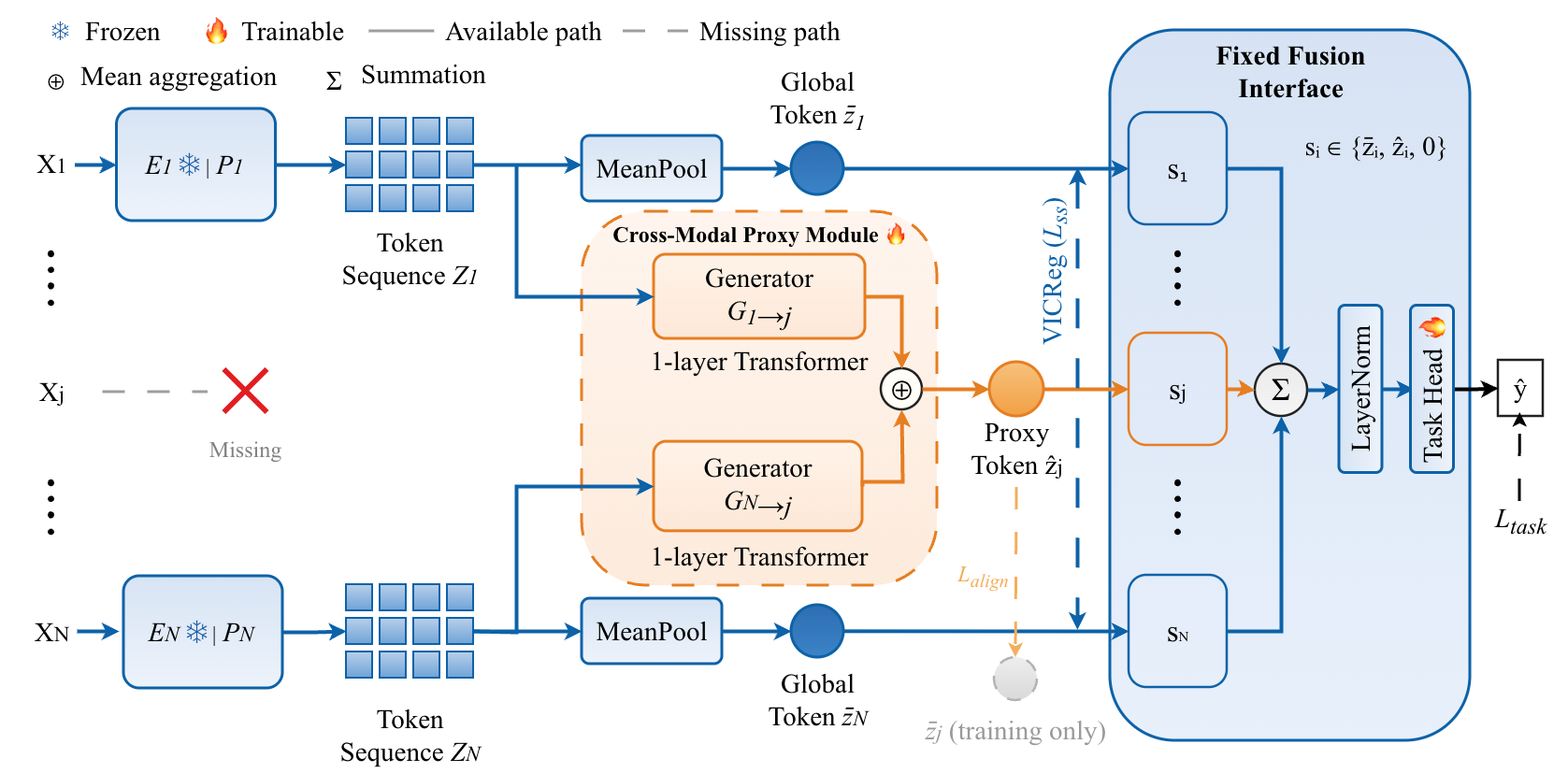
- The paper presents a fixed-slot proxy fusion mechanism that ensures each modality slot is consistently populated, enabling robust multimodal interaction despite missing data.
