- The paper presents Jagle, a scalable pipeline for assembling a 9.2M-instance Japanese multimodal dataset to enhance VLM performance on Japanese tasks.
- It details a three-phase methodology combining QA generation, OCR extraction, and synthetic text rendering to ensure robust image-text alignment.
- Results show over a 20-point macro-average gain on Japanese tasks and improved English performance via cross-lingual data mixtures.
Jagle: A Large-Scale Japanese Multimodal Post-Training Dataset for Vision-LLMs
Motivation and Context
The construction of robust Vision-LLMs (VLMs) hinges critically on access to large-scale, high-quality multimodal instruction datasets. While English has benefited from abundant VQA and captioning datasets, other languages—including Japanese—face a pronounced resource shortage, restricting the development of proficient non-English VLMs. Most existing approaches for building large-scale multimodal datasets focus on format unification and curation of pre-existing datasets, which is infeasible for Japanese due to the fragmented and limited coverage in available resources. "Jagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-LLMs" (2604.02048) addresses this bottleneck by designing a scalable, generalizable pipeline for assembling and generating diverse multimodal resources from heterogeneous Japanese data sources.
Dataset Construction Methodology
Jagle's design follows a three-phase pipeline: category selection, source aggregation, and QA sample generation. The category schema extends the Eagle2 taxonomy, targeting five essential categories: General VQA, Chart/Table, Captioning/Knowledge, OCR QA, and Naive OCR. Notably, the pipeline is architected to be extendable to other low-resource languages by minimizing reliance on extant VQA datasets.
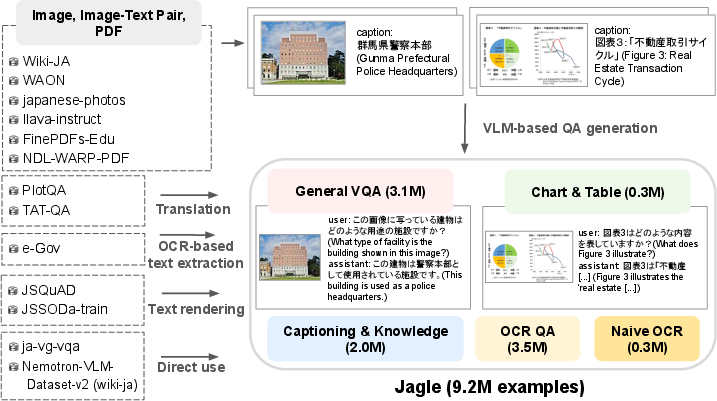
Figure 1: The Jagle pipeline assembles heterogenous data and applies VLM-based QA generation, translation, text rendering, and OCR extraction to produce instructional multimodal samples.
Data sources span web-crawled image-text pairs (e.g., WAON, Wiki-ja), PDF corpora (NDL WARP), and government documents, with careful heuristics for domain targeting. For QA-pair synthesis, the work leverages: (1) VLM-based QA generation (using high-performing, permissively-licensed Qwen3-VL), (2) OCR-based extraction (e.g., PaddleOCR-VL for document content), (3) text rendering (synthetic text-image creation from Japanese QA datasets), and (4) translation pipelines with careful parallelization of rendered content to preserve modality alignment.
Diversity is enforced through controlled sampling from visually redundant sources. The resulting dataset comprises 9.2M instances covering a broad array of image types and domains, distributed across 17 subsets.
Jagle Dataset Analysis
Jagle's coverage and diversity are quantitatively characterized by four primary axes: sample count, unique images, answer tokens, and conversational turns.
