- The paper introduces a cross-modal prompting framework that mitigates modality imbalance and under-optimization in incomplete multi-modal emotion recognition.
- It employs progressive prompt generation with gradient modulation and cross-modal knowledge propagation to selectively integrate audio, text, and video signals.
- Experimental results demonstrate improved, harmonized modality performance across four benchmarks, even under high missing data rates.
Cross-modal Prompting for Balanced Incomplete Multi-modal Emotion Recognition
Problem Statement and Motivation
Incomplete multi-modal emotion recognition (IMER) requires robust integration of audio, text, and video signals under partial modality observability, as real-world applications often face missing data. Existing approaches typically struggle with two interrelated issues: the modality performance gap, where different modalities exhibit disparate discriminative power, and modality under-optimization, where the inclusion of multiple views during fusion degrades the individual performance of certain modalities (particularly non-dominant ones such as video and text).
In baseline strategies, joint training on available modalities can degrade the per-modality accuracy due to inconsistent and noisy representation alignments, especially in scenarios of moderate-to-high missing rates (MR). Empirical findings highlight that standard fusion models frequently fail to transfer complementary cues efficiently, thus limiting the collective benefit of multi-modal learning (Figure 1).
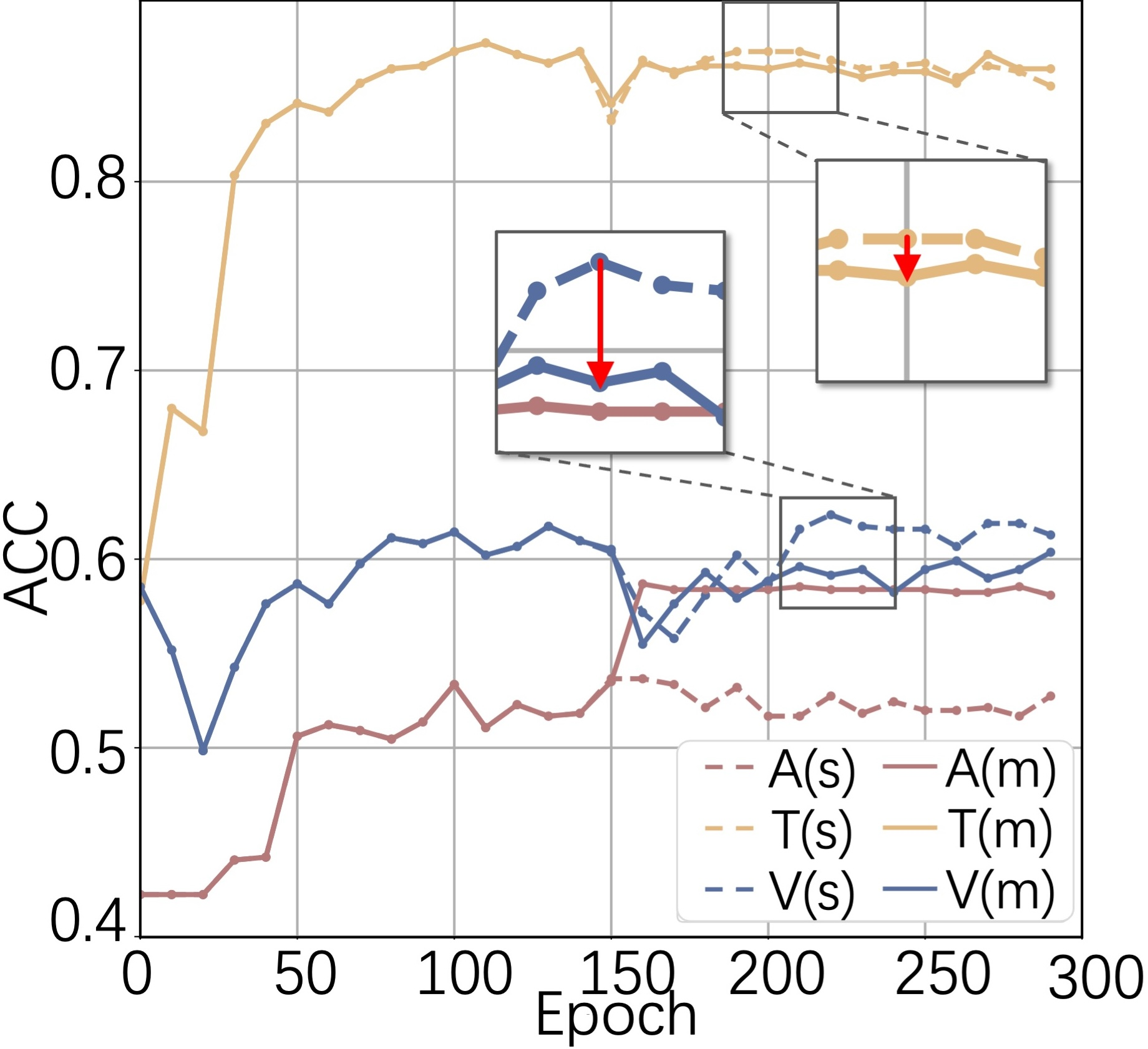
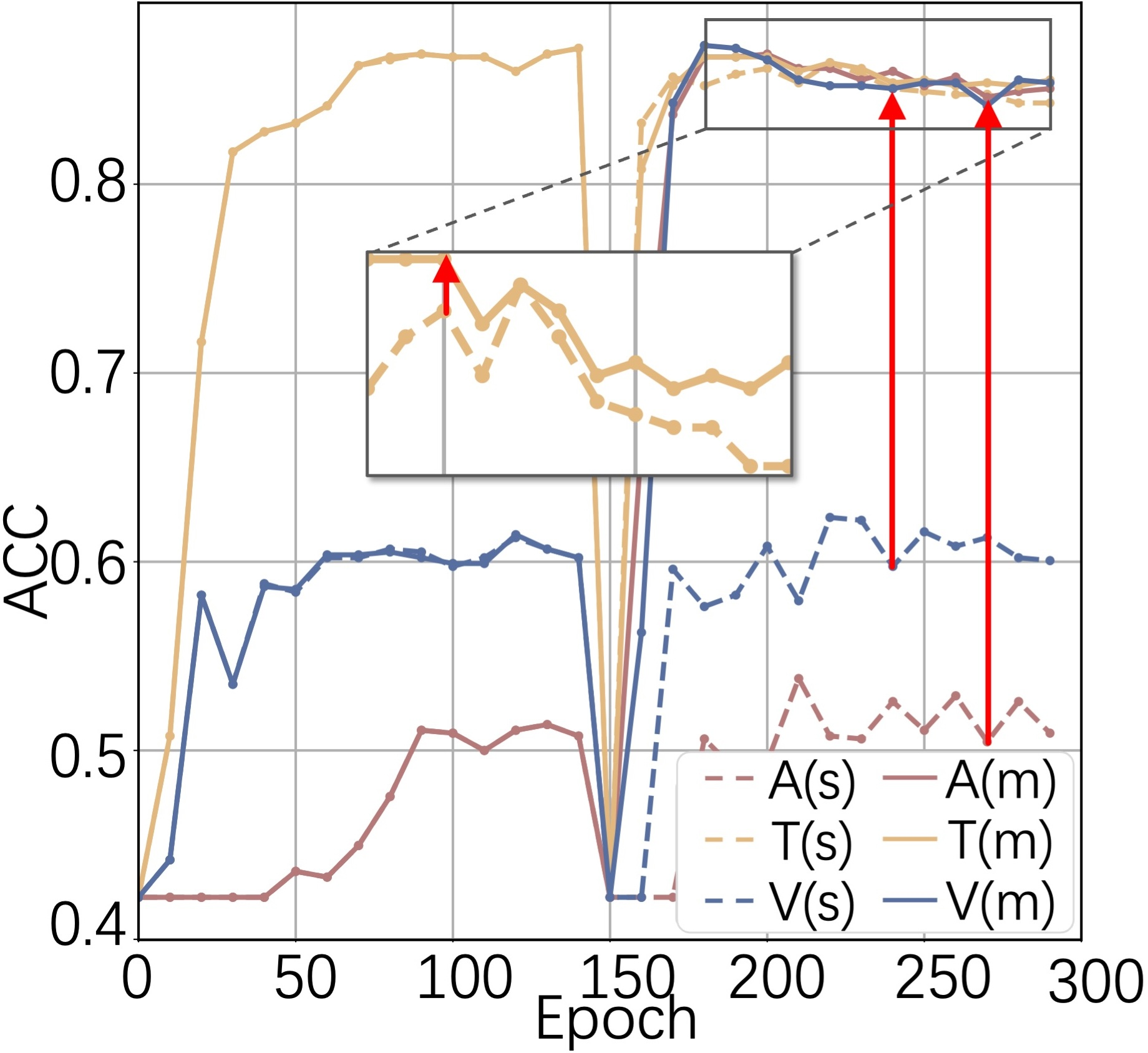
Figure 1: (a) Baseline methods: Video and Text modalities degrade after joint training. (b) Cross-modal prompting: All modalities benefit from multi-modal learning.
The Cross-modal Prompting (ComP) Approach
This paper introduces ComP—a modular framework designed to address modality imbalance and enhance robustness in IMER via information-constrained cross-view communication. The architecture comprises three key components: Prompt Generation (PG), Cross-modal Knowledge Propagation (KP), and a Multi-modal Coordinator (Cr). The interaction between these modules ensures balanced, optimized, and representative feature propagation between modalities, even when the observation is incomplete.