- It uses directed cross-modal proxy generation and shared-space regularization to align latent representations, improving accuracy by up to 28 percentage points over baselines.
- Empirical results show significant speed gains and robust performance across benchmarks, making COMPASS highly suitable for ubiquitous sensing applications.
Complete Multimodal Fusion via Proxy Tokens and Shared Spaces: The COMPASS Framework
Introduction
COMPASS proposes a principled solution to missing-modality fusion for multimodal sensing, addressing a persistent issue: most prior methods either adapt the fusion process to available modalities or impute missing signals, which leads to inconsistent fusion interfaces between training and inference. This interface mismatch undercuts the robustness of deep fusion models, especially in ubiquitous sensing contexts where modality availability is unreliable.
The key innovation in COMPASS is the enforcement of a fixed, slot-complete, fusion input: each modality slot is always populated, either with a true feature token (when observed) or a proxy token generated from observed modalities (when missing). Directed source-to-target proxy generators and shared-space regularization collectively enforce cross-modal compatibility and task informativeness of these proxies. The resulting architecture ensures that the fusion module receives the same structured input regardless of the missingness pattern, which stabilizes cross-modal interaction and improves test-time robustness.

Figure 1: Comparison of fusion input layouts under different missing-modality strategies: drop (skip), imputation (single-proxy per missing slot), and COMPASS (multi-modal proxy aggregation per slot, preserving fixed fusion interface).
Methodology
Fixed-Slot Proxy-Based Fusion
COMPASS builds upon several architectural commitments:
Training Objectives
COMPASS employs a tri-partite supervision scheme:
- Proxy alignment loss: Encourages each generated proxy to match the real representation of the masked modality.
- Shared-space regularization (VICReg): Structurally aligns latent spaces across modalities without collapsing class discrimination, via joint invariance, variance, and covariance penalties over global tokens.
- Per-proxy discriminative supervision: Makes each proxy individually predictive for the downstream task by applying the task loss over every proxy estimate, not only the fused output.
During training, synthetic missingness is simulated over all possible observed-modality subsets via random masking, exposing generators and fusion to diverse input configurations. This is crucial for robust test-time performance in arbitrary missingness scenarios.
Empirical Results
Human Activity Recognition with Extensive Missingness
On representative benchmarks (MM-Fi, XRF55, OctoNet), COMPASS is evaluated against feature-level fusion baselines and the X-Fi cross-modal Transformer framework across all possible combinations of observed modalities.
Key numerical findings:
- XRF55 (3 modalities, 7 scenarios): COMPASS achieves a mean accuracy of 84.6%, whereas X-Fi obtains 72.1%. In severe missingness (WiFi+RFID observed, mmWave missing), accuracy is 86.3% (COMPASS) vs. 58.1% (X-Fi).
- MM-Fi (4 modalities, 15 scenarios): COMPASS yields 70.6% average accuracy, outperforming X-Fi (62.5%) and baseline fusion (59.7%)—with dual-modality (RGB+LiDAR) accuracy 60.4% (+25.2 pp over X-Fi).
- OctoNet (5 modalities, 31 scenarios): COMPASS dominates single- and dual-modality regimes, with average gains of 28 pp (single) and 11 pp (dual) over X-Fi. It matches or exceeds all baselines in 30 out of 31 configurations.
Representation Geometry Analysis
A central claim is that robust proxy-based fusion requires (i) sufficient cross-modal alignment (so proxies are meaningful) and (ii) preservation of inter-class discriminability post-alignment.