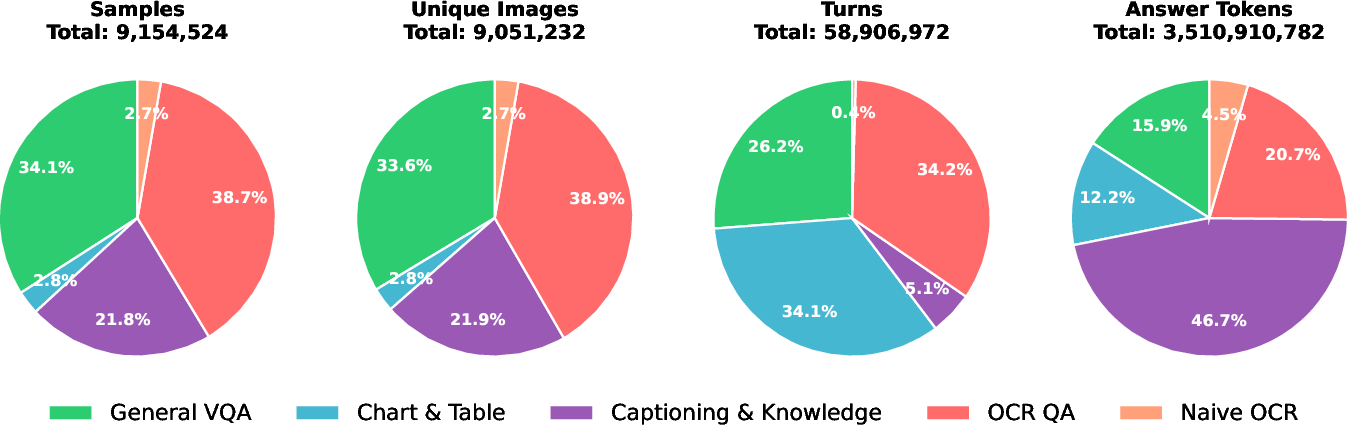
Figure 2: Category-weighted distribution across samples, unique images, turns, and answer tokens in Jagle.
General VQA, OCR QA, and Captioning/Knowledge dominate in sample counts, with Captioning/Knowledge comprising a disproportionately high count of answer tokens due to long-form caption tasks. Chart/Table and Naive OCR exhibit high sample homogeneity, as evidenced by cluster analyses in embedding space.
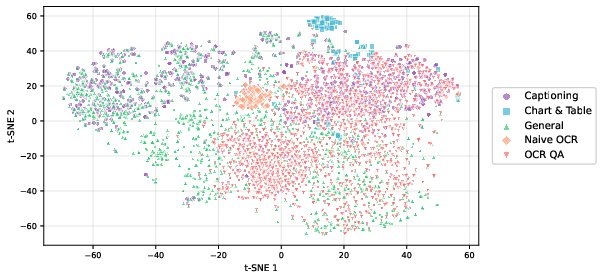
Figure 3: t-SNE projections of SigLIP2 image embeddings show visually coherent clusters for Chart/Table and Naive OCR samples, indicating strong intra-category consistency.
Qualitative examination confirms Jagle's broad visual and semantic coverage, including natural photographs, complex charts, scanned documents, and slide material.
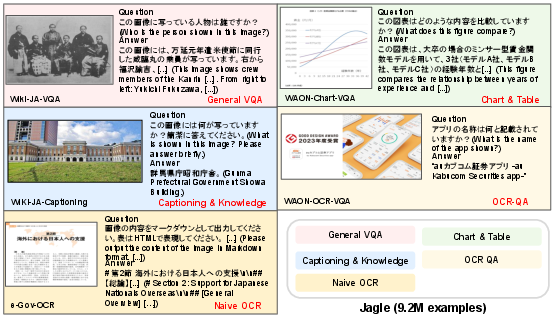
Figure 4: Representative VQA samples illustrate Jagle's coverage—ranging from natural scenes and document layouts to complex structured diagrams.
Experimental Study
Training and Model Configuration
For empirical evaluation, a 2.2B-parameter Japanese VLM is trained under three regimes: Jagle only, FineVision (English) only, and a Jagle+FineVision mixed setting. Training utilizes Qwen3-1.7B-Instruct as LLM, SigLIP2 as image encoder, and a two-layer MLP as the multimodal projector, with all parameters tuned end-to-end. OpenAI Harmony format templates and dynamic tiling enable handling of high-resolution imagery.
Benchmarks and Protocol
The model is benchmarked on 10 Japanese and 10 English VQA/captioning datasets, including Heron-Bench, JA-VLM-Bench-In-the-Wild, JGraphQA, JDocQA, BusinessSlideVQA (Japanese); AI2D, ChartQA, DocVQA, OK-VQA, MMMU (English). For comparison, Qwen3-VL-2B-Instruct and InternVL3.5-2B serve as open-weight baselines.