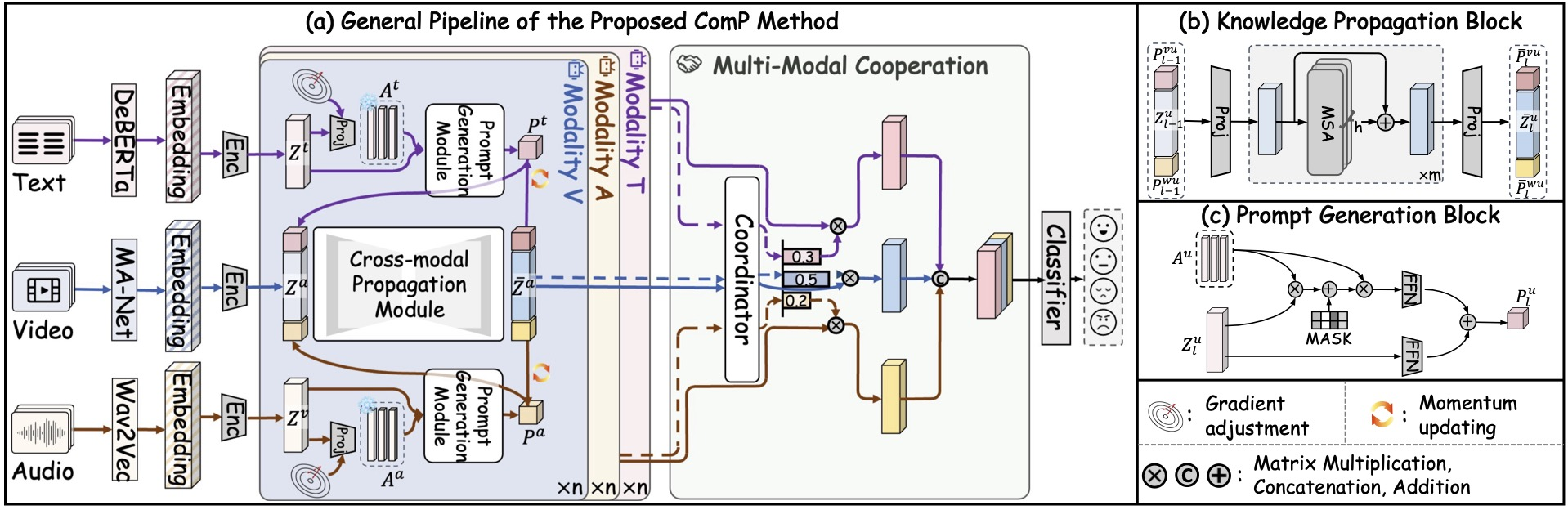
Figure 2: Overview of ComP. Features are first compressed to prompts (PG), passed between modalities (KP), and finally weighted by a cooperation module (Cr).
A crucial innovation is the progressive, prototype-based prompt generation, which compresses the modality-specific features into low-dimensional, consistent prompt vectors, using sample-level gradient modulation to prioritize hard cases. The KP module utilizes these prompts for selective message routing between modalities, amplifying consensus while suppressing spurious or inconsistent signals. The Cr module then adaptively reweighs the contribution of each modality to achieve optimal fusion.
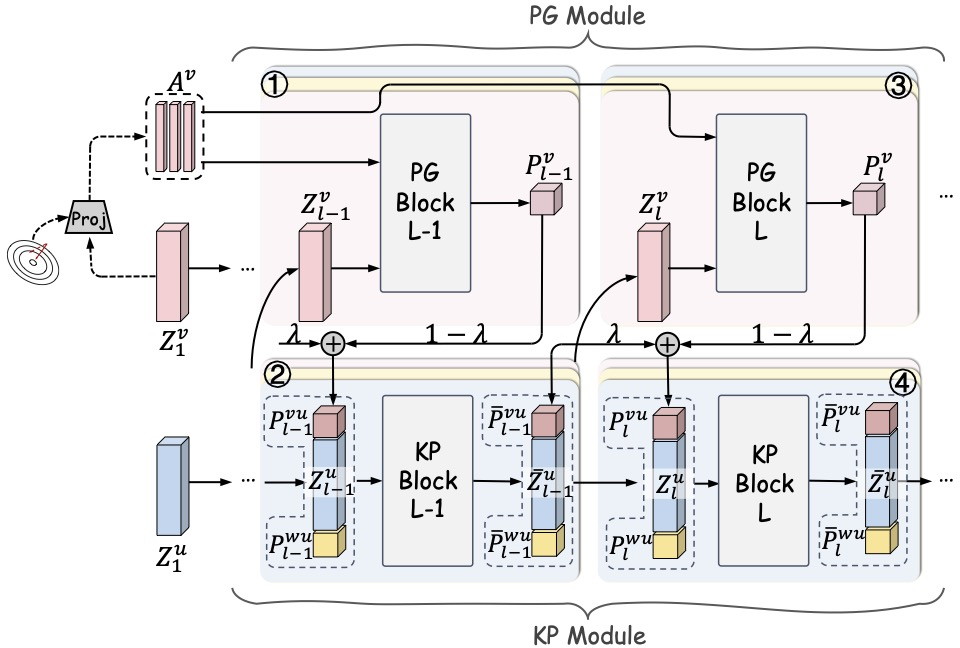
Figure 3: Detailed interactions between Prompt Generation and Knowledge Propagation blocks.