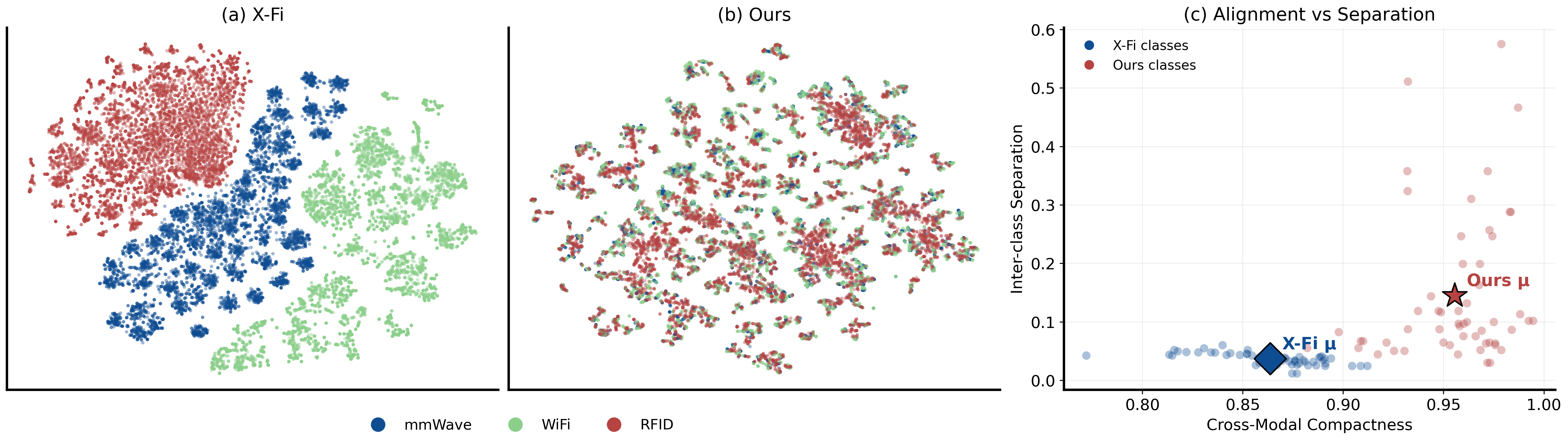
Figure 3: Comparison of representation geometries in the shared space. Left: Baseline cross-modal embeddings are disjoint. Center: COMPASS-aligned embeddings demonstrate reduced modality separation. Right: Quantitative metrics show COMPASS achieves higher cross-modal compactness (intra-class, inter-modality similarity) and increased inter-class separation.
These properties are empirically validated: COMPASS improves both cross-modal compactness and inter-class separation compared to the baseline, thus proxies can be reliably used in any slot without eroding class signal.
Ablations and Efficiency
Proxies (without alignment) already improve over slot zeroing; adding shared-space regularization and explicit alignment substantially increases missing-modality accuracy. The use of parameter-free summation for fusion, enabled by aligned and informative slots, yields significant speedup—COMPASS inference is 1.9–2.6× faster than X-Fi while retaining comparable model size.
Implications and Future Directions
COMPASS demonstrates that modality-complete interface preservation fundamentally advances missing-modality robustness in token-level multimodal fusion. The gains are particularly marked when imputation from strong to weak modalities is most needed.
Implications:
- Practical: Faster and more robust models for ubiquitous sensing in healthcare, smart spaces, and activity monitoring, where sensor failure is common.
- Theoretical: Slot-complete proxy-driven fusion offers a framework for future research into hierarchical or auto-regressive missing-data models, especially as hardware heterogeneity increases.
Notably, however, sum fusion (parameter-free) currently limits expressivity for complex high-level modality interactions; and extremely weak modalities (e.g., RFID) still present a challenge for representation or proxy transfer.
Conclusion
COMPASS offers a scalable, robust paradigm for multimodal fusion under arbitrary missingness, relying on directed proxy generation and latent space regularization to maintain an invariant, slot-complete fusion interface. Empirical results confirm substantial and consistent improvements over prior state-of-the-art across varying benchmarks and missingness patterns. While some limitations remain—such as modest RFID-only performance and potential generalization to regression tasks—COMPASS provides a strong foundation for future innovations in robust ubiquitous sensing and multimodal interaction.