Results
Strong empirical findings are documented:
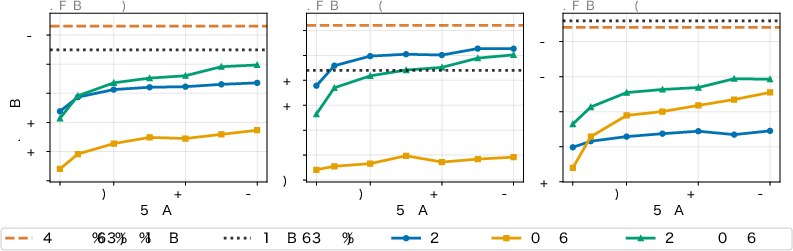
Per-task training dynamics for all benchmarks exhibit consistent trends: Japanese tasks are maximally enhanced by Jagle; English tasks benefit from cross-lingual data mixture.
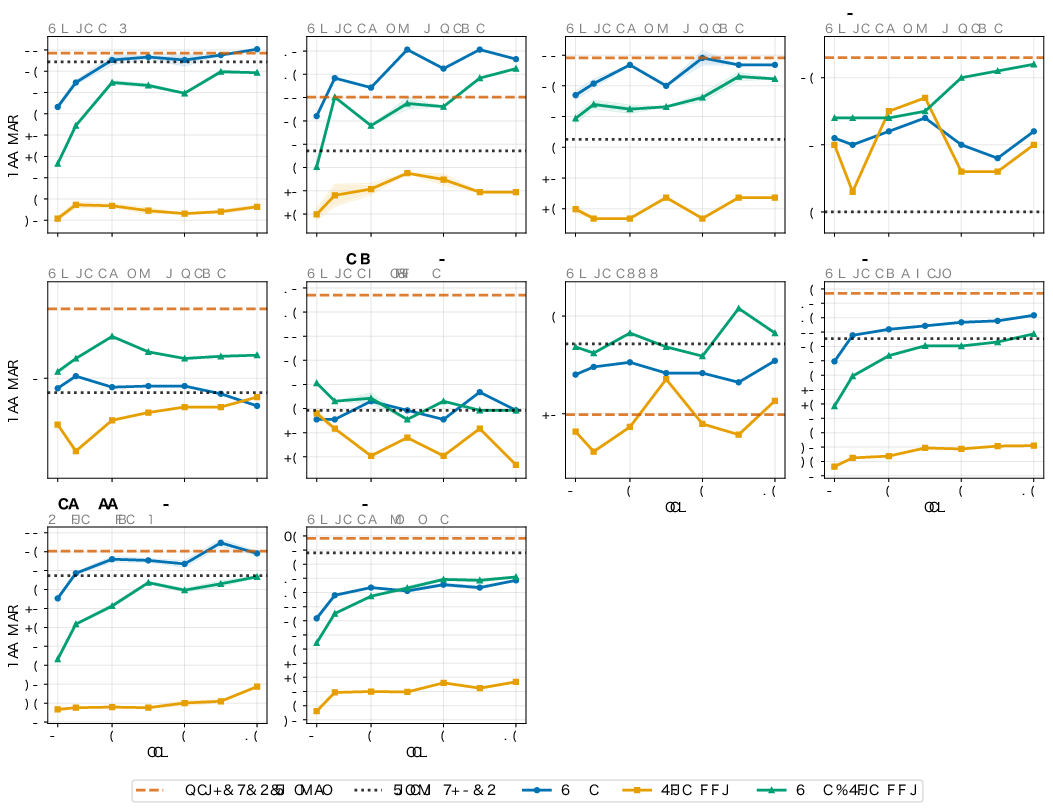
Figure 6: Per-task Japanese benchmark learning curves under all data conditions show pronounced benefits from Jagle.