Detailed Methodology
Prompt Generation with Gradient Modulation
Prompt generation is realized via modality-specific multi-layer perceptrons that compress batch-wise features into a set of prototypes. Instead of static prototypes (e.g., k-means), the method introduces a dynamic update with momentum, combining historical cues with fresh, sample-focused gradients. The relative prediction error per instance modulates the prototype update rate, ensuring that informative and hard-to-classify samples are adequately represented.
Cross-modal Knowledge Propagation
In the KP stage, each modality receives not only its propagated state but also the prompts from other views. The concatenated representation undergoes dimension reduction, attention-based enhancement, and is then split back into updated modality features and external prompts. This process is recursively executed, with missing instances seamlessly reconstructed through cross-view imputation.
Multi-modal Coordinator and Adaptive Fusion
The coordinator module leverages a learned MLP to generate softmax weights for each modality on a per-sample basis, enabling dynamic and context-aware fusion. This ensures that, after cross-modal prompting, all modalities maintain strong discriminative capacity and the intrinsic heterogeneity of multi-modal signals is respected.
Experimental Results
ComP is evaluated on four benchmarks (CMU-MOSI, CMU-MOSEI, IEMOCAPFour, IEMOCAPSix) subjected to systematic synthetic missing rates (MR from 0.1 to 0.7). The method surpasses seven SOTA baselines under all regimes. For example, on IEMOCAPFour at MR=0.1, ComP achieves 80.66% ACC versus 78.48% (SDR-GNN), maintaining dominance up to high missing rates with a notably slower degradation over MR increase (see Table 1, Table 2 in paper).
Representative t-SNE visualizations confirm enhanced class discriminability post-KP and after final fusion, with feature embeddings clustering cleanly according to sentiment polarity.
