- The paper demonstrates that linguistic representations in self-supervised speech models emerge hierarchically, with local features in early layers and syntactic dependencies in deeper layers.
- It employs extensive probing methods on six Dutch models, contrasting Wav2Vec2 and HuBERT variants to reveal sequential versus parallel learning dynamics.
- Iterative refinement via pseudo-label abstraction in HuBERT-I2 significantly enhances the simultaneous emergence of higher-level linguistic structures.
Tracking the Emergence of Linguistic Structure in Self-Supervised Speech Models
Overview
"Tracking the emergence of linguistic structure in self-supervised models learning from speech" (2604.02043) provides a systematic representational analysis of how multiple linguistic structures emerge within state-of-the-art self-supervised speech models (S3Ms) during training. The authors examine six Wav2Vec2 and HuBERT architectures trained on 831 hours of Dutch speech, probing for nine levels of linguistic abstraction ranging from low-level acoustics to high-level syntactic dependencies. The analysis centers on how these structures are allocated across model layers and emerges during training, with comparative attention to model architectural and objective variations.
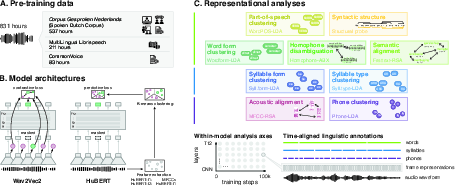
Figure 1: Model and analysis pipeline: six Dutch S3Ms, architectural comparisons, and a probing suite across linguistic structures.
Model Architectures and Training Paradigm
The study contrasts two major SSL speech representation learning frameworks: Wav2Vec2 (contrastive, frame-level) and HuBERT (iterative predictive, pseudo-label-based). Both are configured as base models with 7 CNN layers and 12 Transformer layers, differing minimally in their span of training objectives.
- Wav2Vec2 utilizes a contrastive loss over the output of the feature encoder.
- HuBERT is analyzed in two variants: I1 (first iteration, using MFCC-based k-means labels) and I2 (second iteration, labels from I1 hidden states).
All models are strictly monolingual (Dutch) and probe learning with a matched non-speech baseline (Wav2Vec2 trained on 900 hours of AudioSet).
Probing Methodology and Linguistic Structures
Internal representations are evaluated using a diverse suite of probes targeting:
- Categorical/cluster structures: phones, syllable forms and types, word identity, and POS (via LDA-based silhouette scores).
- Relational/geometric structures: acoustic (MFCC) and semantic (Fasttext) spaces (RSA).
- Relational context distinction: ABX discriminability for homophones.
- Combinatoric dependency: structural probes for syntactic tree alignment (UUAS).
Analyses explore both layerwise organization and trajectory across intermediate checkpoints.
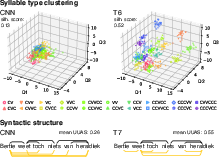
Figure 2: Visualizations for probing: LDA clustering of syllables and dependency links for syntactic structures.
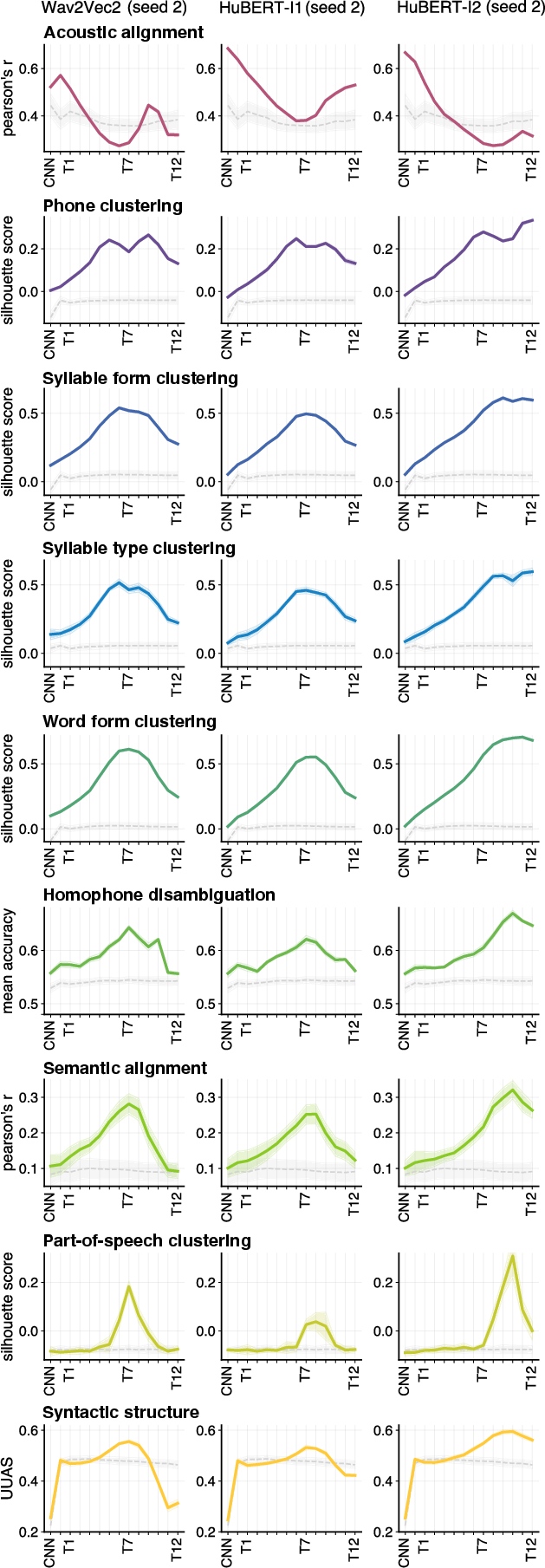
Layerwise Allocation of Linguistic Structure
The principal outcome is that internal linguistic representations in S3Ms obey a hierarchy closely aligned with timescale and abstraction:
A critical contrast appears between HuBERT-I2 and the other models: iterative refinement (using labels from abstracted hidden states) yields greater parallelism, with multiple higher-level structures co-peaking in the final layers—unlike the more sequential stratification in Wav2Vec2 and HuBERT-I1.