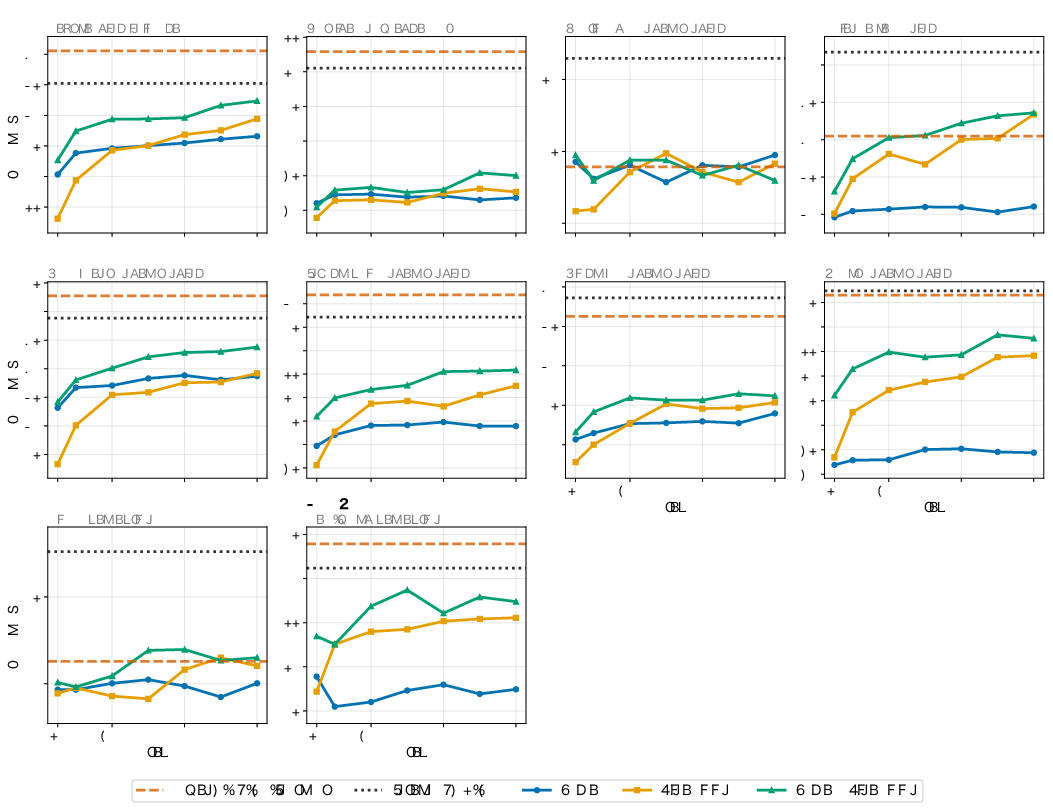
Figure 7: Per-task English benchmark learning curves show mixture-driven lifting over English-only baselines.
Analysis of model efficiency reveals that—despite consuming an order of magnitude less data than Qwen3-VL—performance continues to improve without clear saturation, indicating ample room for further gains with extended training.
Implications, Limitations, and Future Directions
Jagle establishes a generalizable methodology for assembling massive, instruction-style multimodal datasets in non-English settings—lowering the barrier for robust multilingual VLM research. Its empirical demonstration that diverse Japanese data not only advances Japanese VQA/captioning but can improve English benchmarks has direct implications for understanding cross-lingual transfer and the architecture of post-training pipelines.
Three limitations are highlighted:
- Dataset mixture proportions are fixed, not systematically optimized. Prior research indicates significant sensitivity to mixture ratios, motivating future work on adaptive blending schedules.
- Synthetic QA generation inherits VLM limitations—hallucinations and mode collapse. Addressing these via large-scale filtering or human adjudication could further raise quality.
- Jagle omits categories such as Grounding/Counting, Math, Science, and Text-only. Inclusion is critical for building generalist VLMs and remains an open direction.
Jagle's open release of data, models, and code will catalyze further advance in Japanese and broader multilingual VL research.
Conclusion
Jagle constitutes the largest, most comprehensive Japanese multimodal post-training dataset to date, assembled via a scalable, extensible pipeline. Its impact is established both by strong empirical gains on Japanese VQA/captioning tasks with small model sizes and by evidence that Japanese data can augment English task capability upon mixture. These findings suggest a blueprint for future multilingual VLM post-training efforts, with implications for both resource creation and cross-lingual transfer in vision-language understanding.
Reference: "Jagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-LLMs" (2604.02048)