- The paper demonstrates that coupling transfer learning with deep ensembles significantly reduces epistemic uncertainty, resulting in robust classification of bipolar disorder and schizophrenia.
- The paper finds that performance gains plateau at an ensemble size of 10 models, offering practical guidelines for reducing computational costs while maintaining high ROC-AUC scores.
- The paper reveals that transfer learning anchors models in a shared loss landscape basin, unlike randomly initialized models, which explains the improved consistency and generalizability.
Analysis of Deep Ensemble and Transfer Learning Synergies for Psychiatric MRI Classification
Introduction
This paper provides a rigorous analysis of the mechanisms by which deep ensemble (DE) strategies combined with transfer learning (TL) elevate the classification performance and robustness of deep learning models in the diagnosis of bipolar disorder (BD) and schizophrenia (SCZ) from structural MRI data. The work is motivated by prior evidence that TL and DE both outperform conventional machine learning and randomly initialized deep learning (RI-DL) baselines in psychiatric imaging, while the practical and theoretical reasons underpinning these gains have not been clearly elucidated. The study systematically investigates the reduction of epistemic uncertainty introduced by random parameter initialization in single-subject classification and establishes methodical guidelines for ensemble sizing and the generalizability properties conferred by TL.
Methodology
The experimental framework is centered on two psychiatric disorder discrimination tasks: BD vs. healthy controls and SCZ vs. healthy controls. The data is harmonized across multiple, rigorously stratified public neuroimaging datasets, with site-agnostic test splits guaranteeing that model improvement is not attributable to overfitting on imaging site-specific features. Voxel-based morphometry (VBM) gray matter maps are utilized as model input modalities. All neural architectures are derived from DenseNet-121 backbones to ensure parameter count consistency.
Two principal strategies are contrasted:
- Randomly Initialized Deep Learning (RI-DL): Models trained from scratch, capturing the effect of stochastic weight initialization on performance and prediction variance.
- Transfer Learning (TL): Models initialized with weights learned from pre-training on large, age-prediction contrastively-learned healthy brain MRI datasets, then fine-tuned on BD or SCZ classification.