Training Dynamics and Learning Trajectories
The time course of structure emergence is quantified both via trajectories of probe scores and parametric sigmoid curve fits. For Wav2Vec2 and HuBERT-I1:
- Acoustic encoding saturates in the earliest training epochs (<10k steps).
- Phonetic, syllable, lexical, and POS representations climb in performance after 10k steps, peaking before 100k.
- Syntactic structure (as per dependency UUAS) lags, reaching parity with the non-speech baseline only after 25k-50k steps, and continues to benefit most from extended training (to 200k steps).
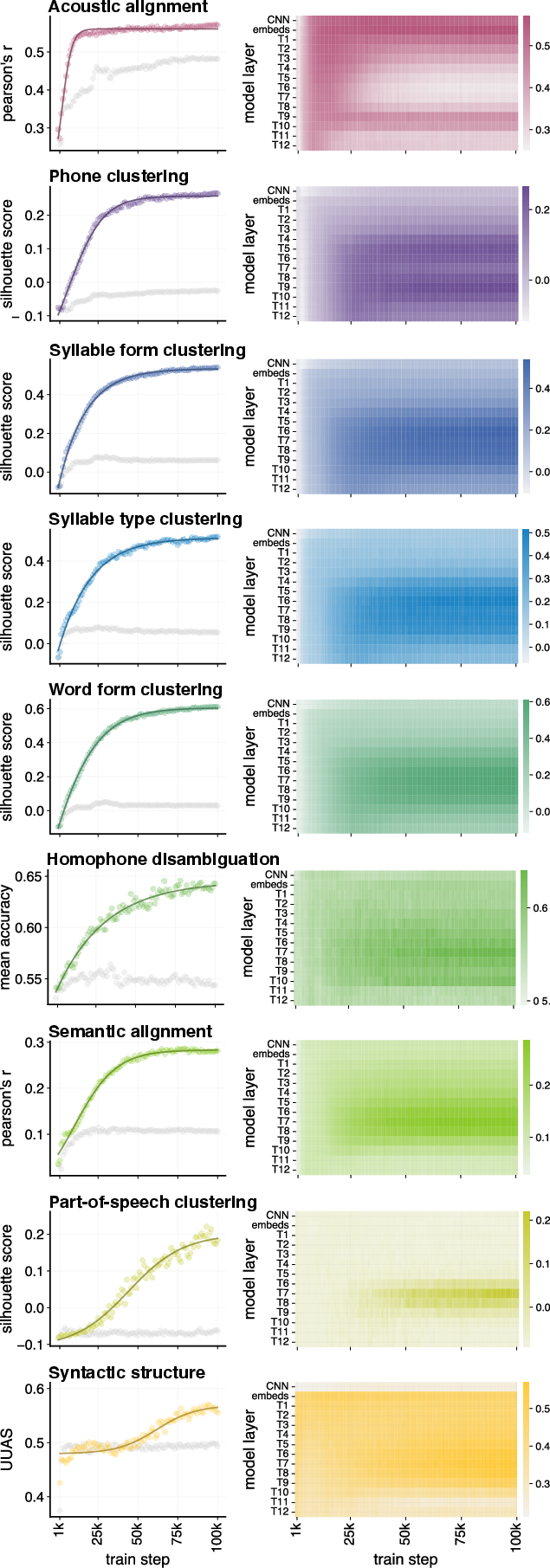
Figure 4: Wav2Vec2 learning curves: best-layer probe scores across checkpoints, showing lag of syntactic probes relative to others.