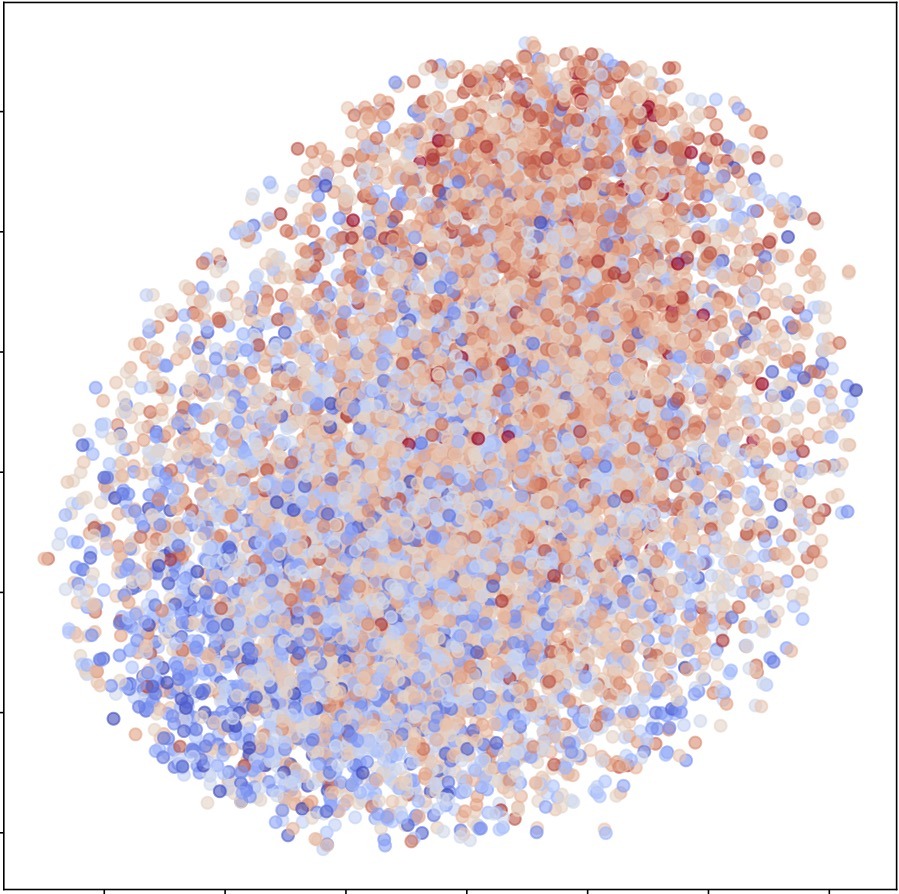
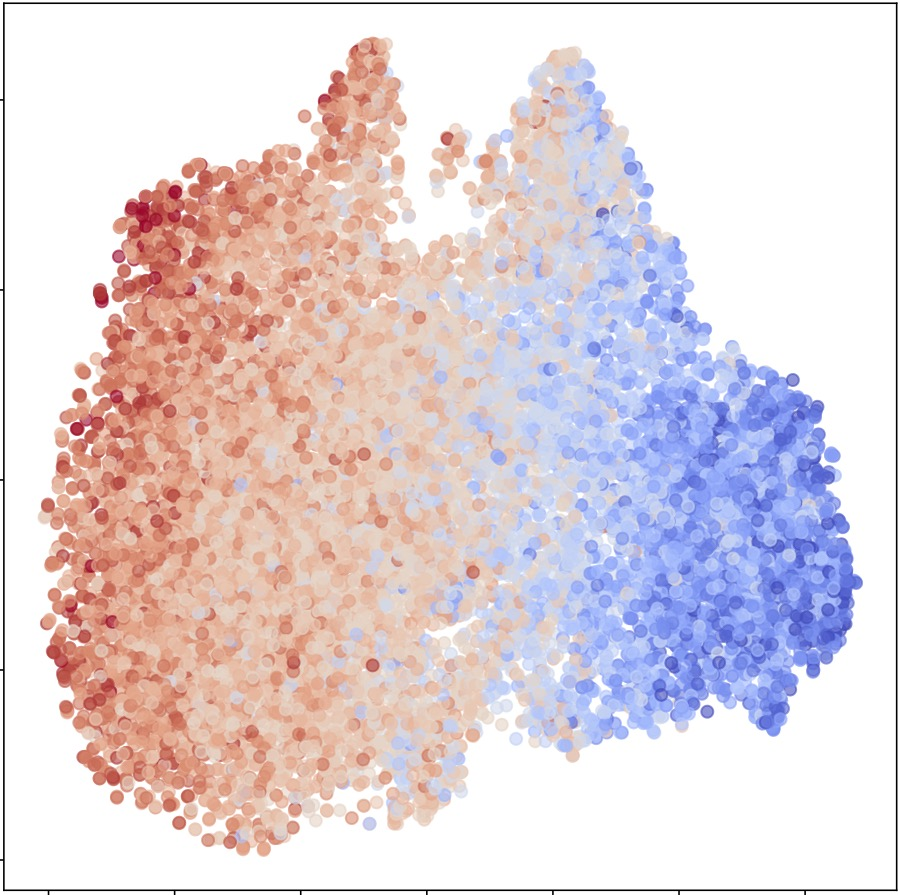

Figure 4: T-SNE visualization showing improved separation of positive and negative emotion classes after cross-modal knowledge propagation and final fusion.
Ablation studies isolate the contribution of PG, KP, and Cr, confirming that removal of any module degrades performance by up to 7% ACC/F1 at moderate and high MR. Notably, gradient modulation exhibits the largest impact under datasets with high inter-sample difficulty variability.
Modality-balance studies demonstrate that ComP not only raises overall accuracy but also harmonizes the discriminative power of weaker modalities (e.g., video in IEMOCAP), as evidenced by the synchronized accuracy trajectories post-stage 2 training.
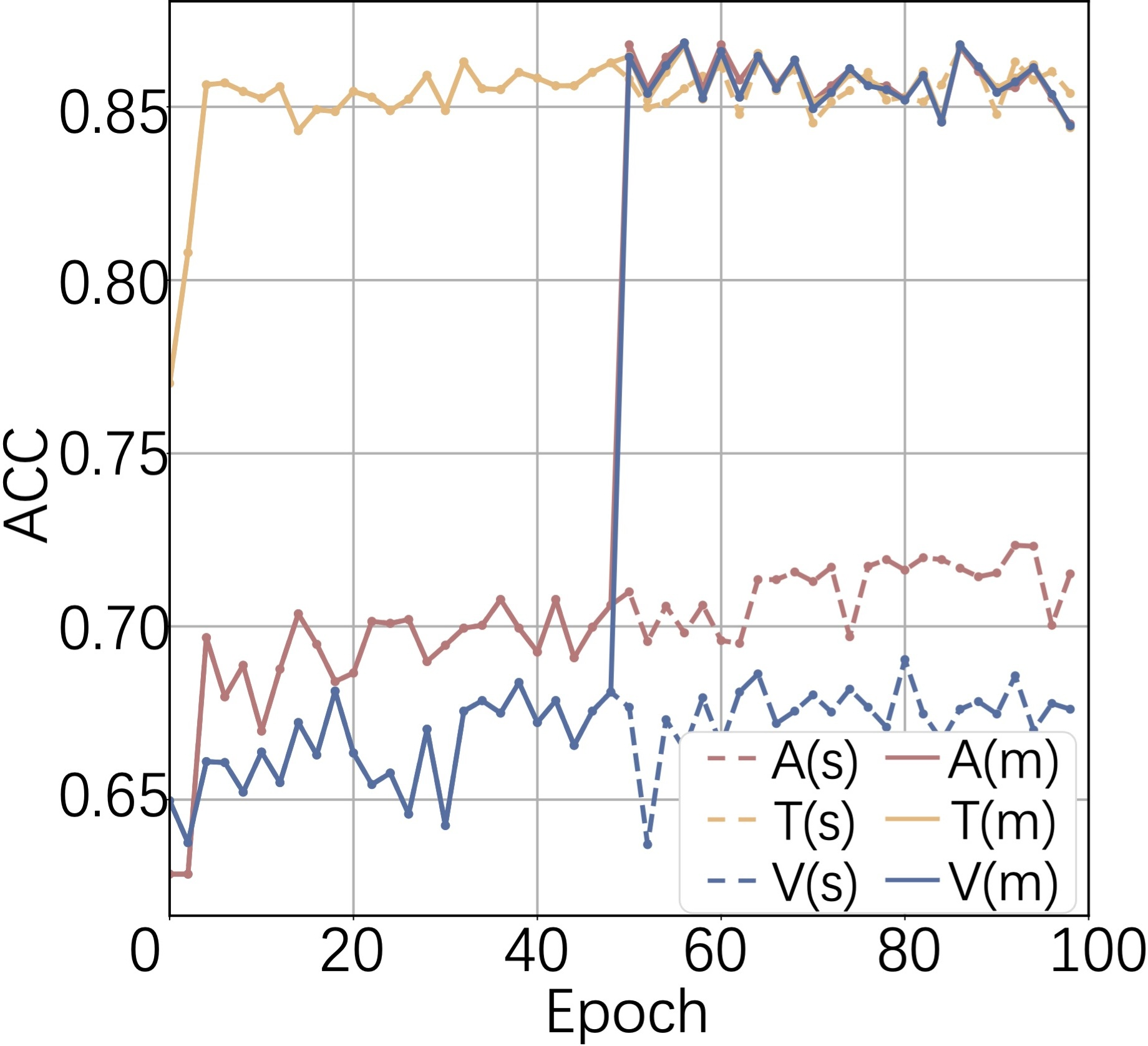
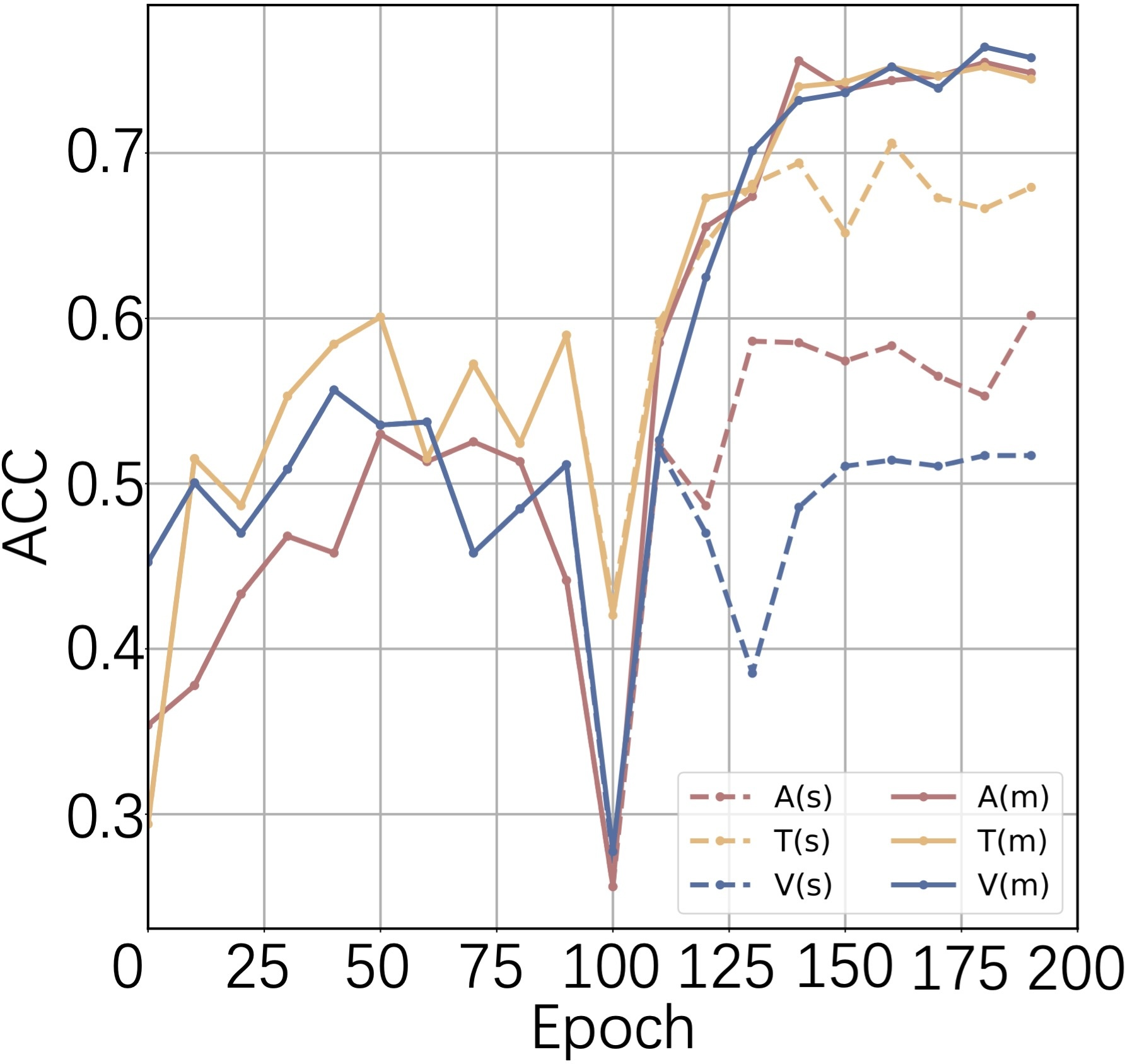
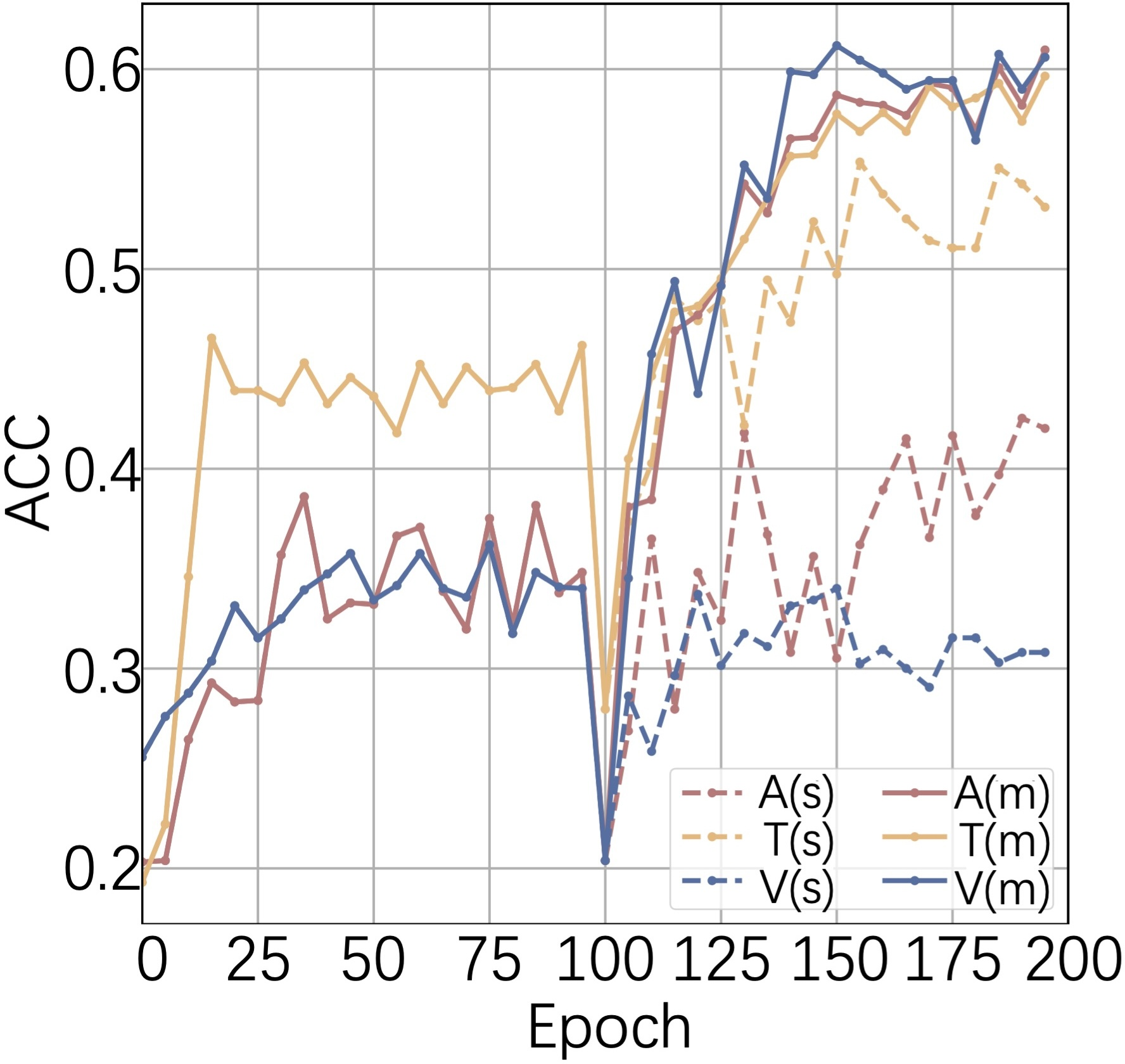