Both strategies are further deployed in deep ensemble (DE) configurations, aggregating T independently trained models' predictions to mitigate epistemic uncertainty.
A core experimental variable is the number of independently trained models (T) averaged in the DE. Systematic bootstrapped evaluations reveal that for both BD and SCZ classification, ROC-AUC performance gains rapidly plateau at T=10, beyond which additional models yield diminishing returns in both accuracy and stability.
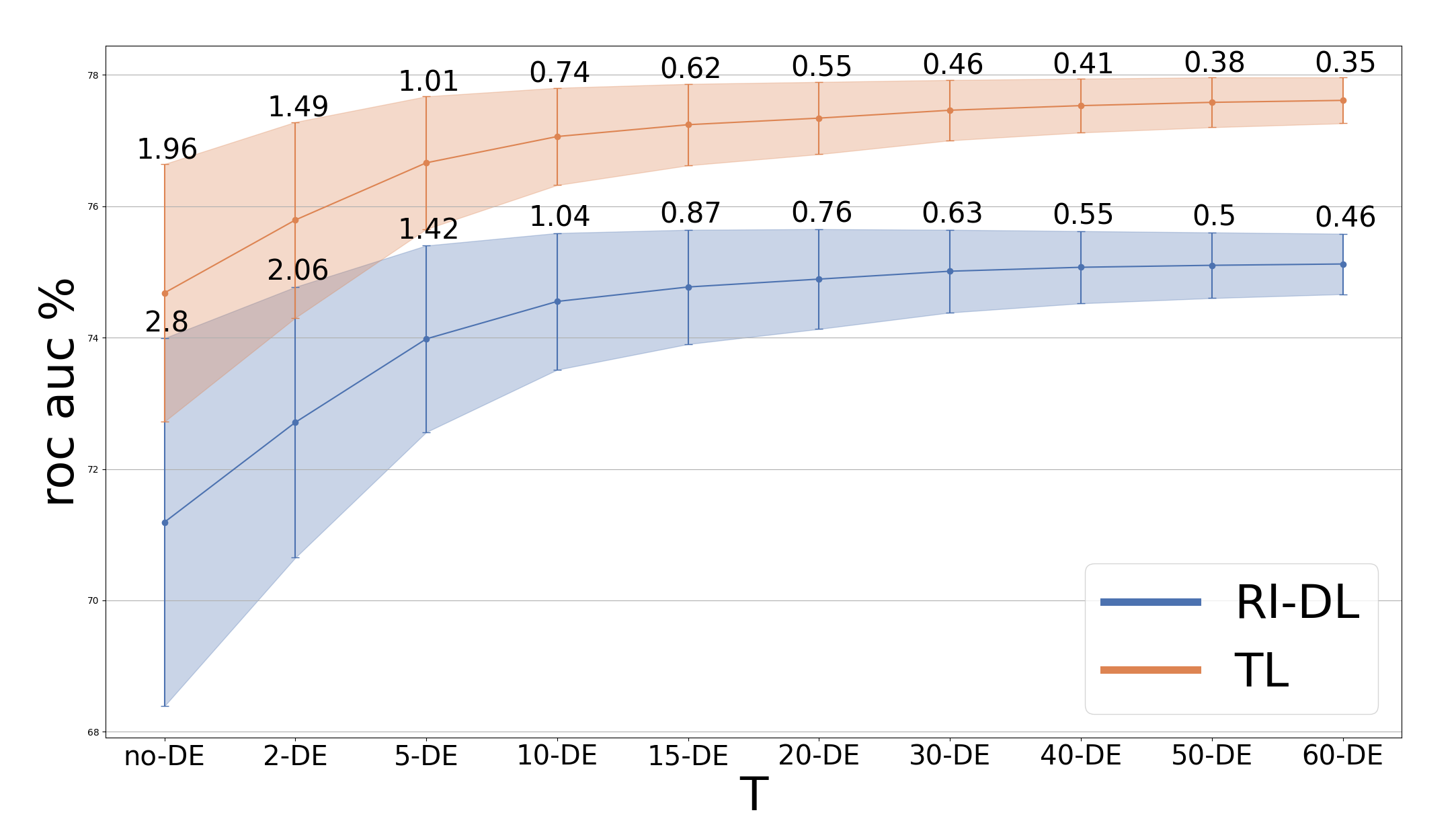
Figure 1: ROC-AUC increases with the number of DE models for BD; variance reduces with higher T and TL+DE outperforms RI-DL+DE.
This plateau informs practical model deployment, significantly reducing computational requirements without sacrificing classification efficacy. Critically, through empirical quantification, TL+DE achieves ROC-AUC improvements over TL alone and shows consistently lower prediction variance across bootstrap runs. The effect is especially pronounced in BD classification, with TL+DE (at T=40) yielding a 2.85% ROC-AUC gain over TL without DE, whereas in SCZ, the additional benefit is more marginal—suggesting disorder-dependent sensitivity. Notably, RI-DL+DE can approach TL+DE performance in SCZ but remains inferior in BD.
Transfer Learning and Loss Landscape Geometry
To unravel why TL confers superior generalization and model consistency, the loss landscape geometry of trained models is interrogated via linear weight-space interpolation between pairs of trained networks. Following established precedents in neural loss surface analysis, ROC-AUC is tracked along interpolation paths between final-epoch and best-epoch model checkpoints for both TL and RI-DL models.
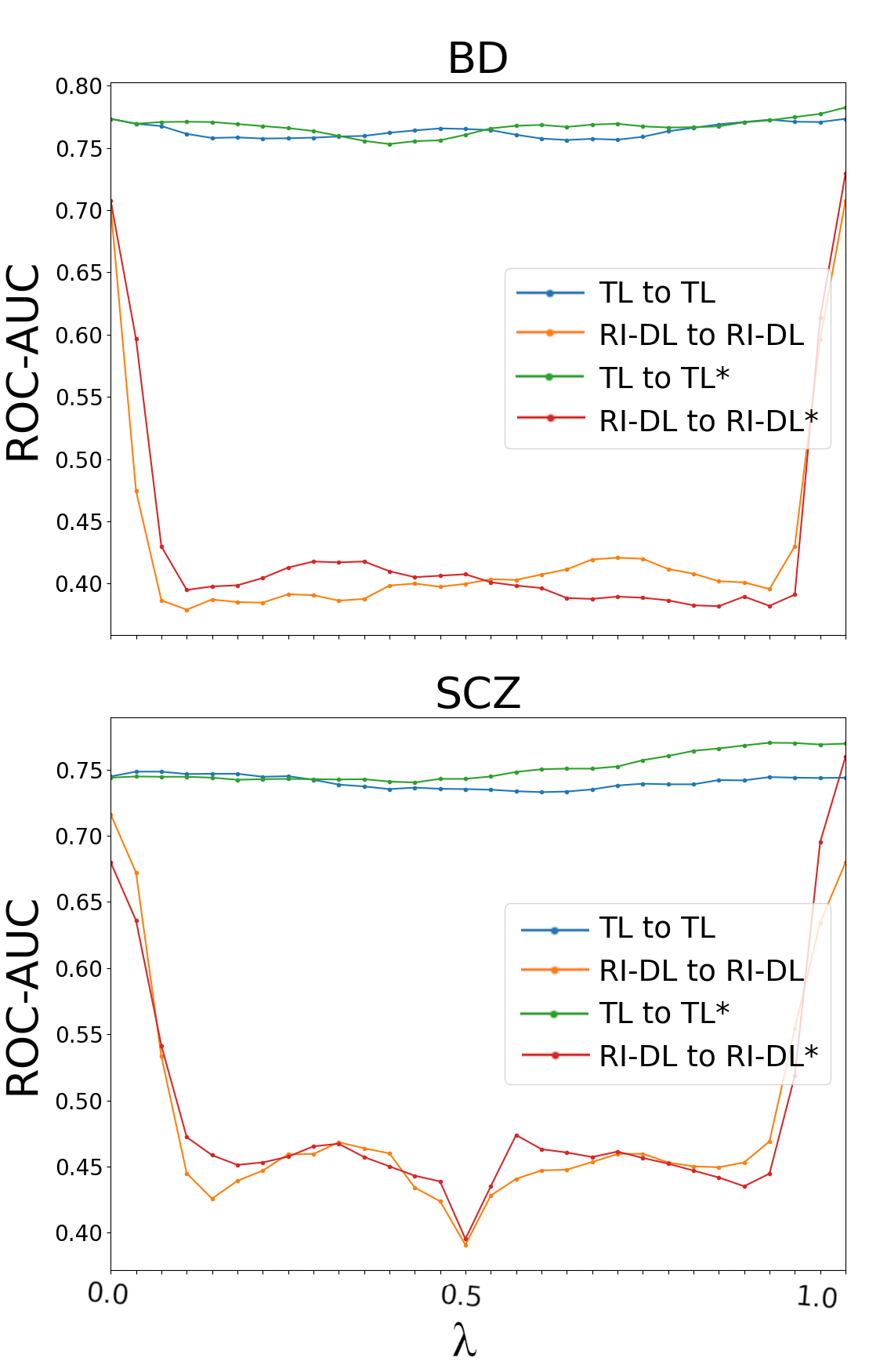
Figure 2: Linear interpolation between TL and RI-DL model pairs reveals barriers in RI-DL but smooth paths in TL, indicating shared optima.
The findings are unequivocal: TL models consistently reside within the same basin of the loss landscape, as performance metrics remain essentially flat along all linear interpolations between TL model pairs. In contrast, RI-DL linear interpolation curves demonstrate sharp drops in ROC-AUC in the neighborhood of convex combinations, strong evidence that randomly initialized models tend to converge to disparate local minima. This loss surface analysis not only explains the reduced inter-model variability observed for TL but also indicates why DE aggregation is most advantageous for RI-DL (where independent minima are being averaged) yet still delivers robustification for TL (where model diversity is lower).