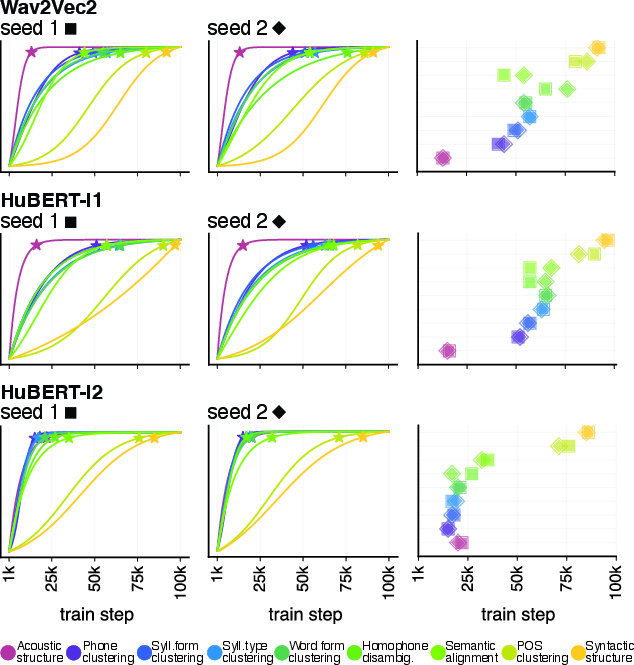
Figure 5: Parametric learning trajectory fits for all probes; stars indicate steps where 95\% of final probe performance is reached, highlighting the sequential onset of structure.
A unique finding is the parallelization of learning curves in HuBERT-I2: the emergence of various structures is less sequential, indicating that prediction based on more abstract pseudo-labels supports simultaneous acquisition of multi-level representations.
Control Analyses and Probing Robustness
Control analyses demonstrate that the emergent syntactic representations are not artifacts of sequential structure but reflect true dependency information: alignment scores are superior for true dependency parses compared to linear-only structures, and this pattern is inverted in the non-speech model.
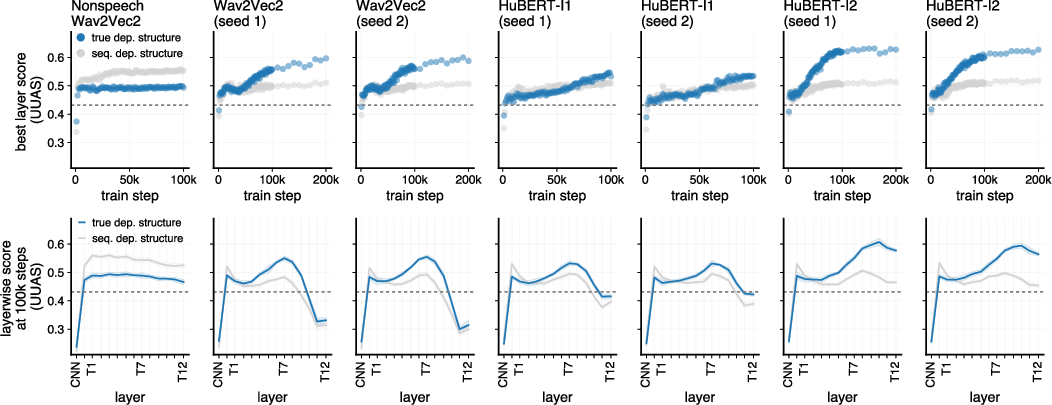
Figure 6: Syntactic probe control: Speech S3Ms more accurately reflect true dependency parses than sequential baselines; the pattern reverses in non-speech models.
Implications and Theoretical Consequences
- On Speech SSL Model Design: The findings emphasize that pretext objective and pseudo-label abstraction dramatically influence not just the presence but also the organization and simultaneity of emergent linguistic information. This is critical for architectures tasked with downstream interpretable or structured output.
- On Language Acquisition Modeling: The observed gradual, sequential emergence of hierarchical structures—acoustics → phonetics/lexicon → syntax—is reminiscent of incremental accounts in child language development but contrasts with more parallel models. The effect of training data scale and objective on the timescales for emergence may inform computational models of acquisition.
- On Probing and Representation Analysis: The study highlights the necessity of control models (e.g., non-speech baselines) and the inadequacy of simple probe classification accuracy as a standalone interpretability metric.
- On Training Efficiency: Most probe scores plateau early (<100k steps, ∼80 epochs over the corpus), except for syntax, which shows persistent improvement, suggesting diminishing returns for other structures with prolonged SSL training.
Future Developments
- The contrast in parallel vs. sequential emergence under distinct objectives suggests that optimal multi-task or transfer models should consider pseudo-label abstraction and target timescale explicitly.
- Bridging architectural findings with neurocognitive models (e.g., distributed hierarchical encoding in human auditory cortex [keshishian2023]) remains an open area.
- Further causal interventions (e.g., controlling for or ablating word-form encoding) are needed to verify dependencies between linguistic abstraction stages.
- Expansion to cross-linguistic or polyglot settings may clarify the role of language-specific pretraining and typological variance.
Conclusion
This work sets a methodological foundation for tracking the representational emergence of linguistic structure in self-supervised speech models by combining dense checkpoint probing, nonlinear learning analysis, and detailed comparative procedure design. The results reveal a nontrivial architecture- and objective-dependent progression from local/acoustic to global/syntactic information, with pseudo-label abstraction in HuBERT driving greater temporal and representational parallelism. These insights offer concrete guidance for both engineering robust S3Ms and for cognitive theorizing about the nature of hierarchical language learning in both humans and artificial systems.
(2604.02043)