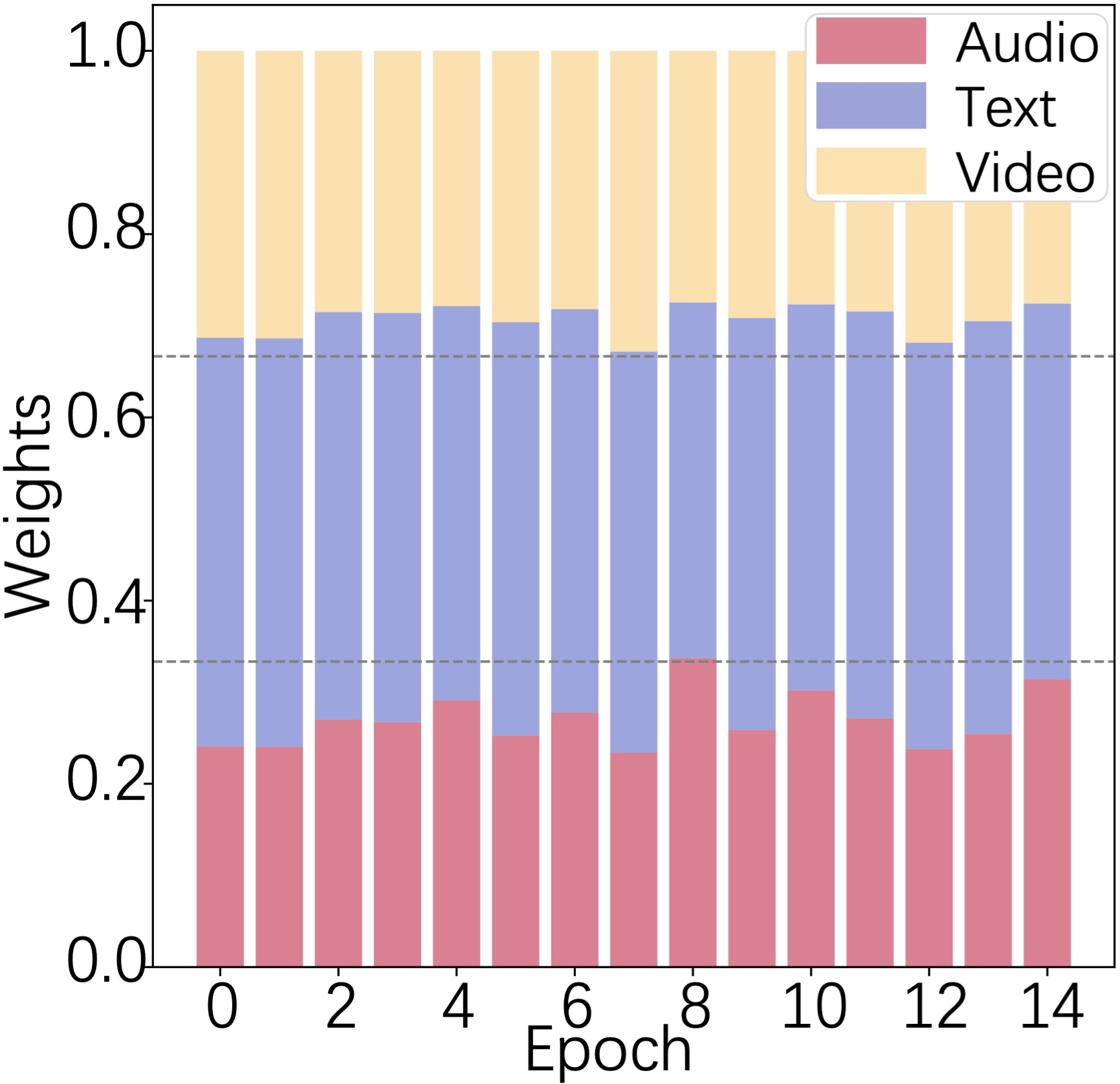
Figure 5: (a-c) Modality-specific accuracies over epochs on three datasets, showing an immediate jump in accuracy during cooperative training. (d) Coordinator weights across modalities for sequential utterances.
Theoretical and Practical Implications
The cross-modal prompting mechanism operationalizes efficient consensus reinforcement, overcoming both the performance gap and under-optimization seen in vanilla multi-modal fusion. By prioritizing hard instances and selectively harmonizing views, ComP advances the state-of-the-art in robust, balanced IMER under challenging missingness.
From a practical standpoint, the model is readily extensible to other multi-modal fusion tasks where data incompleteness and modality heterogeneity are bottlenecks (e.g., medical diagnostics, multi-sensor surveillance). The progressive prompt learning with gradient modulation could be integrated with large-scale pre-trained multi-modal models, enhancing generalization in low-resource or noisy regimes.
On the theoretical front, ComP provides empirical support for the importance of intermediate, information-bounded cross-modal representations. The architecture decouples feature compression, cross-view agreement, and learned weighting, paving the way for future research into modular, interpretable fusion architectures and information-theoretic analyses in incomplete multi-modal learning.
Conclusion
ComP enables robust, balanced, and scalable multi-modal emotion recognition under incomplete data conditions, setting new benchmarks across multiple datasets and missing regimes. The integration of progressive prompt generation, cross-modal propagation, and adaptive fusion systematically alleviates both modality dominance and underutilization. These contributions establish a new paradigm for consensus-driven, incomplete multi-modal learning.
(2512.11239)