Implications and Future Directions
The study substantiates that TL, particularly with contrastive learning and age-aware pre-training, is an effective regularizer for convolutional architectures in neuropsychiatric MRI analysis, anchoring solutions within a robust, shared minimum of the loss landscape. This, in tandem with moderate-sized DEs (as few as ten models), delivers high diagnostic accuracy with reduced prediction volatility—a critical feature for clinical application. The disorder-specific nature of the gain, with greater benefits in BD than SCZ, is postulated to stem from variation in population-level neuroanatomical heterogeneity and the alignment between pre-training and downstream task labels. Specifically, the accelerated brain aging signature commonly noted in SCZ, but less so in BD, may allow even RI-DL to uncover robust discriminative axes directly linked to pre-training features.
The linear interpolation barrier analysis offers a paradigm for evaluating model generalizability and reliability in transfer learning pipelines. The finding that TL convergence maintains models in a single basin even with extended fine-tuning epochs supports earlier theoretical work on the nature of minima in large-scale neural network landscapes. Future work might dissect the interplay between TL strategies (other than age-aware contrastive), varying backbone architectures, and psychiatric subtypes, and explore the causal features learned during pre-training that confer generalizability to specific disorders.
Conclusion
This paper provides a technically rigorous examination of deep ensemble and transfer learning synergies in psychiatric neuroimaging classification. By isolating the reduction in epistemic uncertainty from ensemble sizing, and relating TL's benefit to loss landscape basins, the research delivers actionable recommendations: utilize TL-initialized models aggregated over ten independent instantiations for practical, robust single-subject diagnosis. The geometric analysis clarifies that the improved consistency and performance of TL stems from constraining models to a shared solution space during fine-tuning, a property not matched by randomly initialized networks. These findings advance both theoretical understanding and clinical applicability for AI-based psychiatric imaging.